 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQingqing Zhu
Decomposing Vision-based LLM Predictions for Auto-Evaluation with GPT-4
Mar 08, 2024
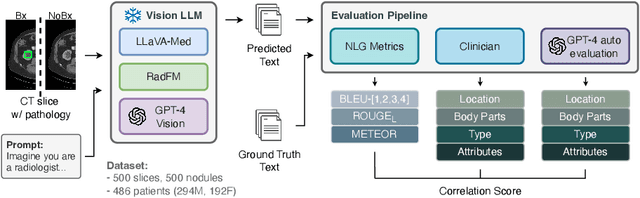

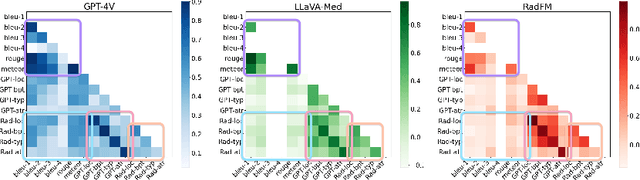
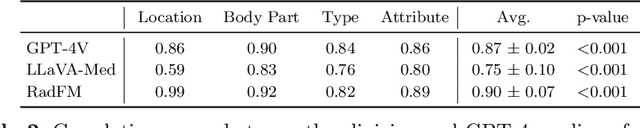
The volume of CT exams being done in the world has been rising every year, which has led to radiologist burn-out. Large Language Models (LLMs) have the potential to reduce their burden, but their adoption in the clinic depends on radiologist trust, and easy evaluation of generated content. Presently, many automated methods are available to evaluate the reports generated for chest radiographs, but such an approach is not available for CT presently. In this paper, we propose a novel evaluation framework to judge the capabilities of vision-language LLMs in generating accurate summaries of CT-based abnormalities. CT slices containing an abnormality (e.g., lesion) were input to a vision-based LLM (GPT-4V, LLaVA-Med, and RadFM), and it generated a free-text summary of the predicted characteristics of the abnormality. Next, a GPT-4 model decomposed the summary into specific aspects (body part, location, type, and attributes), automatically evaluated the characteristics against the ground-truth, and generated a score for each aspect based on its clinical relevance and factual accuracy. These scores were then contrasted against those obtained from a clinician, and a high correlation ( 85%, p < .001) was observed. Although GPT-4V outperformed other models in our evaluation, it still requires overall improvement. Our evaluation method offers valuable insights into the specific areas that need the most enhancement, guiding future development in this field.
Rethinking Scientific Summarization Evaluation: Grounding Explainable Metrics on Facet-aware Benchmark
Feb 22, 2024The summarization capabilities of pretrained and large language models (LLMs) have been widely validated in general areas, but their use in scientific corpus, which involves complex sentences and specialized knowledge, has been less assessed. This paper presents conceptual and experimental analyses of scientific summarization, highlighting the inadequacies of traditional evaluation methods, such as $n$-gram, embedding comparison, and QA, particularly in providing explanations, grasping scientific concepts, or identifying key content. Subsequently, we introduce the Facet-aware Metric (FM), employing LLMs for advanced semantic matching to evaluate summaries based on different aspects. This facet-aware approach offers a thorough evaluation of abstracts by decomposing the evaluation task into simpler subtasks.Recognizing the absence of an evaluation benchmark in this domain, we curate a Facet-based scientific summarization Dataset (FD) with facet-level annotations. Our findings confirm that FM offers a more logical approach to evaluating scientific summaries. In addition, fine-tuned smaller models can compete with LLMs in scientific contexts, while LLMs have limitations in learning from in-context information in scientific domains. This suggests an area for future enhancement of LLMs.
AgentMD: Empowering Language Agents for Risk Prediction with Large-Scale Clinical Tool Learning
Feb 20, 2024Clinical calculators play a vital role in healthcare by offering accurate evidence-based predictions for various purposes such as prognosis. Nevertheless, their widespread utilization is frequently hindered by usability challenges, poor dissemination, and restricted functionality. Augmenting large language models with extensive collections of clinical calculators presents an opportunity to overcome these obstacles and improve workflow efficiency, but the scalability of the manual curation process poses a significant challenge. In response, we introduce AgentMD, a novel language agent capable of curating and applying clinical calculators across various clinical contexts. Using the published literature, AgentMD has automatically curated a collection of 2,164 diverse clinical calculators with executable functions and structured documentation, collectively named RiskCalcs. Manual evaluations show that RiskCalcs tools achieve an accuracy of over 80% on three quality metrics. At inference time, AgentMD can automatically select and apply the relevant RiskCalcs tools given any patient description. On the newly established RiskQA benchmark, AgentMD significantly outperforms chain-of-thought prompting with GPT-4 (87.7% vs. 40.9% in accuracy). Additionally, we also applied AgentMD to real-world clinical notes for analyzing both population-level and risk-level patient characteristics. In summary, our study illustrates the utility of language agents augmented with clinical calculators for healthcare analytics and patient care.
