 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeijie Dong
VMRNN: Integrating Vision Mamba and LSTM for Efficient and Accurate Spatiotemporal Forecasting
Mar 26, 2024
Combining CNNs or ViTs, with RNNs for spatiotemporal forecasting, has yielded unparalleled results in predicting temporal and spatial dynamics. However, modeling extensive global information remains a formidable challenge; CNNs are limited by their narrow receptive fields, and ViTs struggle with the intensive computational demands of their attention mechanisms. The emergence of recent Mamba-based architectures has been met with enthusiasm for their exceptional long-sequence modeling capabilities, surpassing established vision models in efficiency and accuracy, which motivates us to develop an innovative architecture tailored for spatiotemporal forecasting. In this paper, we propose the VMRNN cell, a new recurrent unit that integrates the strengths of Vision Mamba blocks with LSTM. We construct a network centered on VMRNN cells to tackle spatiotemporal prediction tasks effectively. Our extensive evaluations show that our proposed approach secures competitive results on a variety of tasks while maintaining a smaller model size. Our code is available at https://github.com/yyyujintang/VMRNN-PyTorch.
ParZC: Parametric Zero-Cost Proxies for Efficient NAS
Feb 03, 2024Recent advancements in Zero-shot Neural Architecture Search (NAS) highlight the efficacy of zero-cost proxies in various NAS benchmarks. Several studies propose the automated design of zero-cost proxies to achieve SOTA performance but require tedious searching progress. Furthermore, we identify a critical issue with current zero-cost proxies: they aggregate node-wise zero-cost statistics without considering the fact that not all nodes in a neural network equally impact performance estimation. Our observations reveal that node-wise zero-cost statistics significantly vary in their contributions to performance, with each node exhibiting a degree of uncertainty. Based on this insight, we introduce a novel method called Parametric Zero-Cost Proxies (ParZC) framework to enhance the adaptability of zero-cost proxies through parameterization. To address the node indiscrimination, we propose a Mixer Architecture with Bayesian Network (MABN) to explore the node-wise zero-cost statistics and estimate node-specific uncertainty. Moreover, we propose DiffKendall as a loss function to directly optimize Kendall's Tau coefficient in a differentiable manner so that our ParZC can better handle the discrepancies in ranking architectures. Comprehensive experiments on NAS-Bench-101, 201, and NDS demonstrate the superiority of our proposed ParZC compared to existing zero-shot NAS methods. Additionally, we demonstrate the versatility and adaptability of ParZC by transferring it to the Vision Transformer search space.
Auto-Prox: Training-Free Vision Transformer Architecture Search via Automatic Proxy Discovery
Dec 14, 2023The substantial success of Vision Transformer (ViT) in computer vision tasks is largely attributed to the architecture design. This underscores the necessity of efficient architecture search for designing better ViTs automatically. As training-based architecture search methods are computationally intensive, there is a growing interest in training-free methods that use zero-cost proxies to score ViTs. However, existing training-free approaches require expert knowledge to manually design specific zero-cost proxies. Moreover, these zero-cost proxies exhibit limitations to generalize across diverse domains. In this paper, we introduce Auto-Prox, an automatic proxy discovery framework, to address the problem. First, we build the ViT-Bench-101, which involves different ViT candidates and their actual performance on multiple datasets. Utilizing ViT-Bench-101, we can evaluate zero-cost proxies based on their score-accuracy correlation. Then, we represent zero-cost proxies with computation graphs and organize the zero-cost proxy search space with ViT statistics and primitive operations. To discover generic zero-cost proxies, we propose a joint correlation metric to evolve and mutate different zero-cost proxy candidates. We introduce an elitism-preserve strategy for search efficiency to achieve a better trade-off between exploitation and exploration. Based on the discovered zero-cost proxy, we conduct a ViT architecture search in a training-free manner. Extensive experiments demonstrate that our method generalizes well to different datasets and achieves state-of-the-art results both in ranking correlation and final accuracy. Codes can be found at https://github.com/lilujunai/Auto-Prox-AAAI24.
