 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRahul Sharma
Private Benchmarking to Prevent Contamination and Improve Comparative Evaluation of LLMs
Mar 01, 2024
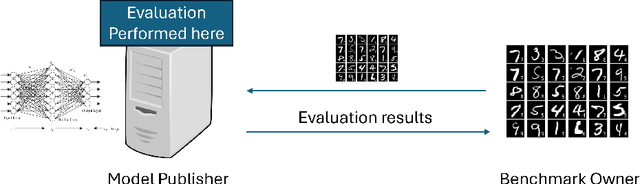

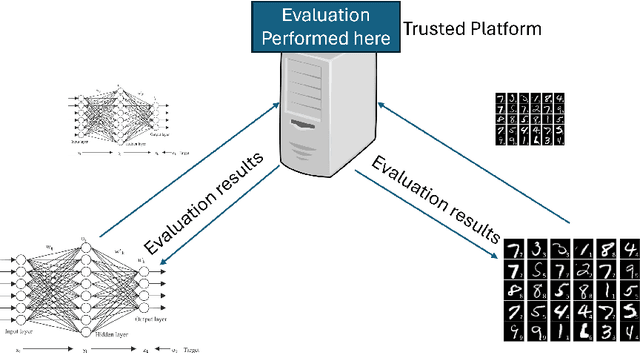
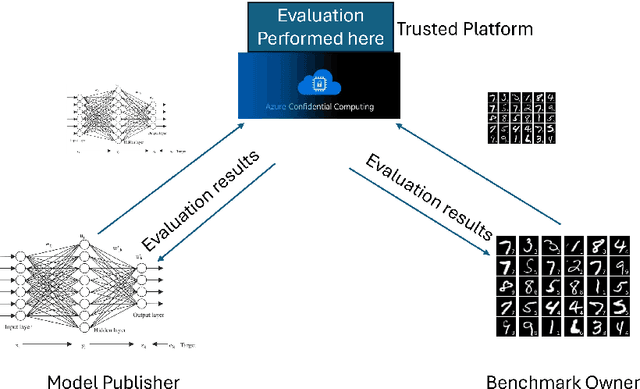
Benchmarking is the de-facto standard for evaluating LLMs, due to its speed, replicability and low cost. However, recent work has pointed out that the majority of the open source benchmarks available today have been contaminated or leaked into LLMs, meaning that LLMs have access to test data during pretraining and/or fine-tuning. This raises serious concerns about the validity of benchmarking studies conducted so far and the future of evaluation using benchmarks. To solve this problem, we propose Private Benchmarking, a solution where test datasets are kept private and models are evaluated without revealing the test data to the model. We describe various scenarios (depending on the trust placed on model owners or dataset owners), and present solutions to avoid data contamination using private benchmarking. For scenarios where the model weights need to be kept private, we describe solutions from confidential computing and cryptography that can aid in private benchmarking. Finally, we present solutions the problem of benchmark dataset auditing, to ensure that private benchmarks are of sufficiently high quality.
Evaluating Atypical Gaze Patterns through Vision Models: The Case of Cortical Visual Impairment
Feb 15, 2024A wide range of neurological and cognitive disorders exhibit distinct behavioral markers aside from their clinical manifestations. Cortical Visual Impairment (CVI) is a prime example of such conditions, resulting from damage to visual pathways in the brain, and adversely impacting low- and high-level visual function. The characteristics impacted by CVI are primarily described qualitatively, challenging the establishment of an objective, evidence-based measure of CVI severity. To study those characteristics, we propose to create visual saliency maps by adequately prompting deep vision models with attributes of clinical interest. After extracting saliency maps for a curated set of stimuli, we evaluate fixation traces on those from children with CVI through eye tracking technology. Our experiments reveal significant gaze markers that verify clinical knowledge and yield nuanced discriminability when compared to those of age-matched control subjects. Using deep learning to unveil atypical visual saliency is an important step toward establishing an eye-tracking signature for severe neurodevelopmental disorders, like CVI.
