 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeter Jung
Onboard Out-of-Calibration Detection of Deep Learning Models using Conformal Prediction
May 04, 2024
The black box nature of deep learning models complicate their usage in critical applications such as remote sensing. Conformal prediction is a method to ensure trust in such scenarios. Subject to data exchangeability, conformal prediction provides finite sample coverage guarantees in the form of a prediction set that is guaranteed to contain the true class within a user defined error rate. In this letter we show that conformal prediction algorithms are related to the uncertainty of the deep learning model and that this relation can be used to detect if the deep learning model is out-of-calibration. Popular classification models like Resnet50, Densenet161, InceptionV3, and MobileNetV2 are applied on remote sensing datasets such as the EuroSAT to demonstrate how under noisy scenarios the model outputs become untrustworthy. Furthermore an out-of-calibration detection procedure relating the model uncertainty and the average size of the conformal prediction set is presented.
Fundamentals of Delay-Doppler Communications: Practical Implementation and Extensions to OTFS
Mar 21, 2024
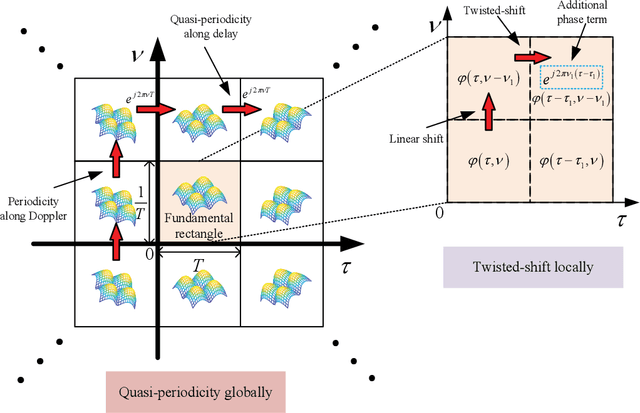
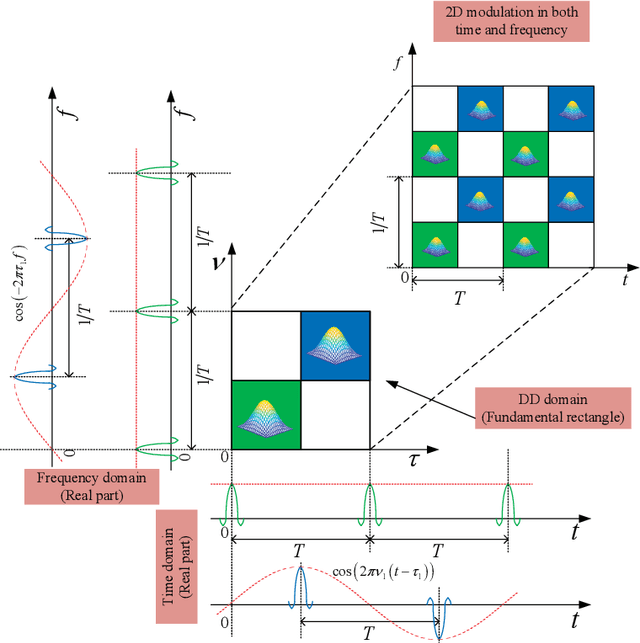
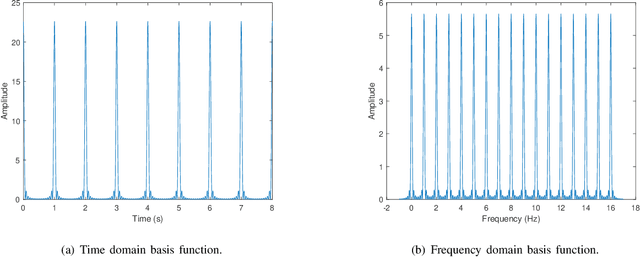
The recently proposed orthogonal time frequency space (OTFS) modulation, which is a typical Delay-Doppler (DD) communication scheme, has attracted significant attention thanks to its appealing performance over doubly-selective channels. In this paper, we present the fundamentals of general DD communications from the viewpoint of the Zak transform. We start our study by constructing DD domain basis functions aligning with the time-frequency (TF)-consistency condition, which are globally quasi-periodic and locally twisted-shifted. We unveil that these features are translated to unique signal structures in both time and frequency, which are beneficial for communication purposes. Then, we focus on the practical implementations of DD Nyquist communications, where we show that rectangular windows achieve perfect DD orthogonality, while truncated periodic signals can obtain sufficient DD orthogonality. Particularly, smoothed rectangular window with excess bandwidth can result in a slightly worse orthogonality but better pulse localization in the DD domain. Furthermore, we present a practical pulse shaping framework for general DD communications and derive the corresponding input-output relation under various shaping pulses. Our numerical results agree with our derivations and also demonstrate advantages of DD communications over conventional orthogonal frequency-division multiplexing (OFDM).