TVT: Training-Free Vision Transformer Search on Tiny Datasets
Nov 24, 2023Training-free Vision Transformer (ViT) architecture search is presented to search for a better ViT with zero-cost proxies. While ViTs achieve significant distillation gains from CNN teacher models on small datasets, the current zero-cost proxies in ViTs do not generalize well to the distillation training paradigm according to our experimental observations. In this paper, for the first time, we investigate how to search in a training-free manner with the help of teacher models and devise an effective Training-free ViT (TVT) search framework. Firstly, we observe that the similarity of attention maps between ViT and ConvNet teachers affects distill accuracy notably. Thus, we present a teacher-aware metric conditioned on the feature attention relations between teacher and student. Additionally, TVT employs the L2-Norm of the student's weights as the student-capability metric to improve ranking consistency. Finally, TVT searches for the best ViT for distilling with ConvNet teachers via our teacher-aware metric and student-capability metric, resulting in impressive gains in efficiency and effectiveness. Extensive experiments on various tiny datasets and search spaces show that our TVT outperforms state-of-the-art training-free search methods. The code will be released.
Dissecting the Runtime Performance of the Training, Fine-tuning, and Inference of Large Language Models
Nov 07, 2023Large Language Models (LLMs) have seen great advance in both academia and industry, and their popularity results in numerous open-source frameworks and techniques in accelerating LLM pre-training, fine-tuning, and inference. Training and deploying LLMs are expensive as it requires considerable computing resources and memory, hence many efficient approaches have been developed for improving system pipelines as well as operators. However, the runtime performance can vary significantly across hardware and software stacks, which makes it difficult to choose the best configuration. In this work, we aim to benchmark the performance from both macro and micro perspectives. First, we benchmark the end-to-end performance of pre-training, fine-tuning, and serving LLMs in different sizes , i.e., 7, 13, and 70 billion parameters (7B, 13B, and 70B) on three 8-GPU platforms with and without individual optimization techniques, including ZeRO, quantization, recomputation, FlashAttention. Then, we dive deeper to provide a detailed runtime