X Hacking: The Threat of Misguided AutoML
Jan 16, 2024Explainable AI (XAI) and interpretable machine learning methods help to build trust in model predictions and derived insights, yet also present a perverse incentive for analysts to manipulate XAI metrics to support pre-specified conclusions. This paper introduces the concept of X-hacking, a form of p-hacking applied to XAI metrics such as Shap values. We show how an automated machine learning pipeline can be used to search for 'defensible' models that produce a desired explanation while maintaining superior predictive performance to a common baseline. We formulate the trade-off between explanation and accuracy as a multi-objective optimization problem and illustrate the feasibility and severity of X-hacking empirically on familiar real-world datasets. Finally, we suggest possible methods for detection and prevention, and discuss ethical implications for the credibility and reproducibility of XAI research.
Finding Inductive Loop Invariants using Large Language Models
Nov 14, 2023Loop invariants are fundamental to reasoning about programs with loops. They establish properties about a given loop's behavior. When they additionally are inductive, they become useful for the task of formal verification that seeks to establish strong mathematical guarantees about program's runtime behavior. The inductiveness ensures that the invariants can be checked locally without consulting the entire program, thus are indispensable artifacts in a formal proof of correctness. Finding inductive loop invariants is an undecidable problem, and despite a long history of research towards practical solutions, it remains far from a solved problem. This paper investigates the capabilities of the Large Language Models (LLMs) in offering a new solution towards this old, yet important problem. To that end, we first curate a dataset of verification problems on programs with loops. Next, we design a prompt for exploiting LLMs, obtaining inductive loop invariants, that are checked for correctness using sound symbolic tools. Finally, we explore the effectiveness of using an efficient combination of a symbolic tool and an LLM on our dataset and compare it against a purely symbolic baseline. Our results demonstrate that LLMs can help improve the state-of-the-art in automated program verification.
Discretizing Numerical Attributes: An Analysis of Human Perceptions
Nov 06, 2023Machine learning (ML) has employed various discretization methods to partition numerical attributes into intervals. However, an effective discretization technique remains elusive in many ML applications, such as association rule mining. Moreover, the existing discretization techniques do not reflect best the impact of the independent numerical factor on the dependent numerical target factor. This research aims to establish a benchmark approach for numerical attribute partitioning. We conduct an extensive analysis of human perceptions of partitioning a numerical attribute and compare these perceptions with the results obtained from our two proposed measures. We also examine the perceptions of experts in data science, statistics, and engineering by employing numerical data visualization techniques. The analysis of collected responses reveals that $68.7\%$ of human responses approximately closely align with the values generated by our proposed measures. Based on these findings, our proposed measures may be used as one of the methods for discretizing the numerical attributes.
Ranking LLM-Generated Loop Invariants for Program Verification
Oct 18, 2023Synthesizing inductive loop invariants is fundamental to automating program verification. In this work, we observe that Large Language Models (such as gpt-3.5 or gpt-4) are capable of synthesizing loop invariants for a class of programs in a 0-shot setting, yet require several samples to generate the correct invariants. This can lead to a large number of calls to a program verifier to establish an invariant. To address this issue, we propose a {\it re-ranking} approach for the generated results of LLMs. We have designed a ranker that can distinguish between correct inductive invariants and incorrect attempts based on the problem definition. The ranker is optimized as a contrastive ranker. Experimental results demonstrate that this re-ranking mechanism significantly improves the ranking of correct invariants among the generated candidates, leading to a notable reduction in the number of calls to a verifier.
