 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuyang Li
Condition-Aware Neural Network for Controlled Image Generation
Apr 01, 2024
We present Condition-Aware Neural Network (CAN), a new method for adding control to image generative models. In parallel to prior conditional control methods, CAN controls the image generation process by dynamically manipulating the weight of the neural network. This is achieved by introducing a condition-aware weight generation module that generates conditional weight for convolution/linear layers based on the input condition. We test CAN on class-conditional image generation on ImageNet and text-to-image generation on COCO. CAN consistently delivers significant improvements for diffusion transformer models, including DiT and UViT. In particular, CAN combined with EfficientViT (CaT) achieves 2.78 FID on ImageNet 512x512, surpassing DiT-XL/2 while requiring 52x fewer MACs per sampling step.
DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Mar 07, 2024Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$\times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
InstanT: Semi-supervised Learning with Instance-dependent Thresholds
Oct 29, 2023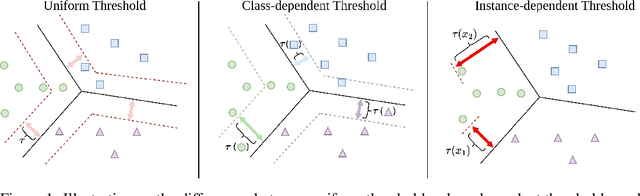
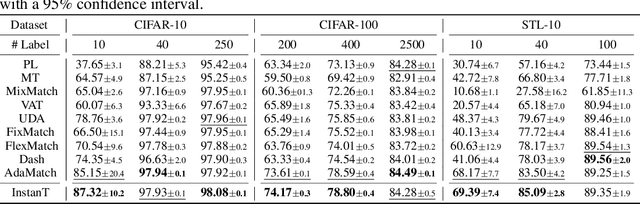
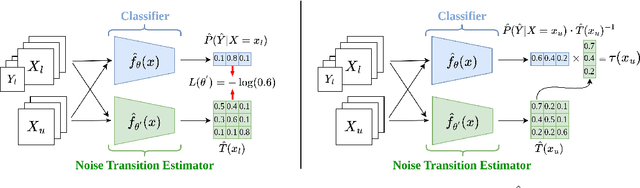

Semi-supervised learning (SSL) has been a fundamental challenge in machine learning for decades. The primary family of SSL algorithms, known as pseudo-labeling, involves assigning pseudo-labels to confident unlabeled instances and incorporating them into the training set. Therefore, the selection criteria of confident instances are crucial to the success of SSL. Recently, there has been growing interest in the development of SSL methods that use dynamic or adaptive thresholds. Yet, these methods typically apply the same threshold to all samples, or use class-dependent thresholds for instances belonging to a certain class, while neglecting instance-level information. In this paper, we propose the study of instance-dependent thresholds, which has the highest degree of freedom compared with existing methods. Specifically, we devise a novel instance-dependent threshold function for all unlabeled instances by utilizing their instance-level ambiguity and the instance-dependent error rates of pseudo-labels, so instances that are more likely to have incorrect pseudo-labels will have higher thresholds. Furthermore, we demonstrate that our instance-dependent threshold function provides a bounded probabilistic guarantee for the correctness of the pseudo-labels it assigns.
