 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePing Wei
Task-Driven Exploration: Decoupling and Inter-Task Feedback for Joint Moment Retrieval and Highlight Detection
Apr 14, 2024
Video moment retrieval and highlight detection are two highly valuable tasks in video understanding, but until recently they have been jointly studied. Although existing studies have made impressive advancement recently, they predominantly follow the data-driven bottom-up paradigm. Such paradigm overlooks task-specific and inter-task effects, resulting in poor model performance. In this paper, we propose a novel task-driven top-down framework TaskWeave for joint moment retrieval and highlight detection. The framework introduces a task-decoupled unit to capture task-specific and common representations. To investigate the interplay between the two tasks, we propose an inter-task feedback mechanism, which transforms the results of one task as guiding masks to assist the other task. Different from existing methods, we present a task-dependent joint loss function to optimize the model. Comprehensive experiments and in-depth ablation studies on QVHighlights, TVSum, and Charades-STA datasets corroborate the effectiveness and flexibility of the proposed framework. Codes are available at https://github.com/EdenGabriel/TaskWeave.
Salience DETR: Enhancing Detection Transformer with Hierarchical Salience Filtering Refinement
Mar 24, 2024DETR-like methods have significantly increased detection performance in an end-to-end manner. The mainstream two-stage frameworks of them perform dense self-attention and select a fraction of queries for sparse cross-attention, which is proven effective for improving performance but also introduces a heavy computational burden and high dependence on stable query selection. This paper demonstrates that suboptimal two-stage selection strategies result in scale bias and redundancy due to the mismatch between selected queries and objects in two-stage initialization. To address these issues, we propose hierarchical salience filtering refinement, which performs transformer encoding only on filtered discriminative queries, for a better trade-off between computational efficiency and precision. The filtering process overcomes scale bias through a novel scale-independent salience supervision. To compensate for the semantic misalignment among queries, we introduce elaborate query refinement modules for stable two-stage initialization. Based on above improvements, the proposed Salience DETR achieves significant improvements of +4.0% AP, +0.2% AP, +4.4% AP on three challenging task-specific detection datasets, as well as 49.2% AP on COCO 2017 with less FLOPs. The code is available at https://github.com/xiuqhou/Salience-DETR.