Numerical Association Rule Mining: A Systematic Literature Review
Jul 02, 2023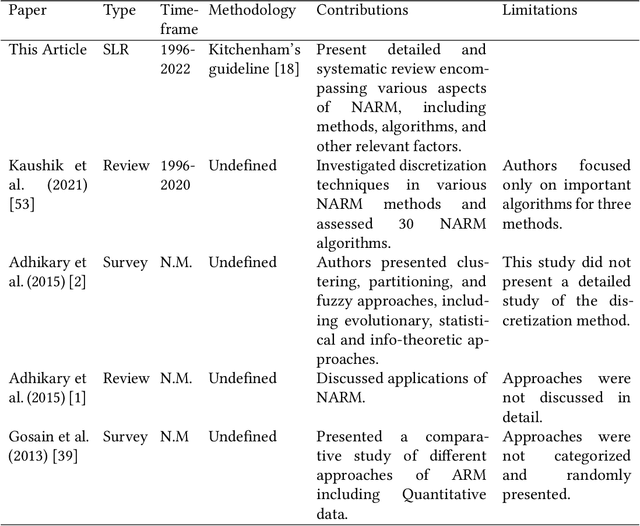
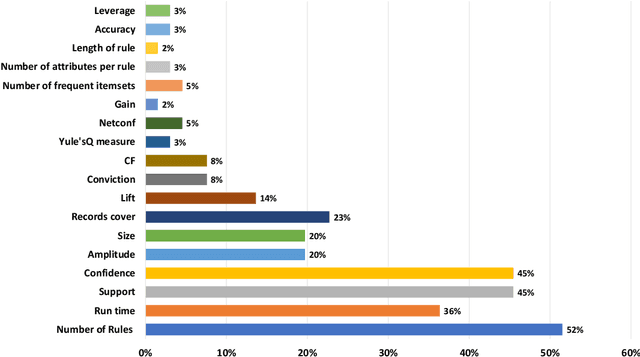
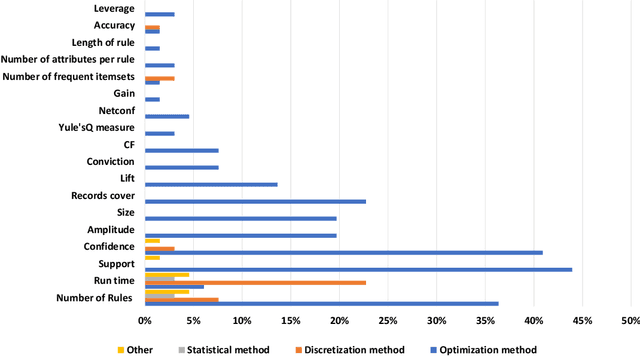
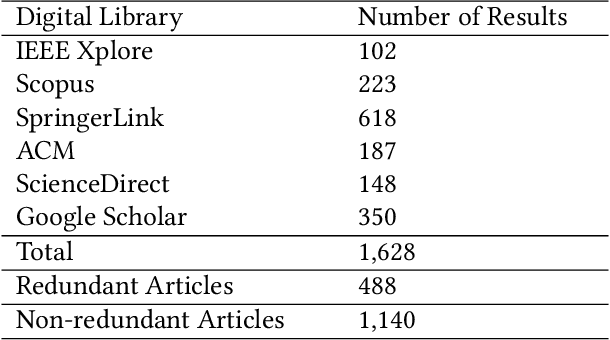
Numerical association rule mining is a widely used variant of the association rule mining technique, and it has been extensively used in discovering patterns and relationships in numerical data. Initially, researchers and scientists integrated numerical attributes in association rule mining using various discretization approaches; however, over time, a plethora of alternative methods have emerged in this field. Unfortunately, the increase of alternative methods has resulted into a significant knowledge gap in understanding diverse techniques employed in numerical association rule mining -- this paper attempts to bridge this knowledge gap by conducting a comprehensive systematic literature review. We provide an in-depth study of diverse methods, algorithms, metrics, and datasets derived from 1,140 scholarly articles published from the inception of numerical association rule mining in the year 1996 to 2022. In compliance with the inclusion, exclusion, and quality evaluation criteria, 68 papers were chosen to be extensively evaluated. To the best of our knowledge, this systematic literature review is the first of its kind to provide an exhaustive analysis of the current literature and previous surveys on numerical association rule mining. The paper discusses important research issues, the current status, and future possibilities of numerical association rule mining. On the basis of this systematic review, the article also presents a novel discretization measure that contributes by providing a partitioning of numerical data that meets well human perception of partitions.