Winning Prize Comes from Losing Tickets: Improve Invariant Learning by Exploring Variant Parameters for Out-of-Distribution Generalization
Oct 25, 2023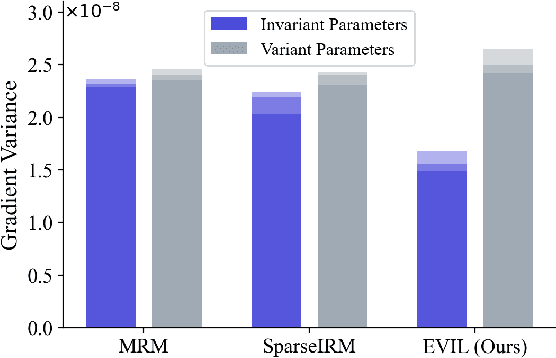
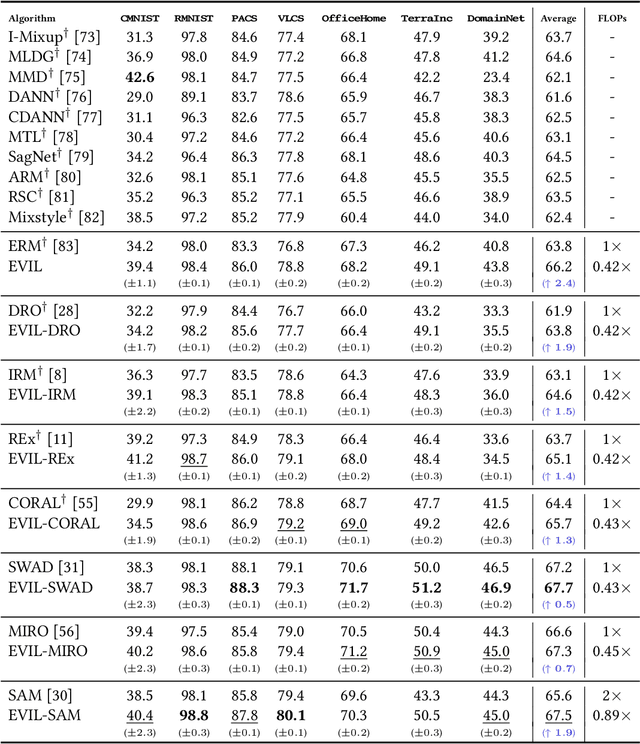
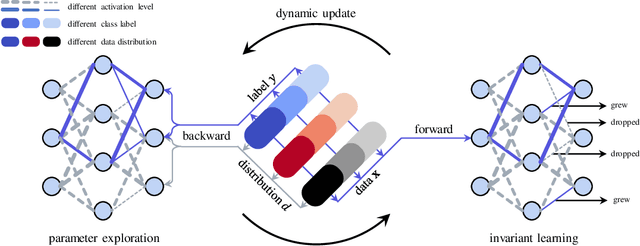
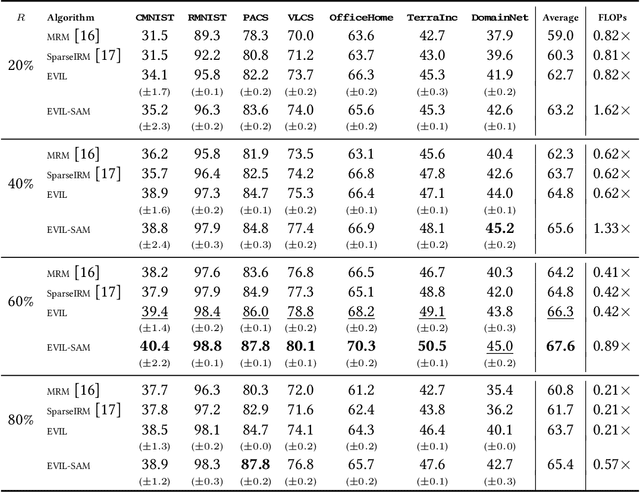
Out-of-Distribution (OOD) Generalization aims to learn robust models that generalize well to various environments without fitting to distribution-specific features. Recent studies based on Lottery Ticket Hypothesis (LTH) address this problem by minimizing the learning target to find some of the parameters that are critical to the task. However, in OOD problems, such solutions are suboptimal as the learning task contains severe distribution noises, which can mislead the optimization process. Therefore, apart from finding the task-related parameters (i.e., invariant parameters), we propose Exploring Variant parameters for Invariant Learning (EVIL) which also leverages the distribution knowledge to find the parameters that are sensitive to distribution shift (i.e., variant parameters). Once the variant parameters are left out of invariant learning, a robust subnetwork that is resistant to distribution shift can be found. Additionally, the parameters that are relatively stable across distributions can be considered invariant ones to improve invariant learning. By fully exploring both variant and invariant parameters, our EVIL can effectively identify a robust subnetwork to improve OOD generalization. In extensive experiments on integrated testbed: DomainBed, EVIL can effectively and efficiently enhance many popular methods, such as ERM, IRM, SAM, etc.