analysis of the sub-modules, including computing and communication operators in LLMs. For end users, our benchmark and findings help better understand different optimization techniques, training and inference frameworks, together with hardware platforms in choosing configurations for deploying LLMs. For researchers, our in-depth module-wise analyses discover potential opportunities for future work to further optimize the runtime performance of LLMs.
EMQ: Evolving Training-free Proxies for Automated Mixed Precision Quantization
Jul 20, 2023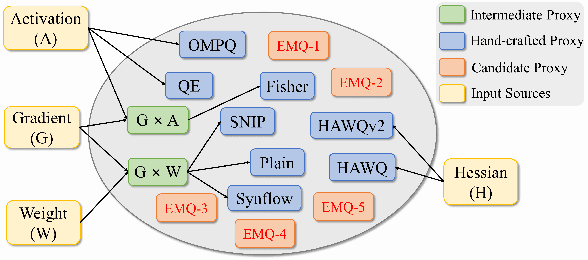

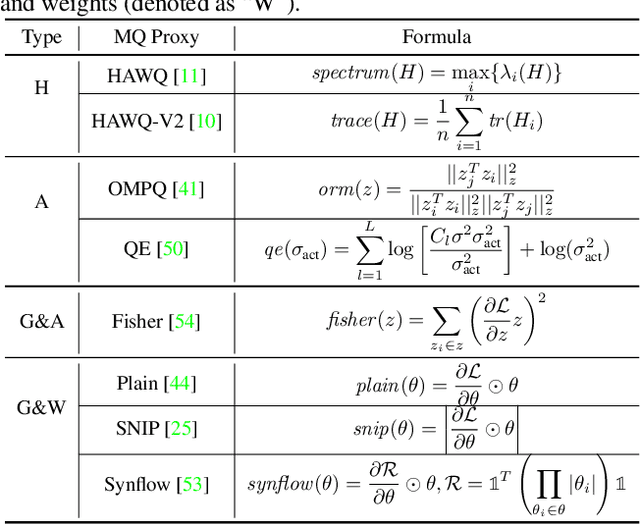
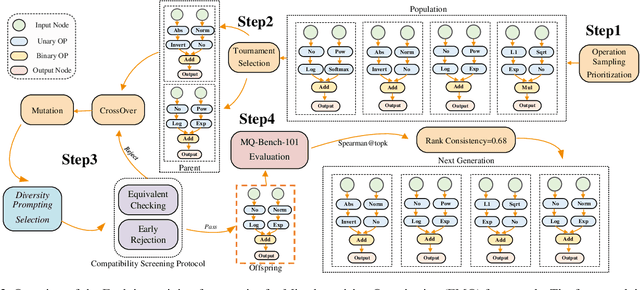
Mixed-Precision Quantization~(MQ) can achieve a competitive accuracy-complexity trade-off for models. Conventional training-based search methods require time-consuming candidate training to search optimized per-layer bit-width configurations in MQ. Recently, some training-free approaches have presented various MQ proxies and significantly improve search efficiency. However, the correlation between these proxies and quantization accuracy is poorly understood. To address the gap, we first build the MQ-Bench-101, which involves different bit configurations and quantization results. Then, we observe that the existing training-free proxies perform weak correlations on the MQ-Bench-101. To efficiently seek superior proxies, we develop an automatic search of proxies framework for MQ via evolving algorithms. In particular, we devise an elaborate search space involving the existing proxies and perform an evolution search to discover the best correlated MQ proxy. We proposed a diversity-prompting selection strategy and compatibility screening protocol to avoid premature convergence and improve search efficiency. In this way, our Evolving proxies for Mixed-precision Quantization~(EMQ) framework allows the auto-generation of proxies without heavy tuning and expert knowledge. Extensive experiments on ImageNet with various ResNet and MobileNet families demonstrate that our EMQ obtains superior performance than state-of-the-art mixed-precision methods at a significantly reduced cost. The code will be released.
DisWOT: Student Architecture Search for Distillation WithOut Training
Mar 28, 2023