Efficient Monaural Speech Enhancement using Spectrum Attention Fusion
Aug 04, 2023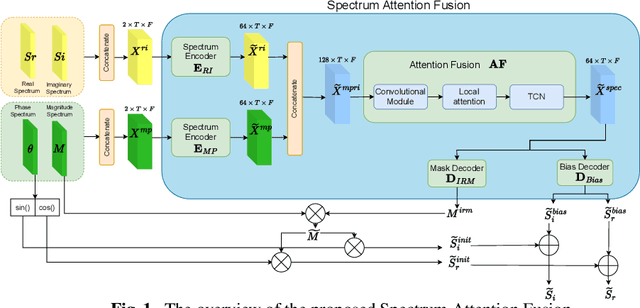
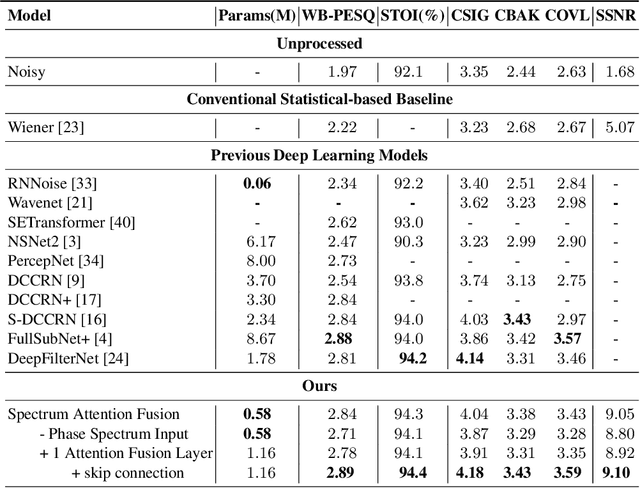
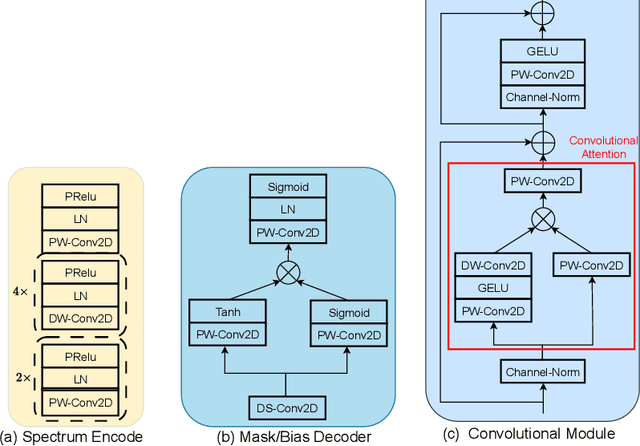
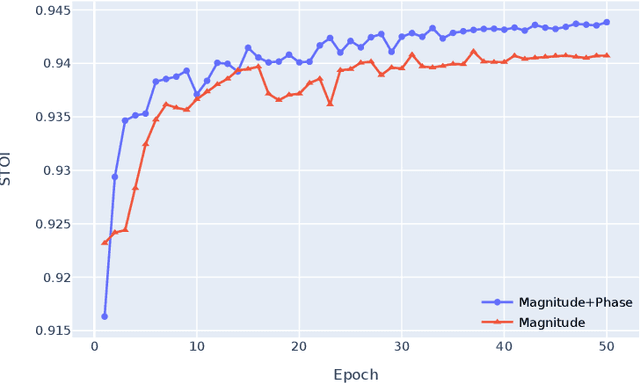
Speech enhancement is a demanding task in automated speech processing pipelines, focusing on separating clean speech from noisy channels. Transformer based models have recently bested RNN and CNN models in speech enhancement, however at the same time they are much more computationally expensive and require much more high quality training data, which is always hard to come by. In this paper, we present an improvement for speech enhancement models that maintains the expressiveness of self-attention while significantly reducing model complexity, which we have termed Spectrum Attention Fusion. We carefully construct a convolutional module to replace several self-attention layers in a speech Transformer, allowing the model to more efficiently fuse spectral features. Our proposed model is able to achieve comparable or better results against SOTA models but with significantly smaller parameters (0.58M) on the Voice Bank + DEMAND dataset.
Generative Steganographic Flow
May 10, 2023

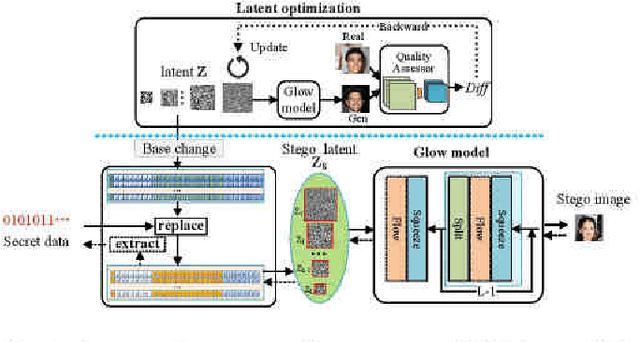

Generative steganography (GS) is a new data hiding manner, featuring direct generation of stego media from secret data. Existing GS methods are generally criticized for their poor performances. In this paper, we propose a novel flow based GS approach -- Generative Steganographic Flow (GSF), which provides direct generation of stego images without cover image. We take the stego image generation and secret data recovery process as an invertible transformation, and build a reversible bijective mapping between input secret data and generated stego images. In the forward mapping, secret data is hidden in the input latent of Glow model to generate stego images. By reversing the mapping, hidden data can be extracted exactly from generated stego images. Furthermore, we propose a novel latent optimization strategy to improve the fidelity of stego images. Experimental results show our proposed GSF has far better performances than SOTA works.