AutoMLP: Automated MLP for Sequential Recommendations
Mar 11, 2023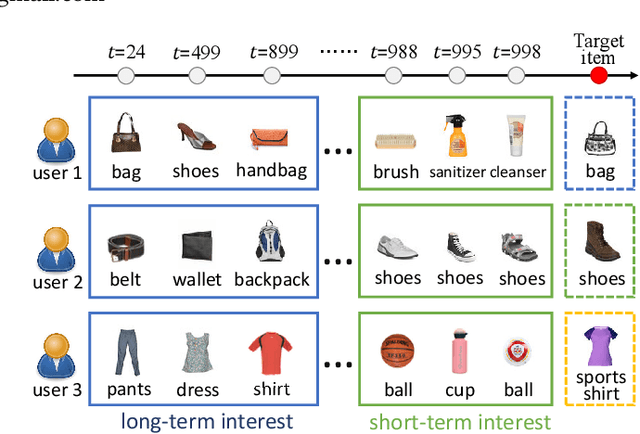

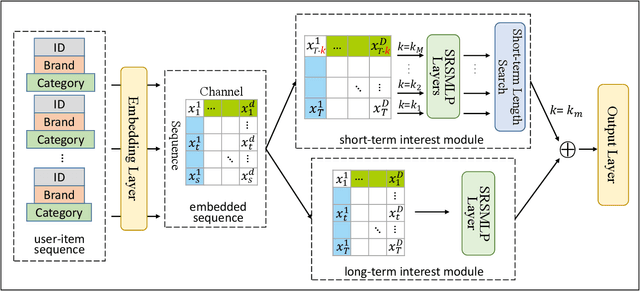
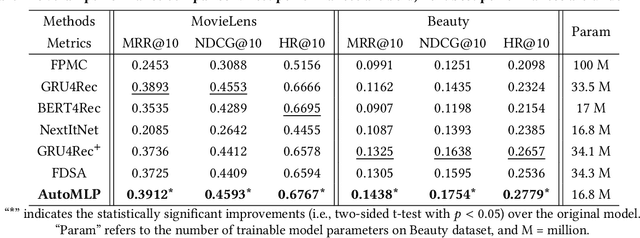
Sequential recommender systems aim to predict users' next interested item given their historical interactions. However, a long-standing issue is how to distinguish between users' long/short-term interests, which may be heterogeneous and contribute differently to the next recommendation. Existing approaches usually set pre-defined short-term interest length by exhaustive search or empirical experience, which is either highly inefficient or yields subpar results. The recent advanced transformer-based models can achieve state-of-the-art performances despite the aforementioned issue, but they have a quadratic computational complexity to the length of the input sequence. To this end, this paper proposes a novel sequential recommender system, AutoMLP, aiming for better modeling users' long/short-term interests from their historical interactions. In addition, we design an automated and adaptive search algorithm for preferable short-term interest length via end-to-end optimization. Through extensive experiments, we show that AutoMLP has competitive performance against state-of-the-art methods, while maintaining linear computational complexity.