Knowledge distillation (KD) is an effective training strategy to improve the lightweight student models under the guidance of cumbersome teachers. However, the large architecture difference across the teacher-student pairs limits the distillation gains. In contrast to previous adaptive distillation methods to reduce the teacher-student gap, we explore a novel training-free framework to search for the best student architectures for a given teacher. Our work first empirically show that the optimal model under vanilla training cannot be the winner in distillation. Secondly, we find that the similarity of feature semantics and sample relations between random-initialized teacher-student networks have good correlations with final distillation performances. Thus, we efficiently measure similarity matrixs conditioned on the semantic activation maps to select the optimal student via an evolutionary algorithm without any training. In this way, our student architecture search for Distillation WithOut Training (DisWOT) significantly improves the performance of the model in the distillation stage with at least 180$\times$ training acceleration. Additionally, we extend similarity metrics in DisWOT as new distillers and KD-based zero-proxies. Our experiments on CIFAR, ImageNet and NAS-Bench-201 demonstrate that our technique achieves state-of-the-art results on different search spaces. Our project and code are available at https://lilujunai.github.io/DisWOT-CVPR2023/.
Progressive Meta-Pooling Learning for Lightweight Image Classification Model
Jan 24, 2023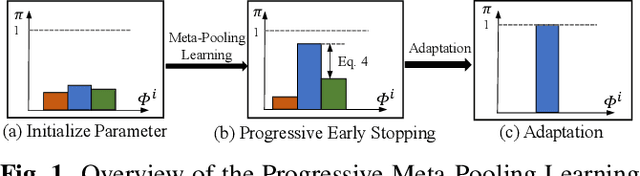
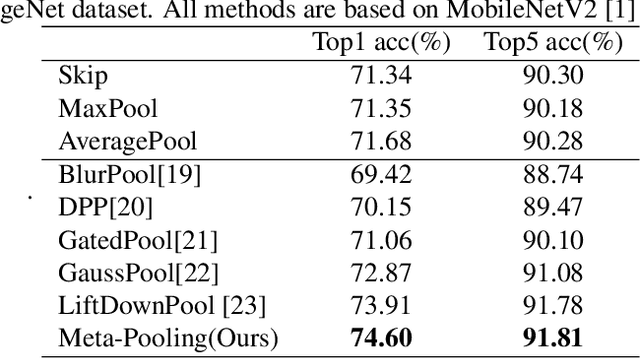
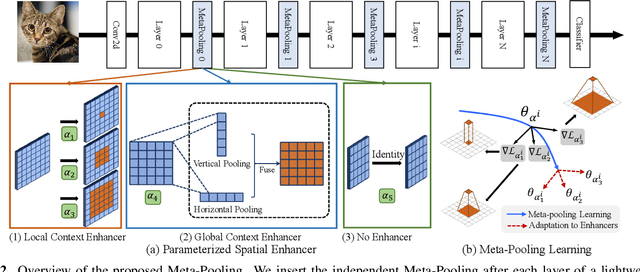
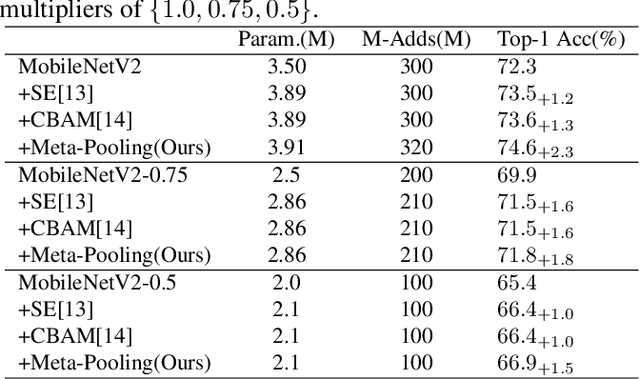
Practical networks for edge devices adopt shallow depth and small convolutional kernels to save memory and computational cost, which leads to a restricted receptive field. Conventional efficient learning methods focus on lightweight convolution designs, ignoring the role of the receptive field in neural network design. In this paper, we propose the Meta-Pooling framework to make the receptive field learnable for a lightweight network, which consists of parameterized pooling-based operations. Specifically, we introduce a parameterized spatial enhancer, which is composed of pooling operations to provide versatile receptive fields for each layer of a lightweight model. Then, we present a Progressive Meta-Pooling Learning (PMPL) strategy for the parameterized spatial enhancer to acquire a suitable receptive field size. The results on the ImageNet dataset demonstrate that MobileNetV2 using Meta-Pooling achieves top1 accuracy of 74.6\%, which outperforms MobileNetV2 by 2.3\%.