Leveraging Professional Radiologists' Expertise to Enhance LLMs' Evaluation for Radiology Reports
Feb 02, 2024In radiology, Artificial Intelligence (AI) has significantly advanced report generation, but automatic evaluation of these AI-produced reports remains challenging. Current metrics, such as Conventional Natural Language Generation (NLG) and Clinical Efficacy (CE), often fall short in capturing the semantic intricacies of clinical contexts or overemphasize clinical details, undermining report clarity. To overcome these issues, our proposed method synergizes the expertise of professional radiologists with Large Language Models (LLMs), like GPT-3.5 and GPT-4 1. Utilizing In-Context Instruction Learning (ICIL) and Chain of Thought (CoT) reasoning, our approach aligns LLM evaluations with radiologist standards, enabling detailed comparisons between human and AI generated reports. This is further enhanced by a Regression model that aggregates sentence evaluation scores. Experimental results show that our "Detailed GPT-4 (5-shot)" model achieves a 0.48 score, outperforming the METEOR metric by 0.19, while our "Regressed GPT-4" model shows even greater alignment with expert evaluations, exceeding the best existing metric by a 0.35 margin. Moreover, the robustness of our explanations has been validated through a thorough iterative strategy. We plan to publicly release annotations from radiology experts, setting a new standard for accuracy in future assessments. This underscores the potential of our approach in enhancing the quality assessment of AI-driven medical reports.
A scoping review on multimodal deep learning in biomedical images and texts
Jul 14, 2023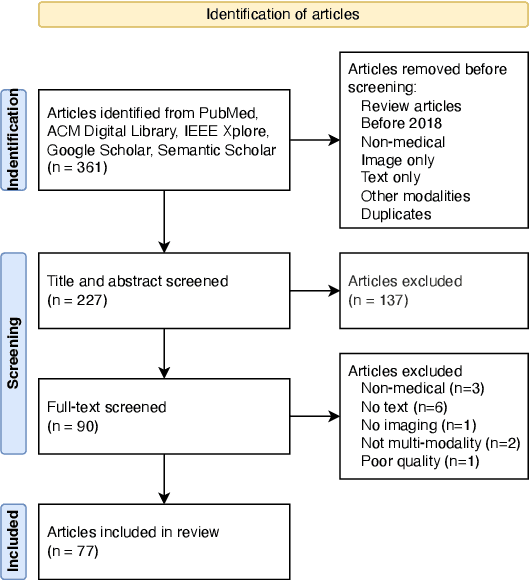
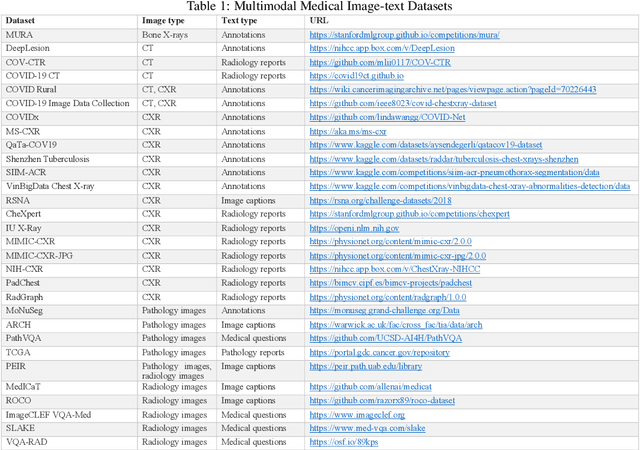
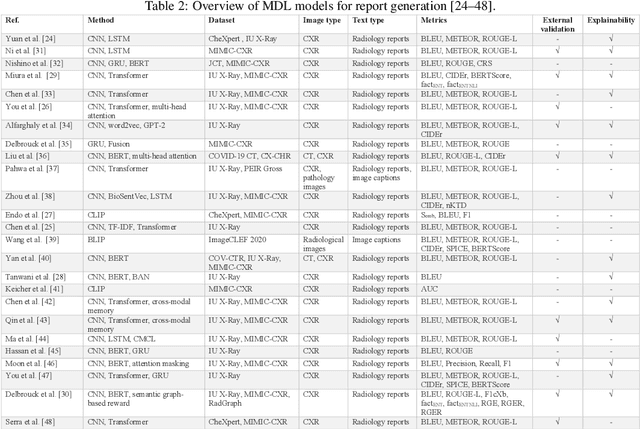
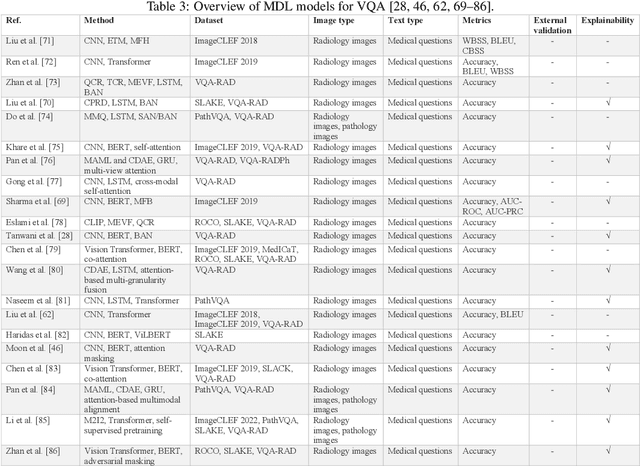
Computer-assisted diagnostic and prognostic systems of the future should be capable of simultaneously processing multimodal data. Multimodal deep learning (MDL), which involves the integration of multiple sources of data, such as images and text, has the potential to revolutionize the analysis and interpretation of biomedical data. However, it only caught researchers' attention recently. To this end, there is a critical need to conduct a systematic