Efficient Spatially Sparse Inference for Conditional GANs and Diffusion Models
Nov 15, 2022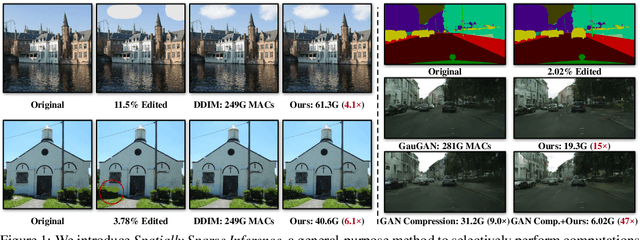
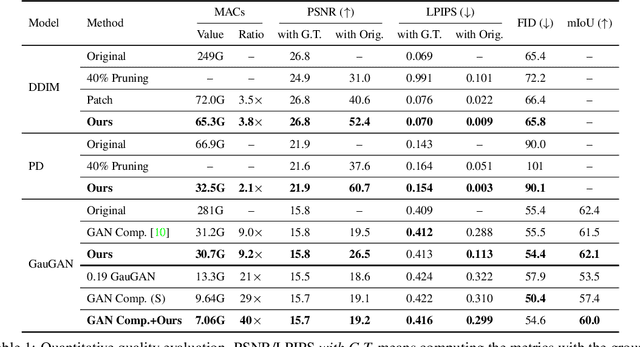
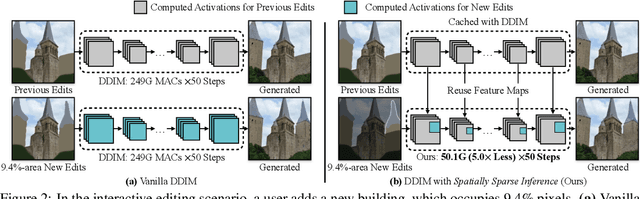
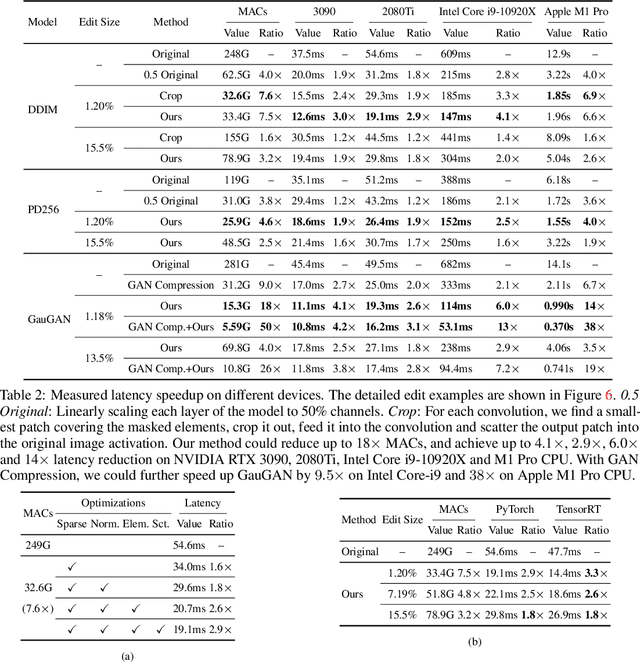
During image editing, existing deep generative models tend to re-synthesize the entire output from scratch, including the unedited regions. This leads to a significant waste of computation, especially for minor editing operations. In this work, we present Spatially Sparse Inference (SSI), a general-purpose technique that selectively performs computation for edited regions and accelerates various generative models, including both conditional GANs and diffusion models. Our key observation is that users tend to make gradual changes to the input image. This motivates us to cache and reuse the feature maps of the original image. Given an edited image, we sparsely apply the convolutional filters to the edited regions while reusing the cached features for the unedited regions. Based on our algorithm, we further propose Sparse Incremental Generative Engine (SIGE) to convert the computation reduction to latency reduction on off-the-shelf hardware. With 1.2%-area edited regions, our method reduces the computation of DDIM by 7.5$\times$ and GauGAN by 18$\times$ while preserving the visual fidelity. With SIGE, we accelerate the speed of DDIM by 3.0x on RTX 3090 and 6.6$\times$ on Apple M1 Pro CPU, and GauGAN by 4.2$\times$ on RTX 3090 and 14$\times$ on Apple M1 Pro CPU.