HyperLISTA-ABT: An Ultra-light Unfolded Network for Accurate Multi-component Differential Tomographic SAR Inversion
Sep 28, 2023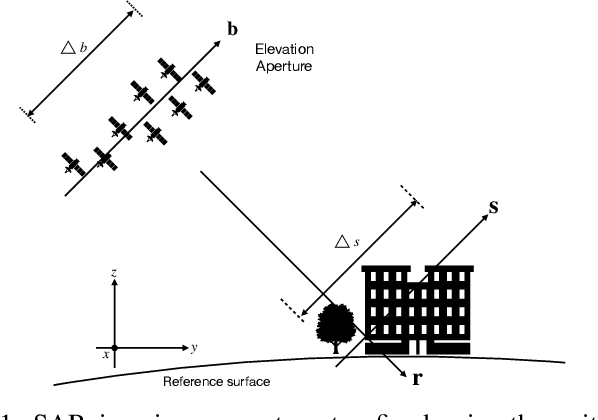
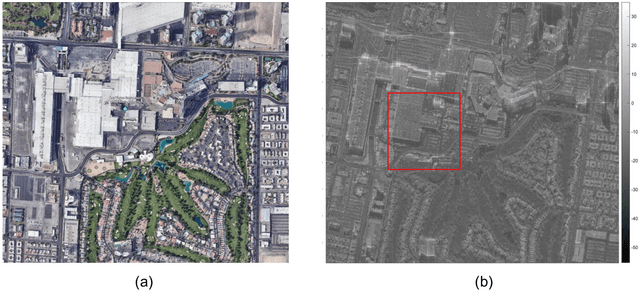
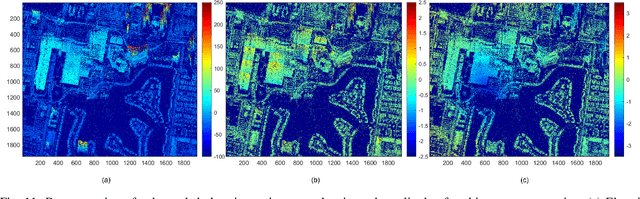
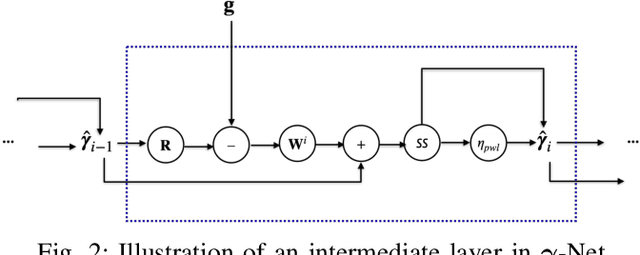
Deep neural networks based on unrolled iterative algorithms have achieved remarkable success in sparse reconstruction applications, such as synthetic aperture radar (SAR) tomographic inversion (TomoSAR). However, the currently available deep learning-based TomoSAR algorithms are limited to three-dimensional (3D) reconstruction. The extension of deep learning-based algorithms to four-dimensional (4D) imaging, i.e., differential TomoSAR (D-TomoSAR) applications, is impeded mainly due to the high-dimensional weight matrices required by the network designed for D-TomoSAR inversion, which typically contain millions of freely trainable parameters. Learning such huge number of weights requires an enormous number of training samples, resulting in a large memory burden and excessive time consumption. To tackle this issue, we propose an efficient and accurate algorithm called HyperLISTA-ABT. The weights in HyperLISTA-ABT are determined in an analytical way according to a minimum coherence criterion, trimming the model down to an ultra-light one with only three hyperparameters. Additionally, HyperLISTA-ABT improves the global thresholding by utilizing an adaptive blockwise thresholding scheme, which applies block-coordinate techniques and conducts thresholding in local blocks, so that weak expressions and local features can be retained in the shrinkage step layer by layer. Simulations were performed and demonstrated the effectiveness of our approach, showing that HyperLISTA-ABT achieves superior computational efficiency and with no significant performance degradation compared to state-of-the-art methods. Real data experiments showed that a high-quality 4D point cloud could be reconstructed over a large area by the proposed HyperLISTA-ABT with affordable computational resources and in a fast time.
Multi-static Parameter Estimation in the Near/Far Field Beam Space for Integrated Sensing and Communication Applications
Sep 26, 2023