review on this topic, identify the limitations of current work, and explore future directions. In this scoping review, we aim to provide a comprehensive overview of the current state of the field and identify key concepts, types of studies, and research gaps with a focus on biomedical images and texts joint learning, mainly because these two were the most commonly available data types in MDL research. This study reviewed the current uses of multimodal deep learning on five tasks: (1) Report generation, (2) Visual question answering, (3) Cross-modal retrieval, (4) Computer-aided diagnosis, and (5) Semantic segmentation. Our results highlight the diverse applications and potential of MDL and suggest directions for future research in the field. We hope our review will facilitate the collaboration of natural language processing (NLP) and medical imaging communities and support the next generation of decision-making and computer-assisted diagnostic system development.
Opportunities and Challenges for ChatGPT and Large Language Models in Biomedicine and Health
Jun 15, 2023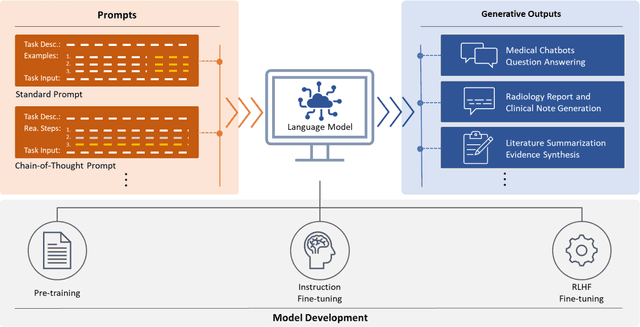
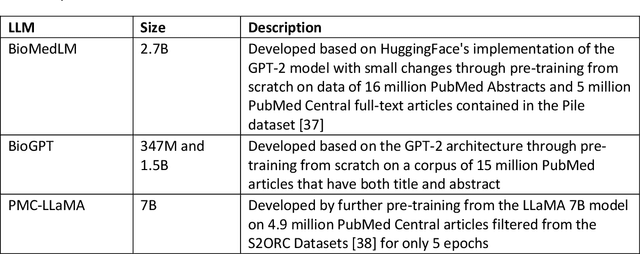
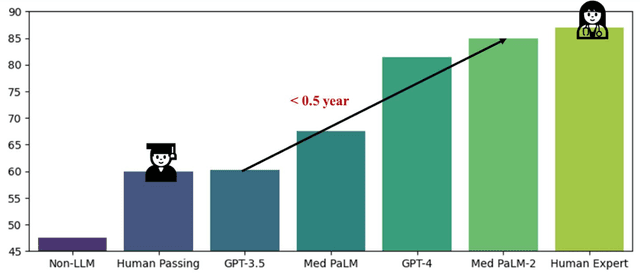
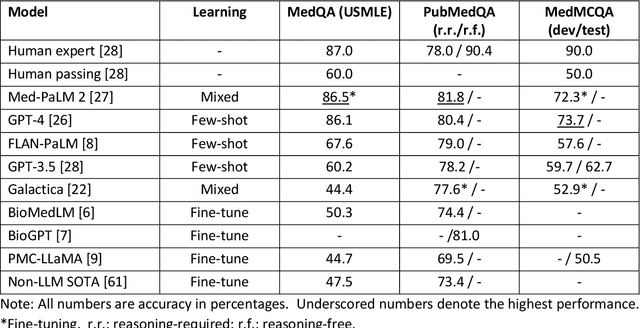
ChatGPT has drawn considerable attention from both the general public and domain experts with its remarkable text generation capabilities. This has subsequently led to the emergence of diverse applications in the field of biomedicine and health. In this work, we examine the diverse applications of large language models (LLMs), such as ChatGPT, in biomedicine and health. Specifically we explore the areas of biomedical information retrieval, question answering, medical text summarization, information extraction, and medical education, and investigate whether LLMs possess the transformative power to revolutionize these tasks or whether the distinct complexities of biomedical domain presents unique challenges. Following an extensive literature survey, we find that significant advances have been made in the field of text generation tasks, surpassing the previous state-of-the-art methods. For other applications, the advances have been modest. Overall, LLMs have not yet revolutionized the biomedicine, but recent rapid progress indicates