Federated Graph Contrastive Learning
Jul 24, 2022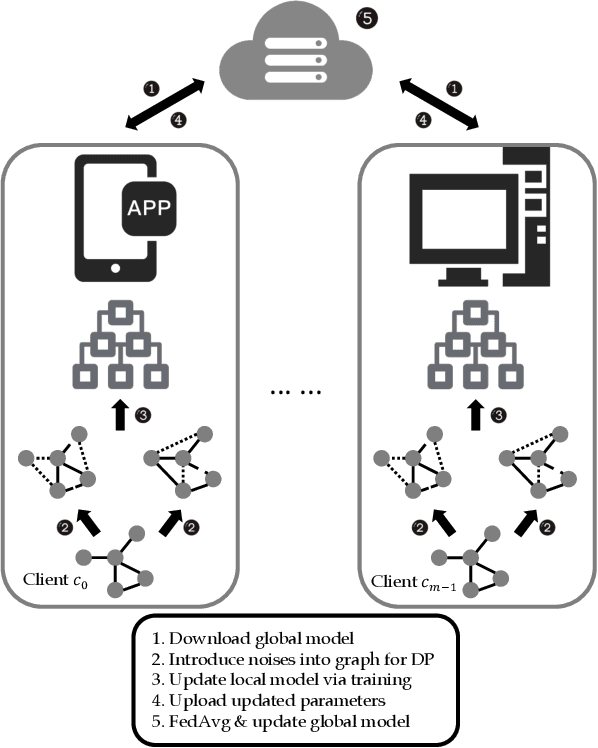
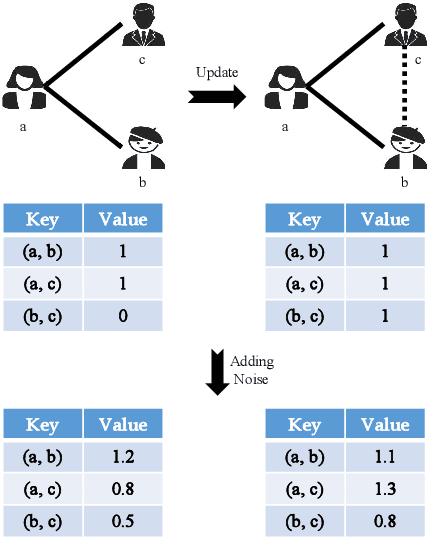
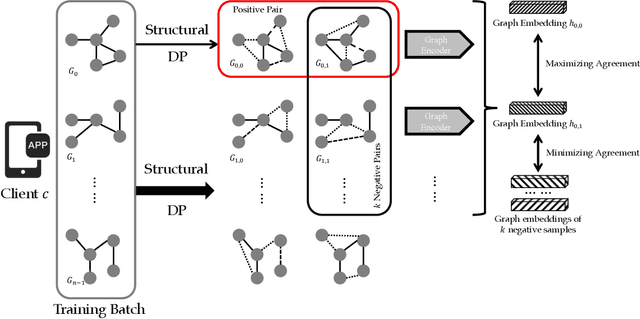
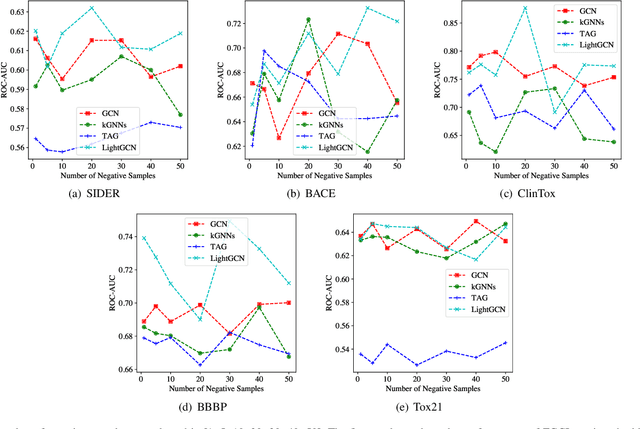
Graph learning models are critical tools for researchers to explore graph-structured data. To train a capable graph learning model, a conventional method uses sufficient training data to train a graph model on a single device. However, it is prohibitive to do so in real-world scenarios due to privacy concerns. Federated learning provides a feasible solution to address such limitations via introducing various privacy-preserving mechanisms, such as differential privacy on graph edges. Nevertheless, differential privacy in federated graph learning secures the classified information maintained in graphs. It degrades the performances of the graph learning models. In this paper, we investigate how to implement differential privacy on graph edges and observe the performances decreasing in the experiments. We also note that the differential privacy on graph edges introduces noises to perturb graph proximity, which is one of the graph augmentations in graph contrastive learning. Inspired by that, we propose to leverage the advantages of graph contrastive learning to alleviate the performance dropping caused by differential privacy. Extensive experiments are conducted with several representative graph models and widely-used datasets, showing that contrastive learning indeed alleviates the models' performance dropping caused by differential privacy.
