 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNan Guan
Pre-processing matters: A segment search method for WSI classification
Apr 17, 2024
Pre-processing for whole slide images can affect classification performance both in the training and inference stages. Our study analyzes the impact of pre-processing parameters on inference and training across single- and multiple-domain datasets. However, searching for an optimal parameter set is time-consuming. To overcome this, we propose a novel Similarity-based Simulated Annealing approach for fast parameter tuning to enhance inference performance on single-domain data. Our method demonstrates significant performance improvements in accuracy, which raise accuracy from 0.512 to 0.847 in a single domain. We further extend our insight into training performance in multi-domain data by employing a novel Bayesian optimization to search optimal pre-processing parameters, resulting in a high AUC of 0.967. We highlight that better pre-processing for WSI can contribute to further accuracy improvement in the histology area.
On the Compressibility of Quantized Large Language Models
Mar 03, 2024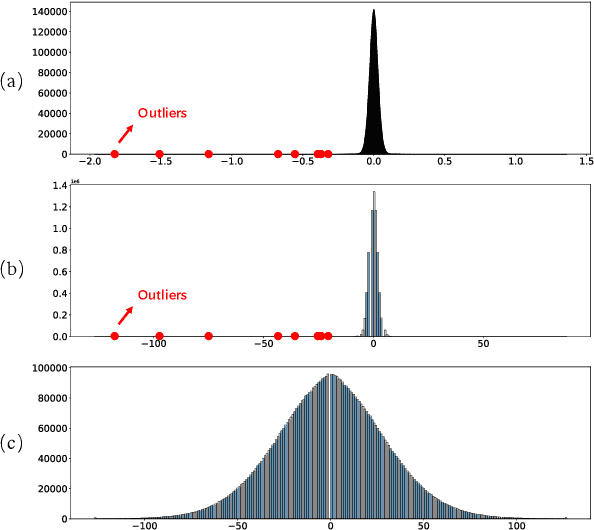

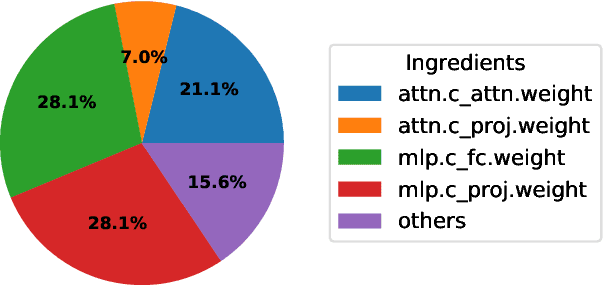
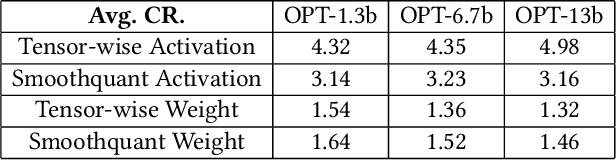
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
Timely Fusion of Surround Radar/Lidar for Object Detection in Autonomous Driving Systems
Sep 09, 2023



Fusing Radar and Lidar sensor data can fully utilize their complementary advantages and provide more accurate reconstruction of the surrounding for autonomous driving systems. Surround Radar/Lidar can provide 360-degree view sampling with the minimal cost, which are promising sensing hardware solutions for autonomous driving systems. However, due to the intrinsic physical constraints, the rotating speed of surround Radar, and thus the frequency to generate Radar data frames, is much lower than surround Lidar. Existing Radar/Lidar fusion methods have to work at the low frequency of surround Radar, which cannot meet the high responsiveness requirement of autonomous driving systems.This paper develops techniques to fuse surround Radar/Lidar with working frequency only limited by the faster surround Lidar instead of the slower surround Radar, based on the state-of-the-art object detection model MVDNet. The basic idea of our approach is simple: we let MVDNet work with temporally unaligned data from Radar/Lidar, so that fusion can take place at any time when a new Lidar data frame arrives, instead of waiting for the slow Radar data frame. However, directly applying MVDNet to temporally unaligned Radar/Lidar data greatly degrades its object detection accuracy. The key information revealed in this paper is that we can achieve high output frequency with little accuracy loss by enhancing the training procedure to explore the temporal redundancy in MVDNet so that it can tolerate the temporal unalignment of input data. We explore several different ways of training enhancement and compare them quantitatively with experiments.
Miriam: Exploiting Elastic Kernels for Real-time Multi-DNN Inference on Edge GPU
Jul 10, 2023