Generative Steganography Diffusion
May 05, 2023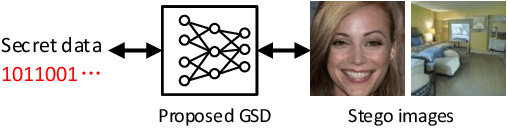
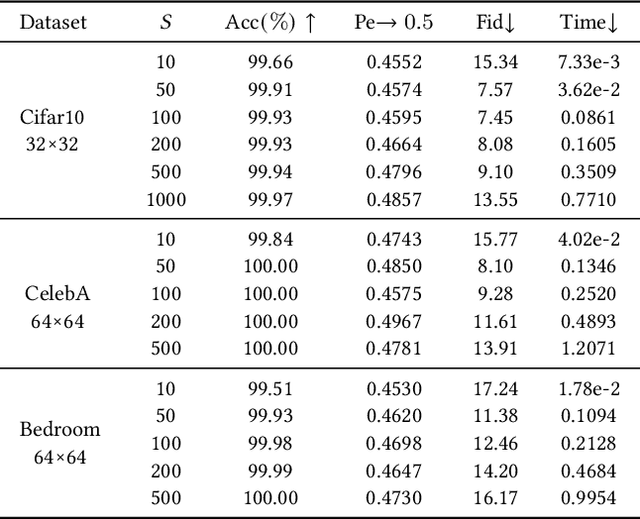
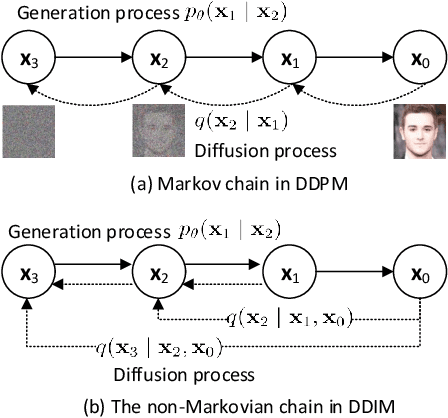
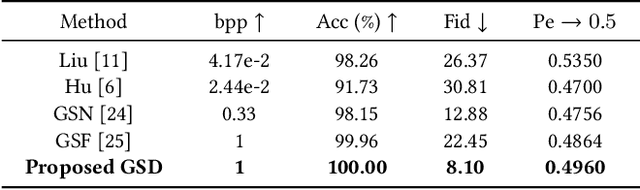
Generative steganography (GS) is an emerging technique that generates stego images directly from secret data. Various GS methods based on GANs or Flow have been developed recently. However, existing GAN-based GS methods cannot completely recover the hidden secret data due to the lack of network invertibility, while Flow-based methods produce poor image quality due to the stringent reversibility restriction in each module. To address this issue, we propose a novel GS scheme called "Generative Steganography Diffusion" (GSD) by devising an invertible diffusion model named "StegoDiffusion". It not only generates realistic stego images but also allows for 100\% recovery of the hidden secret data. The proposed StegoDiffusion model leverages a non-Markov chain with a fast sampling technique to achieve efficient stego image generation. By constructing an ordinary differential equation (ODE) based on the transition probability of the generation process in StegoDiffusion, secret data and stego images can be converted to each other through the approximate solver of ODE -- Euler iteration formula, enabling the use of irreversible but more expressive network structures to achieve model invertibility. Our proposed GSD has the advantages of both reversibility and high performance, significantly outperforming existing GS methods in all metrics.
Generative Steganography Network
Aug 14, 2022
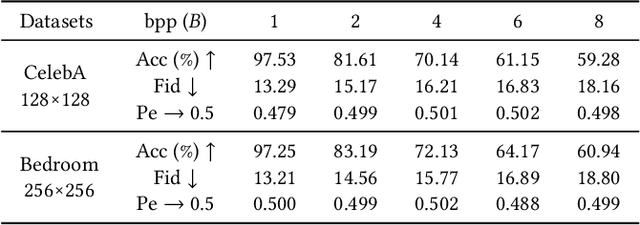
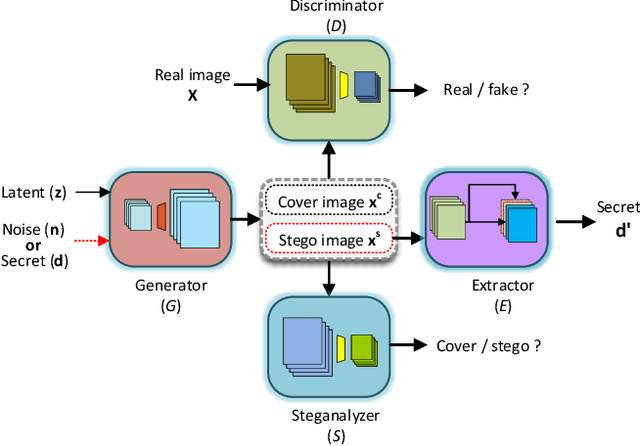
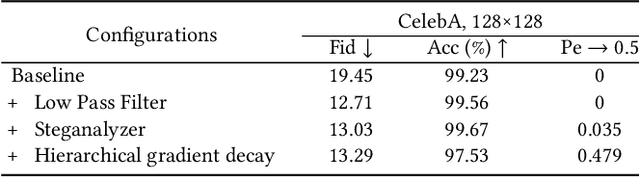
Steganography usually modifies cover media to embed secret data. A new steganographic approach called generative steganography (GS) has emerged recently, in which stego images (images containing secret data) are generated from secret data directly without cover media. However, existing GS schemes are often criticized for their poor performances. In this paper, we propose an advanced generative steganography network (GSN) that can generate realistic stego images without using cover images. We firstly introduce the mutual information mechanism in GS, which helps to achieve high secret extraction accuracy. Our model contains four sub-networks, i.e., an image generator ($G$), a discriminator ($D$), a steganalyzer ($S$), and a data extractor ($E$). $D$ and $S$ act as two adversarial discriminators to ensure the visual quality and security of generated stego images. $E$ is to extract the hidden secret from generated stego images. The generator $G$ is flexibly constructed to synthesize either cover or stego images with different inputs. It facilitates covert communication by concealing the function of generating stego images in a normal generator. A module named secret block is designed to hide secret data in the feature maps during image generation, with which high hiding capacity and image fidelity are achieved. In addition, a novel hierarchical gradient decay (HGD) skill is developed to resist steganalysis detection. Experiments demonstrate the superiority of our work over existing methods.