Lite Pose: Efficient Architecture Design for 2D Human Pose Estimation
May 03, 2022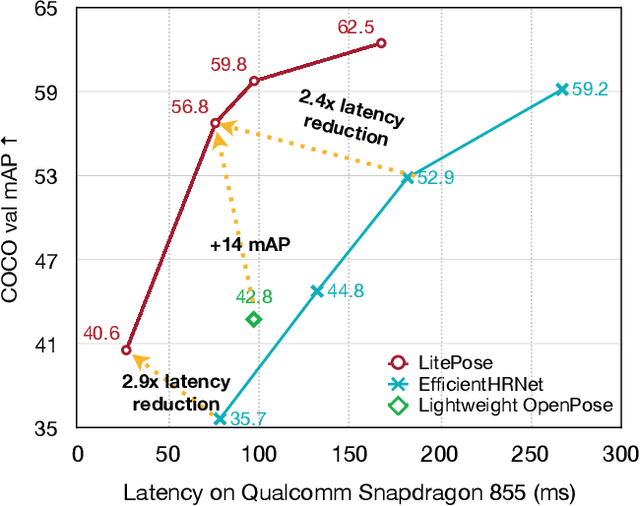
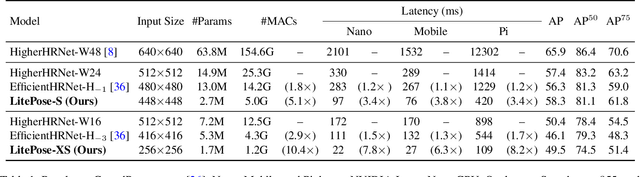
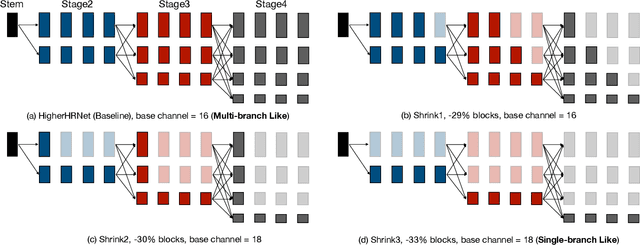
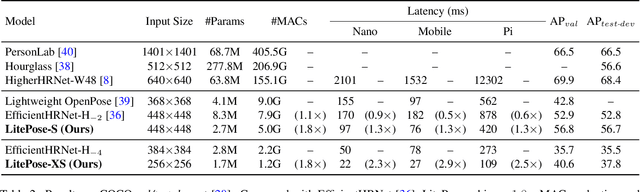
Pose estimation plays a critical role in human-centered vision applications. However, it is difficult to deploy state-of-the-art HRNet-based pose estimation models on resource-constrained edge devices due to the high computational cost (more than 150 GMACs per frame). In this paper, we study efficient architecture design for real-time multi-person pose estimation on edge. We reveal that HRNet's high-resolution branches are redundant for models at the low-computation region via our gradual shrinking experiments. Removing them improves both efficiency and performance. Inspired by this finding, we design LitePose, an efficient single-branch architecture for pose estimation, and introduce two simple approaches to enhance the capacity of LitePose, including Fusion Deconv Head and Large Kernel Convs. Fusion Deconv Head removes the redundancy in high-resolution branches, allowing scale-aware feature fusion with low overhead. Large Kernel Convs significantly improve the model's capacity and receptive field while maintaining a low computational cost. With only 25% computation increment, 7x7 kernels achieve +14.0 mAP better than 3x3 kernels on the CrowdPose dataset. On mobile platforms, LitePose reduces the latency by up to 5.0x without sacrificing performance, compared with prior state-of-the-art efficient pose estimation models, pushing the frontier of real-time multi-person pose estimation on edge. Our code and pre-trained models are released at https://github.com/mit-han-lab/litepose.