This work proposes a maximum likelihood (ML)-based parameter estimation framework for a millimeter wave (mmWave) integrated sensing and communication (ISAC) system in a multi-static configuration using energy-efficient hybrid digital-analog arrays. Due to the typically large arrays deployed in the higher frequency bands to mitigate isotropic path loss, such arrays may operate in the near-field regime. The proposed parameter estimation in this work consists of a two-stage estimation process, where the first stage is based on far-field assumptions, and is used to obtain a first estimate of the target parameters. In cases where the target is determined to be in the near-field of the arrays, a second estimation based on near-field assumptions is carried out to obtain more accurate estimates. In particular, we select beamfocusing array weights designed to achieve a constant gain over an extended spatial region and re-estimate the target parameters at the receivers. We evaluate the effectiveness of the proposed framework in numerous scenarios through numerical simulations and demonstrate the impact of the custom-designed flat-gain beamfocusing codewords in increasing the communication performance of the system.
Extended Target Parameter Estimation and Tracking with an HDA Setup for ISAC Applications
Aug 16, 2023



We investigate radar parameter estimation and beam tracking with a hybrid digital-analog (HDA) architecture in a multi-block measurement framework using an extended target model. In the considered setup, the backscattered data signal is utilized to predict the user position in the next time slots. Specifically, a simplified maximum likelihood framework is adopted for parameter estimation, based on which a simple tracking scheme is also developed. Furthermore, the proposed framework supports adaptive transmitter beamwidth selection, whose effects on the communication performance are also studied. Finally, we verify the effectiveness of the proposed framework via numerical simulations over complex motion patterns that emulate a realistic integrated sensing and communication (ISAC) scenario.
Integrated Sensing and Communication with MOCZ Waveform
Jul 04, 2023



In this work, we propose a waveform based on Modulation on Conjugate-reciprocal Zeros (MOCZ) originally proposed for short-packet communications in [1], as a new Integrated Sensing and Communication (ISAC) waveform. Having previously established the key advantages of MOCZ for noncoherent and sporadic communication, here we leverage the optimal auto-correlation property of Binary MOCZ (BMOCZ) for sensing applications. Due to this property, which eliminates the need for separate communication and radar-centric waveforms, we propose a new frame structure for ISAC, where pilot sequences and preambles become obsolete and are completely removed from the frame. As a result, the data rate can be significantly improved. Aimed at (hardware-) cost-effective radar-sensing applications, we consider a Hybrid Digital-Analog (HDA) beamforming architecture for data transmission and radar sensing. We demonstrate via extensive simulations, that a communication data rate, significantly higher than existing standards can be achieved, while simultaneously achieving sensing performance comparable to state-of-the-art sensing systems.
Basis Pursuit Denoising via Recurrent Neural Network Applied to Super-resolving SAR Tomography
May 23, 2023