that such methods hold great potential to provide valuable means for accelerating discovery and improving health. We also find that the use of LLMs, like ChatGPT, in the fields of biomedicine and health entails various risks and challenges, including fabricated information in its generated responses, as well as legal and privacy concerns associated with sensitive patient data. We believe this first-of-its-kind survey can provide a comprehensive overview to biomedical researchers and healthcare practitioners on the opportunities and challenges associated with using ChatGPT and other LLMs for transforming biomedicine and health.
Utilizing Longitudinal Chest X-Rays and Reports to Pre-Fill Radiology Reports
Jun 14, 2023

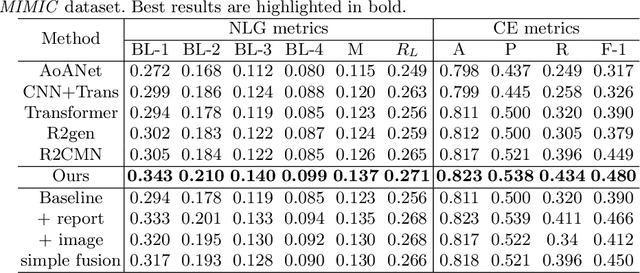

Despite the reduction in turn-around times in radiology reports with the use of speech recognition software, persistent communication errors can significantly impact the interpretation of the radiology report. Pre-filling a radiology report holds promise in mitigating reporting errors, and despite efforts in the literature to generate medical reports, there exists a lack of approaches that exploit the longitudinal nature of patient visit records in the MIMIC-CXR dataset. To address this gap, we propose to use longitudinal multi-modal data, i.e., previous patient visit CXR, current visit CXR, and previous visit report, to pre-fill the 'findings' section of a current patient visit report. We first gathered the longitudinal visit information for 26,625 patients from the MIMIC-CXR dataset and created a new dataset called Longitudinal-MIMIC. With this new dataset, a transformer-based model was trained to capture the information from longitudinal patient visit records containing multi-modal data (CXR images + reports) via a cross-attention-based multi-modal fusion module and a hierarchical memory-driven decoder. In contrast to previous work that only uses current visit data as input to train a model, our work exploits the longitudinal information available to pre-fill the 'findings' section of radiology reports. Experiments show that our approach outperforms several recent approaches by >=3% on F1 score, and >=2% for BLEU-4, METEOR and ROUGE-L respectively. The dataset and code will be made publicly available.