* 11 pages
MLP4Rec: A Pure MLP Architecture for Sequential Recommendations
Apr 25, 2022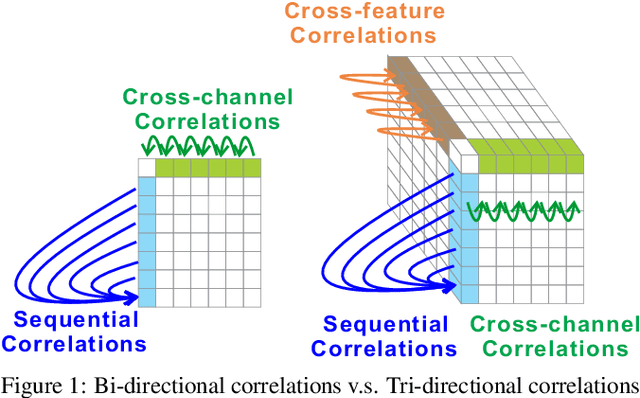
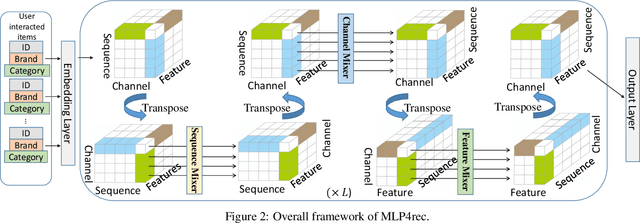
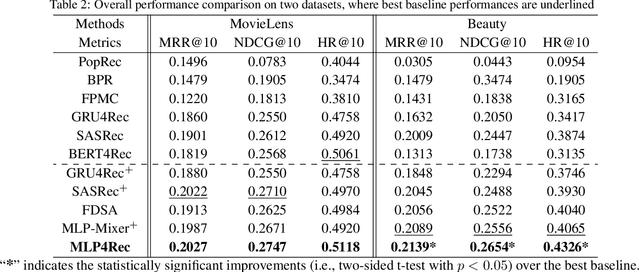
Self-attention models have achieved state-of-the-art performance in sequential recommender systems by capturing the sequential dependencies among user-item interactions. However, they rely on positional embeddings to retain the sequential information, which may break the semantics of item embeddings. In addition, most existing works assume that such sequential dependencies exist solely in the item embeddings, but neglect their existence among the item features. In this work, we propose a novel sequential recommender system (MLP4Rec) based on the recent advances of MLP-based architectures, which is naturally sensitive to the order of items in a sequence. To be specific, we develop a tri-directional fusion scheme to coherently capture sequential, cross-channel and cross-feature correlations. Extensive experiments demonstrate the effectiveness of MLP4Rec over various representative baselines upon two benchmark datasets. The simple architecture of MLP4Rec also leads to the linear computational complexity as well as much fewer model parameters than existing self-attention methods.