Training with Mixed-Precision Floating-Point Assignments
Jan 31, 2023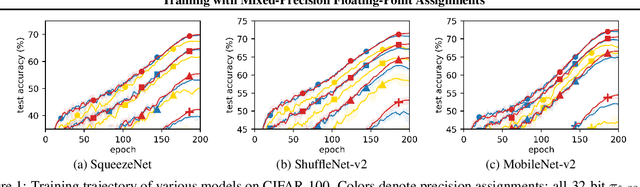
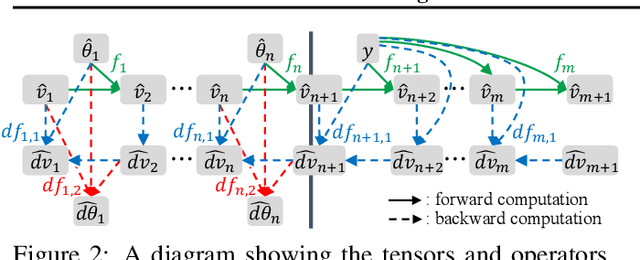
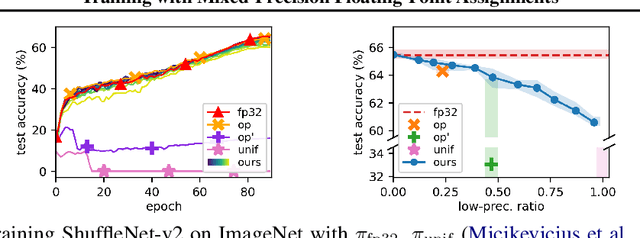
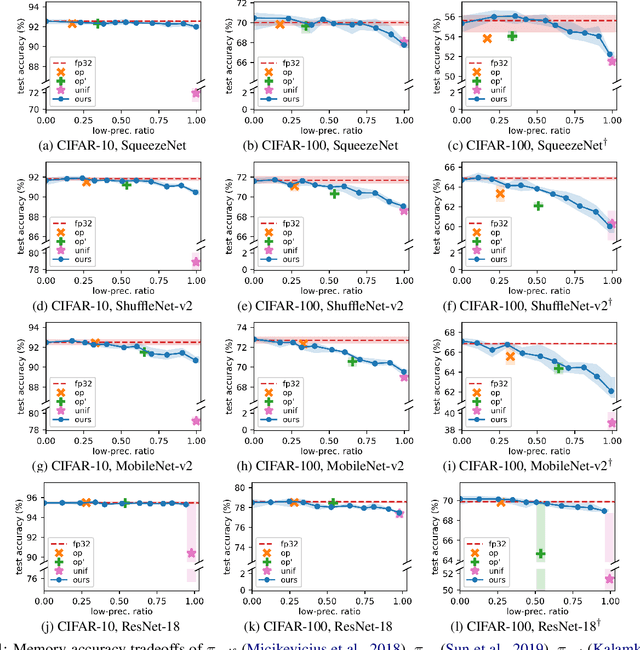
When training deep neural networks, keeping all tensors in high precision (e.g., 32-bit or even 16-bit floats) is often wasteful. However, keeping all tensors in low precision (e.g., 8-bit floats) can lead to unacceptable accuracy loss. Hence, it is important to use a precision assignment -- a mapping from all tensors (arising in training) to precision levels (high or low) -- that keeps most of the tensors in low precision and leads to sufficiently accurate models. We provide a technique that explores this memory-accuracy tradeoff by generating precision assignments that (i) use less memory and (ii) lead to more accurate models at the same time, compared to the precision assignments considered by prior work in low-precision floating-point training. Our method typically provides > 2x memory reduction over a baseline precision assignment while preserving training accuracy, and gives further reductions by trading off accuracy. Compared to other baselines which sometimes cause training to diverge, our method provides similar or better memory reduction while avoiding divergence.