Interactive Natural Language Processing
May 22, 2023
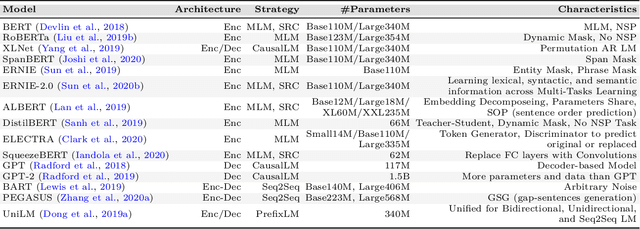
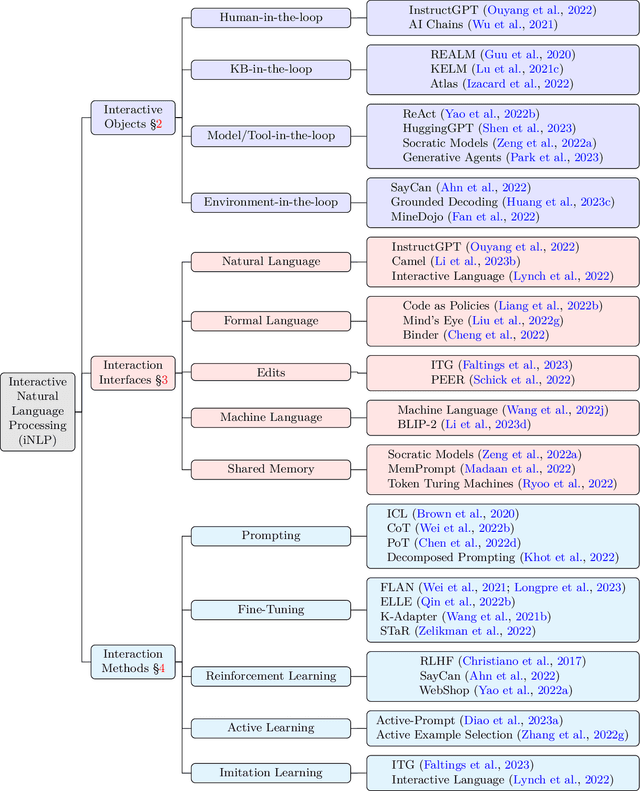
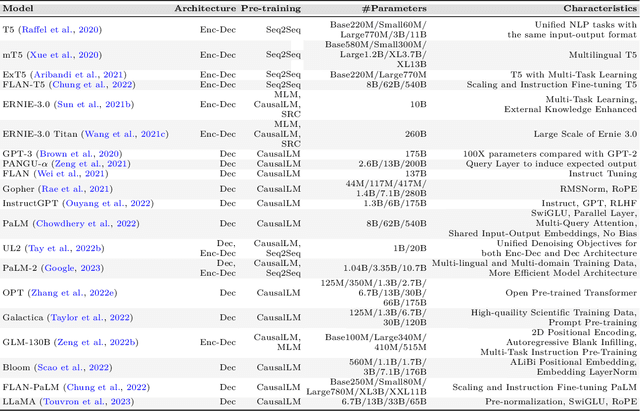
Interactive Natural Language Processing (iNLP) has emerged as a novel paradigm within the field of NLP, aimed at addressing limitations in existing frameworks while aligning with the ultimate goals of artificial intelligence. This paradigm considers language models as agents capable of observing, acting, and receiving feedback iteratively from external entities. Specifically, language models in this context can: (1) interact with humans for better understanding and addressing user needs, personalizing responses, aligning with human values, and improving the overall user experience; (2) interact with knowledge bases for enriching language representations with factual knowledge, enhancing the contextual relevance of responses, and dynamically leveraging external information to generate more accurate and informed responses; (3) interact with models and tools for effectively decomposing and addressing complex tasks, leveraging specialized expertise for specific subtasks, and fostering the simulation of social behaviors; and (4) interact with environments for learning grounded representations of language, and effectively tackling embodied tasks such as reasoning, planning, and decision-making in response to environmental observations. This paper offers a comprehensive survey of iNLP, starting by proposing a unified definition and framework of the concept. We then provide a systematic classification of iNLP, dissecting its various components, including interactive objects, interaction interfaces, and interaction methods. We proceed to delve into the evaluation methodologies used in the field, explore its diverse applications, scrutinize its ethical and safety issues, and discuss prospective research directions. This survey serves as an entry point for researchers who are interested in this rapidly evolving area and offers a broad view of the current landscape and future trajectory of iNLP.