GAN Compression: Efficient Architectures for Interactive Conditional GANs
Mar 19, 2020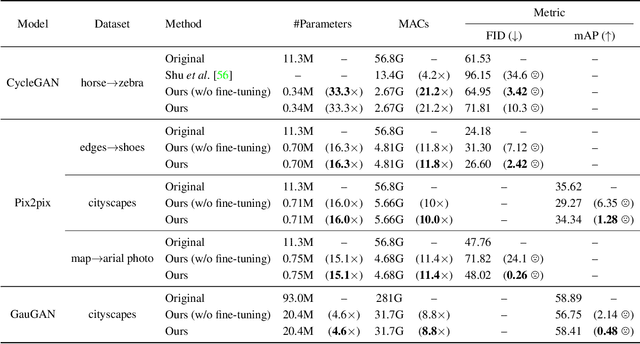
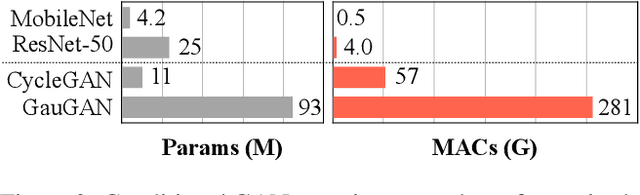
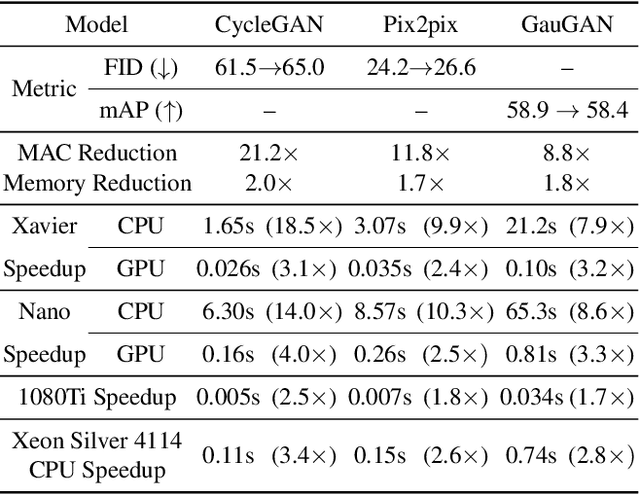
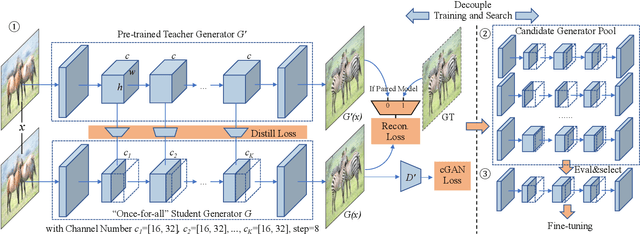
Conditional Generative Adversarial Networks (cGANs) have enabled controllable image synthesis for many computer vision and graphics applications. However, recent cGANs are 1-2 orders of magnitude more computationally-intensive than modern recognition CNNs. For example, GauGAN consumes 281G MACs per image, compared to 0.44G MACs for MobileNet-v3, making it difficult for interactive deployment. In this work, we propose a general-purpose compression framework for reducing the inference time and model size of the generator in cGANs. Directly applying existing CNNs compression methods yields poor performance due to the difficulty of GAN training and the differences in generator architectures. We address these challenges in two ways. First, to stabilize the GAN training, we transfer knowledge of multiple intermediate representations of the original model to its compressed model, and unify unpaired and paired learning. Second, instead of reusing existing CNN designs, our method automatically finds efficient architectures via neural architecture search (NAS). To accelerate the search process, we decouple the model training and architecture search via weight sharing. Experiments demonstrate the effectiveness of our method across different supervision settings (paired and unpaired), model architectures, and learning methods (e.g., pix2pix, GauGAN, CycleGAN). Without losing image quality, we reduce the computation of CycleGAN by more than 20X and GauGAN by 9X, paving the way for interactive image synthesis. The code and demo are publicly available.