Machine learning techniques for the Schizophrenia diagnosis: A comprehensive review and future research directions
Jan 16, 2023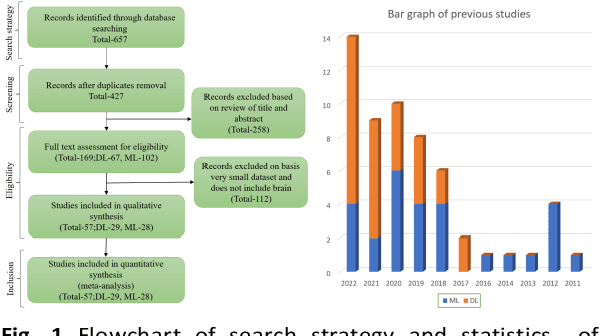
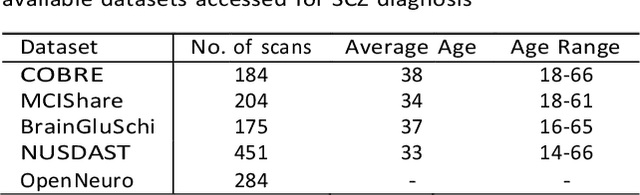
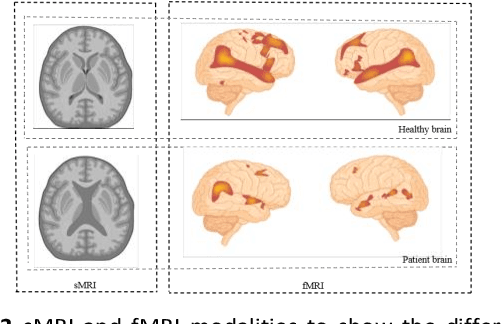
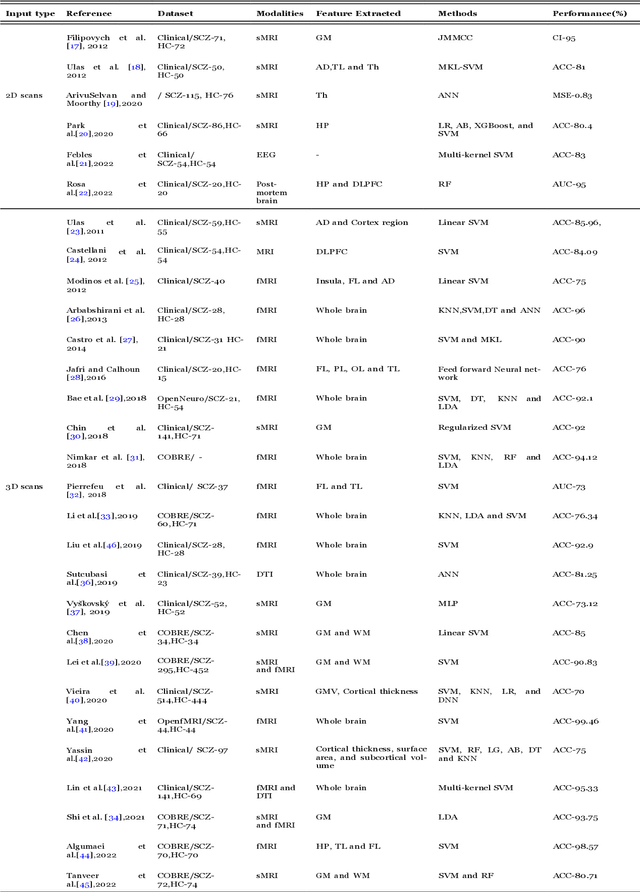
Schizophrenia (SCZ) is a brain disorder where different people experience different symptoms, such as hallucination, delusion, flat-talk, disorganized thinking, etc. In the long term, this can cause severe effects and diminish life expectancy by more than ten years. Therefore, early and accurate diagnosis of SCZ is prevalent, and modalities like structural magnetic resonance imaging (sMRI), functional MRI (fMRI), diffusion tensor imaging (DTI), and electroencephalogram (EEG) assist in witnessing the brain abnormalities of the patients. Moreover, for accurate diagnosis of SCZ, researchers have used machine learning (ML) algorithms for the past decade to distinguish the brain patterns of healthy and SCZ brains using MRI and fMRI images. This paper seeks to acquaint SCZ researchers with ML and to discuss its recent applications to the field of SCZ study. This paper comprehensively reviews state-of-the-art techniques such as ML classifiers, artificial neural network (ANN), deep learning (DL) models, methodological fundamentals, and applications with previous studies. The motivation of this paper is to benefit from finding the research gaps that may lead to the development of a new model for accurate SCZ diagnosis. The paper concludes with the research finding, followed by the future scope that directly contributes to new research directions.