Many applications such as autonomous driving and augmented reality, require the concurrent running of multiple deep neural networks (DNN) that poses different levels of real-time performance requirements. However, coordinating multiple DNN tasks with varying levels of criticality on edge GPUs remains an area of limited study. Unlike server-level GPUs, edge GPUs are resource-limited and lack hardware-level resource management mechanisms for avoiding resource contention. Therefore, we propose Miriam, a contention-aware task coordination framework for multi-DNN inference on edge GPU. Miriam consolidates two main components, an elastic-kernel generator, and a runtime dynamic kernel coordinator, to support mixed critical DNN inference. To evaluate Miriam, we build a new DNN inference benchmark based on CUDA with diverse representative DNN workloads. Experiments on two edge GPU platforms show that Miriam can increase system throughput by 92% while only incurring less than 10\% latency overhead for critical tasks, compared to state of art baselines.
Moses: Efficient Exploitation of Cross-device Transferable Features for Tensor Program Optimization
Jan 15, 2022
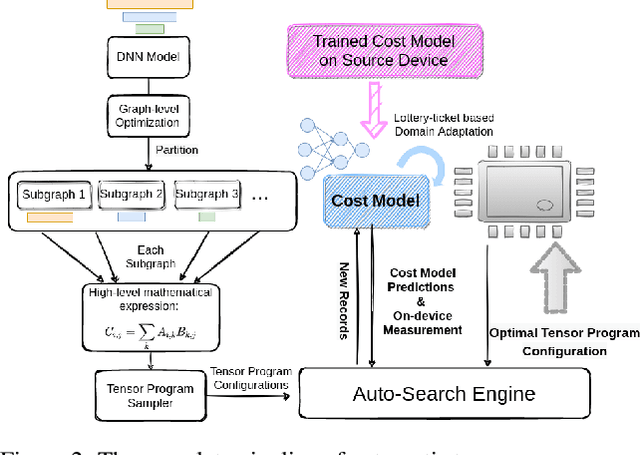
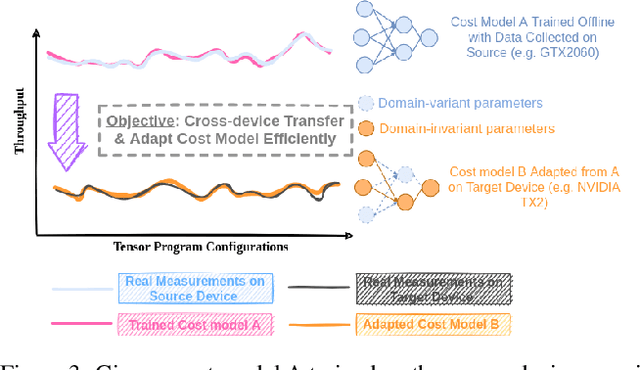
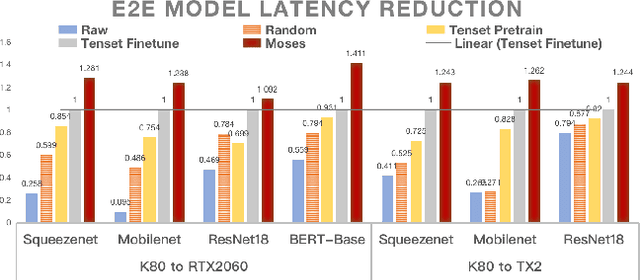
Achieving efficient execution of machine learning models has attracted significant attention recently. To generate tensor programs efficiently, a key component of DNN compilers is the cost model that can predict the performance of each configuration on specific devices. However, due to the rapid emergence of hardware platforms, it is increasingly labor-intensive to train domain-specific predictors for every new platform. Besides, current design of cost models cannot provide transferable features between different hardware accelerators efficiently and effectively. In this paper, we propose Moses, a simple and efficient design based on the lottery ticket hypothesis, which fully takes advantage of the features transferable to the target device via domain adaptation. Compared with state-of-the-art approaches, Moses achieves up to 1.53X efficiency gain in the search stage and 1.41X inference speedup on challenging DNN benchmarks.