RD-NAS: Enhancing One-shot Supernet Ranking Ability via Ranking Distillation from Zero-cost Proxies
Jan 24, 2023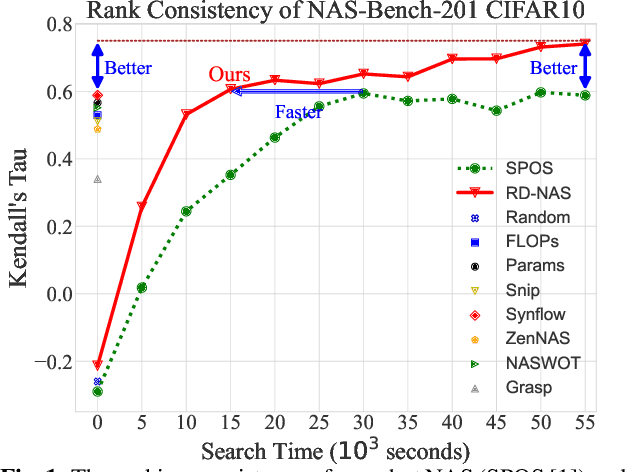
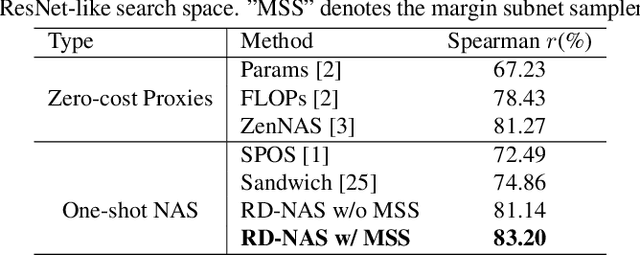
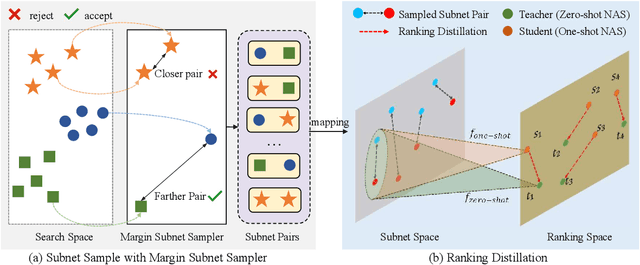
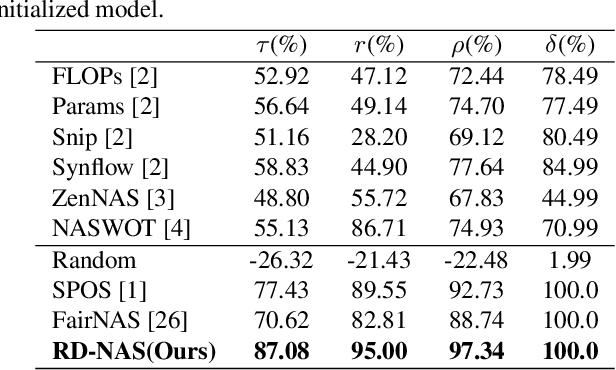
Neural architecture search (NAS) has made tremendous progress in the automatic design of effective neural network structures but suffers from a heavy computational burden. One-shot NAS significantly alleviates the burden through weight sharing and improves computational efficiency. Zero-shot NAS further reduces the cost by predicting the performance of the network from its initial state, which conducts no training. Both methods aim to distinguish between "good" and "bad" architectures, i.e., ranking consistency of predicted and true performance. In this paper, we propose Ranking Distillation one-shot NAS (RD-NAS) to enhance ranking consistency, which utilizes zero-cost proxies as the cheap teacher and adopts the margin ranking loss to distill the ranking knowledge. Specifically, we propose a margin subnet sampler to distill the ranking knowledge from zero-shot NAS to one-shot NAS by introducing Group distance as margin. Our evaluation of the NAS-Bench-201 and ResNet-based search space demonstrates that RD-NAS achieve 10.7\% and 9.65\% improvements in ranking ability, respectively. Our codes are available at https://github.com/pprp/CVPR2022-NAS-competition-Track1-3th-solution
AIM 2022 Challenge on Super-Resolution of Compressed Image and Video: Dataset, Methods and Results
Aug 25, 2022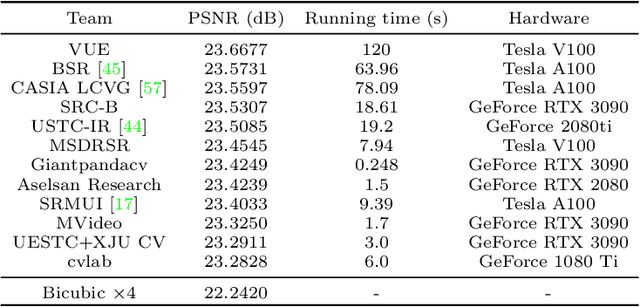
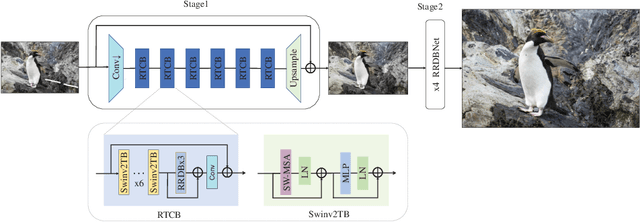

This paper reviews the Challenge on Super-Resolution of Compressed Image and Video at AIM 2022. This challenge includes two tracks. Track 1 aims at the super-resolution of compressed image, and Track~2 targets the super-resolution of compressed video. In Track 1, we use the popular dataset DIV2K as the training, validation and test sets. In Track 2, we propose the LDV 3.0 dataset, which contains 365 videos, including the LDV 2.0 dataset (335 videos) and 30 additional videos. In this challenge, there are 12 teams and 2 teams that submitted the final results to Track 1 and Track 2, respectively. The proposed methods and solutions gauge the state-of-the-art of super-resolution on compressed image and video. The proposed LDV 3.0 dataset is available at https://github.com/RenYang-home/LDV_dataset. The homepage of this challenge is at https://github.com/RenYang-home/AIM22_CompressSR.