Audio-Visual Activity Guided Cross-Modal Identity Association for Active Speaker Detection
Dec 01, 2022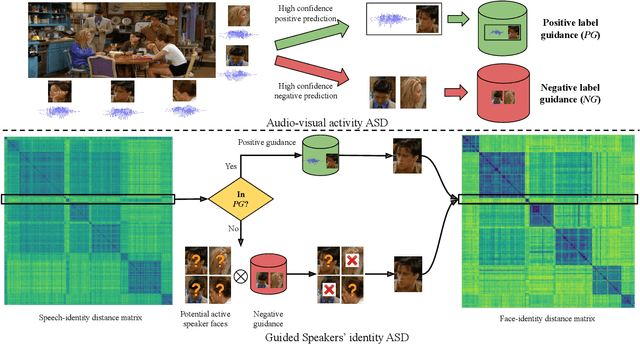
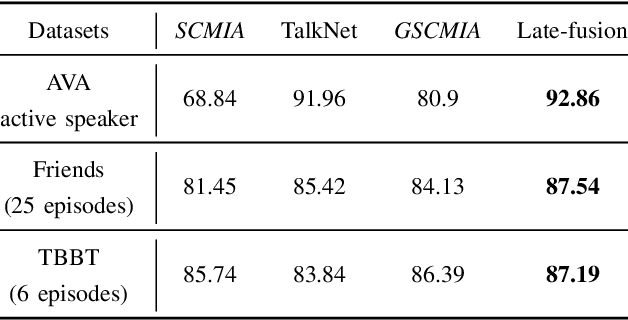
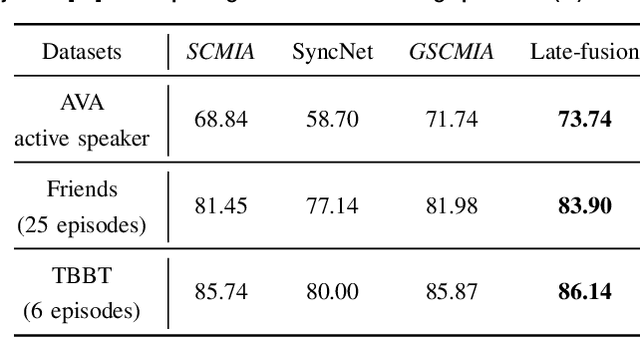
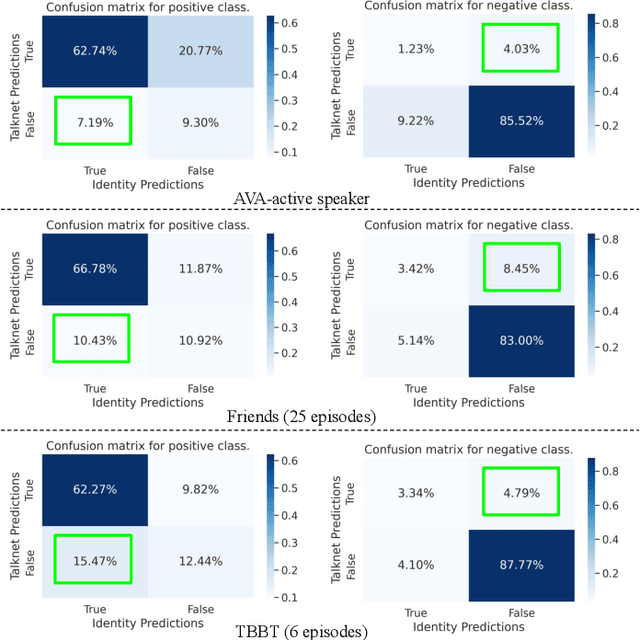
Active speaker detection in videos addresses associating a source face, visible in the video frames, with the underlying speech in the audio modality. The two primary sources of information to derive such a speech-face relationship are i) visual activity and its interaction with the speech signal and ii) co-occurrences of speakers' identities across modalities in the form of face and speech. The two approaches have their limitations: the audio-visual activity models get confused with other frequently occurring vocal activities, such as laughing and chewing, while the speakers' identity-based methods are limited to videos having enough disambiguating information to establish a speech-face association. Since the two approaches are independent, we investigate their complementary nature in this work. We propose a novel unsupervised framework to guide the speakers' cross-modal identity association with the audio-visual activity for active speaker detection. Through experiments on entertainment media videos from two benchmark datasets, the AVA active speaker (movies) and Visual Person Clustering Dataset (TV shows), we show that a simple late fusion of the two approaches enhances the active speaker detection performance.