Multi-sensor joint target detection, tracking and classification via Bernoulli filter
Sep 23, 2021
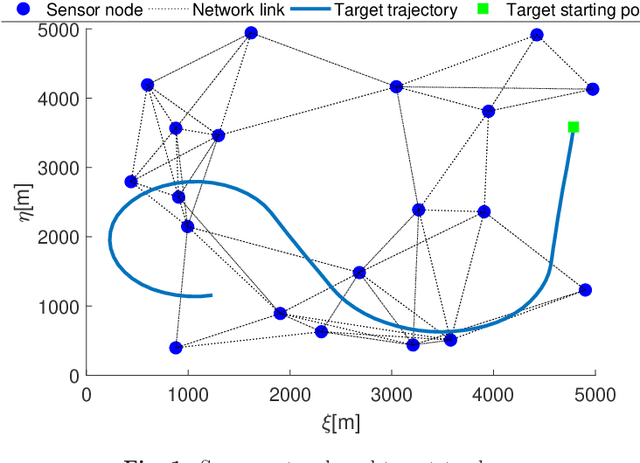

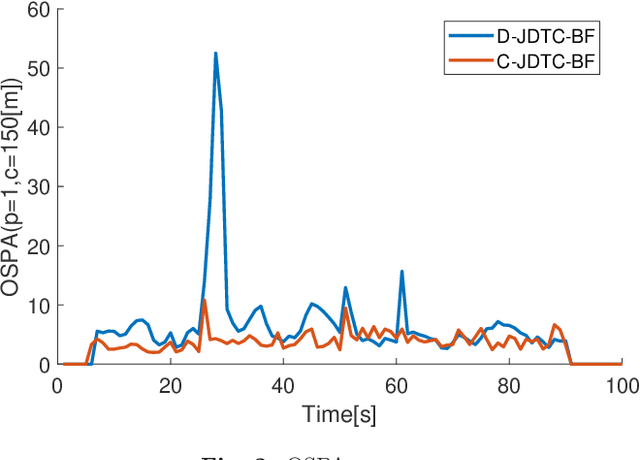
This paper focuses on \textit{joint detection, tracking and classification} (JDTC) of a target via multi-sensor fusion. The target can be present or not, can belong to different classes, and depending on its class can behave according to different kinematic modes. Accordingly, it is modeled as a suitably extended Bernoulli \textit{random finite set} (RFS) uniquely characterized by existence, classification, class-conditioned mode and class\&mode-conditioned state probability distributions. By designing suitable centralized and distributed rules for fusing information on target existence, class, mode and state from different sensor nodes, novel \textit{centralized} and \textit{distributed} JDTC \textit{Bernoulli filters} (C-JDTC-BF and D-JDTC-BF), are proposed. The performance of the proposed JDTC-BF approach is evaluated by means of simulation experiments.