Finding sparse solutions of underdetermined linear systems commonly requires the solving of L1 regularized least squares minimization problem, which is also known as the basis pursuit denoising (BPDN). They are computationally expensive since they cannot be solved analytically. An emerging technique known as deep unrolling provided a good combination of the descriptive ability of neural networks, explainable, and computational efficiency for BPDN. Many unrolled neural networks for BPDN, e.g. learned iterative shrinkage thresholding algorithm and its variants, employ shrinkage functions to prune elements with small magnitude. Through experiments on synthetic aperture radar tomography (TomoSAR), we discover the shrinkage step leads to unavoidable information loss in the dynamics of networks and degrades the performance of the model. We propose a recurrent neural network (RNN) with novel sparse minimal gated units (SMGUs) to solve the information loss issue. The proposed RNN architecture with SMGUs benefits from incorporating historical information into optimization, and thus effectively preserves full information in the final output. Taking TomoSAR inversion as an example, extensive simulations demonstrated that the proposed RNN outperforms the state-of-the-art deep learning-based algorithm in terms of super-resolution power as well as generalization ability. It achieved a 10% to 20% higher double scatterers detection rate and is less sensitive to phase and amplitude ratio differences between scatterers. Test on real TerraSAR-X spotlight images also shows a high-quality 3-D reconstruction of the test site.
A physics-informed neural network framework for modeling obstacle-related equations
Apr 07, 2023



Deep learning has been highly successful in some applications. Nevertheless, its use for solving partial differential equations (PDEs) has only been of recent interest with current state-of-the-art machine learning libraries, e.g., TensorFlow or PyTorch. Physics-informed neural networks (PINNs) are an attractive tool for solving partial differential equations based on sparse and noisy data. Here extend PINNs to solve obstacle-related PDEs which present a great computational challenge because they necessitate numerical methods that can yield an accurate approximation of the solution that lies above a given obstacle. The performance of the proposed PINNs is demonstrated in multiple scenarios for linear and nonlinear PDEs subject to regular and irregular obstacles.
Estimation of Doubly-Dispersive Channels in Linearly Precoded Multicarrier Systems Using Smoothness Regularization
Oct 11, 2022



In this paper, we propose a novel channel estimation scheme for pulse-shaped multicarrier systems using smoothness regularization for ultra-reliable low-latency communication (URLLC). It can be applied to any multicarrier system with or without linear precoding to estimate challenging doubly-dispersive channels. A recently proposed modulation scheme using orthogonal precoding is orthogonal time-frequency and space modulation (OTFS). In OTFS, pilot and data symbols are placed in delay-Doppler (DD) domain and are jointly precoded to the time-frequency (TF) domain. On the one hand, such orthogonal precoding increases the achievable channel estimation accuracy and enables high TF diversity at the receiver. On the other hand, it introduces leakage effects which requires extensive leakage suppression when the piloting is jointly precoded with the data. To avoid this, we propose to precode the data symbols only, place pilot symbols without precoding into the TF domain, and estimate the channel coefficients by interpolating smooth functions from the pilot samples. Furthermore, we present a piloting scheme enabling a smooth control of the number and position of the pilot symbols. Our numerical results suggest that the proposed scheme provides accurate channel estimation with reduced signaling overhead compared to standard estimators using Wiener filtering in the discrete DD domain.
Gradient-Based Learning of Discrete Structured Measurement Operators for Signal Recovery
Feb 07, 2022



Countless signal processing applications include the reconstruction of signals from few indirect linear measurements. The design of effective measurement operators is typically constrained by the underlying hardware and physics, posing a challenging and often even discrete optimization task. While the potential of gradient-based learning via the unrolling of iterative recovery algorithms has been demonstrated, it has remained unclear how to leverage this technique when the set of admissible measurement operators is structured and discrete. We tackle this problem by combining unrolled optimization with Gumbel reparametrizations, which enable the computation of low-variance gradient estimates of categorical random variables. Our approach is formalized by GLODISMO (Gradient-based Learning of DIscrete Structured Measurement Operators). This novel method is easy-to-implement, computationally efficient, and extendable due to its compatibility with automatic differentiation. We empirically demonstrate the performance and flexibility of GLODISMO in several prototypical signal recovery applications, verifying that the learned measurement matrices outperform conventional designs based on randomization as well as discrete optimization baselines.