Predicting Human Activities Using Stochastic Grammar
Aug 02, 2017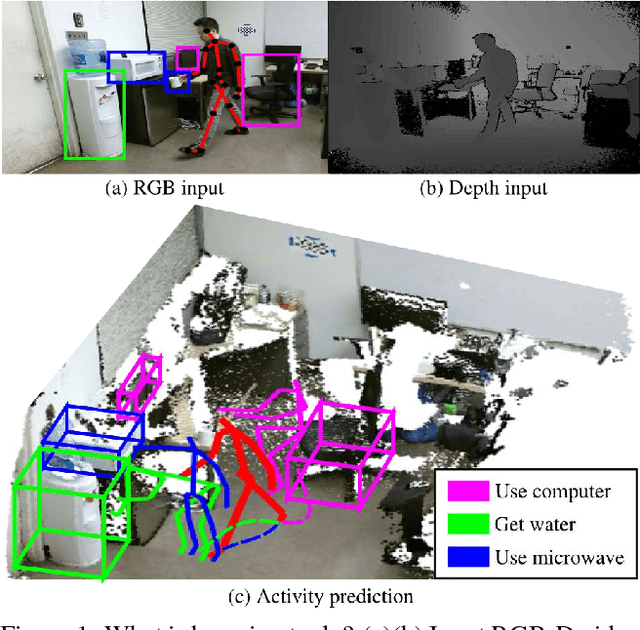
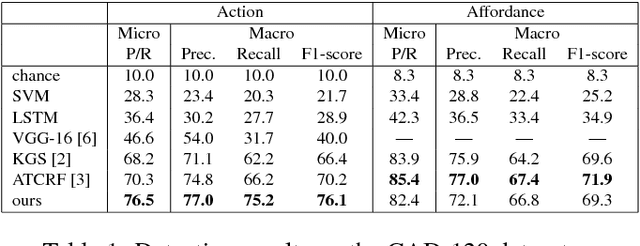
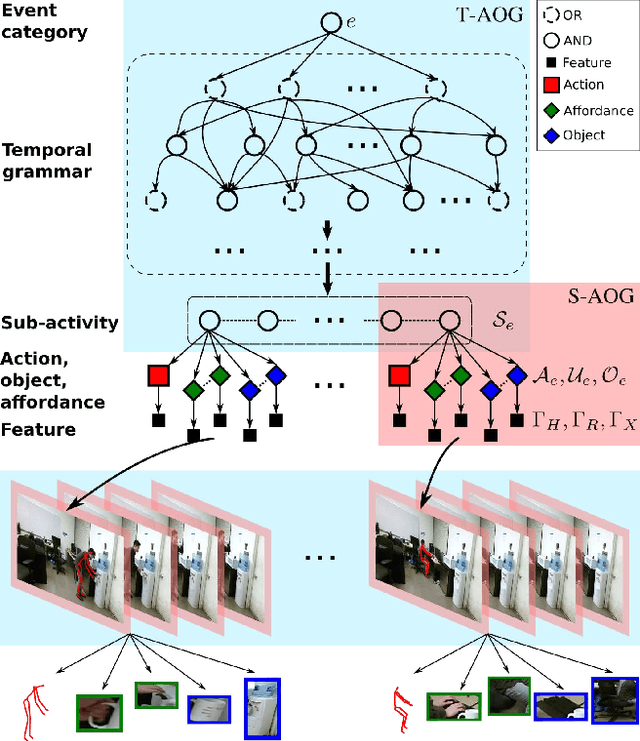
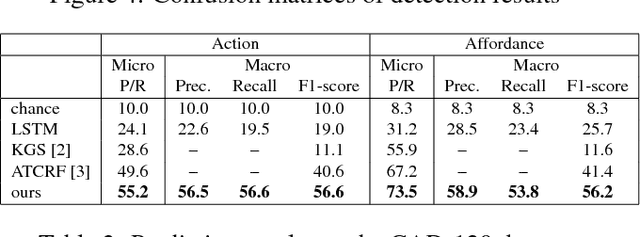
This paper presents a novel method to predict future human activities from partially observed RGB-D videos. Human activity prediction is generally difficult due to its non-Markovian property and the rich context between human and environments. We use a stochastic grammar model to capture the compositional structure of events, integrating human actions, objects, and their affordances. We represent the event by a spatial-temporal And-Or graph (ST-AOG). The ST-AOG is composed of a temporal stochastic grammar defined on sub-activities, and spatial graphs representing sub-activities that consist of human actions, objects, and their affordances. Future sub-activities are predicted using the temporal grammar and Earley parsing algorithm. The corresponding action, object, and affordance labels are then inferred accordingly. Extensive experiments are conducted to show the effectiveness of our model on both semantic event parsing and future activity prediction.