 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSunayana Sitaram
METAL: Towards Multilingual Meta-Evaluation
Apr 02, 2024
With the rising human-like precision of Large Language Models (LLMs) in numerous tasks, their utilization in a variety of real-world applications is becoming more prevalent. Several studies have shown that LLMs excel on many standard NLP benchmarks. However, it is challenging to evaluate LLMs due to test dataset contamination and the limitations of traditional metrics. Since human evaluations are difficult to collect, there is a growing interest in the community to use LLMs themselves as reference-free evaluators for subjective metrics. However, past work has shown that LLM-based evaluators can exhibit bias and have poor alignment with human judgments. In this study, we propose a framework for an end-to-end assessment of LLMs as evaluators in multilingual scenarios. We create a carefully curated dataset, covering 10 languages containing native speaker judgments for the task of summarization. This dataset is created specifically to evaluate LLM-based evaluators, which we refer to as meta-evaluation (METAL). We compare the performance of LLM-based evaluators created using GPT-3.5-Turbo, GPT-4, and PaLM2. Our results indicate that LLM-based evaluators based on GPT-4 perform the best across languages, while GPT-3.5-Turbo performs poorly. Additionally, we perform an analysis of the reasoning provided by LLM-based evaluators and find that it often does not match the reasoning provided by human judges.
Private Benchmarking to Prevent Contamination and Improve Comparative Evaluation of LLMs
Mar 01, 2024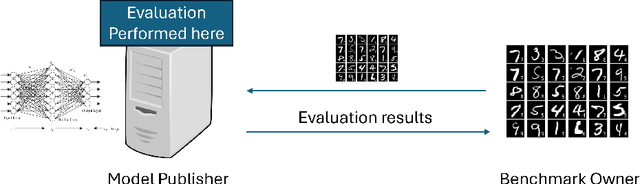

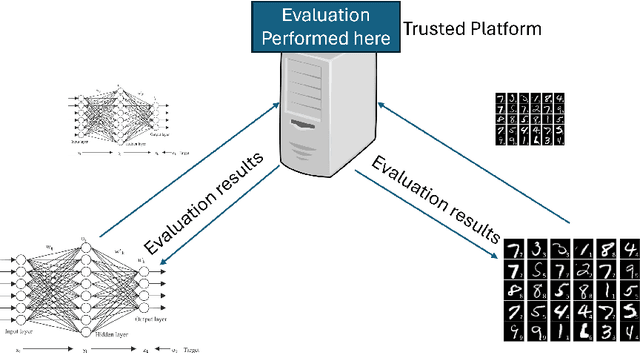
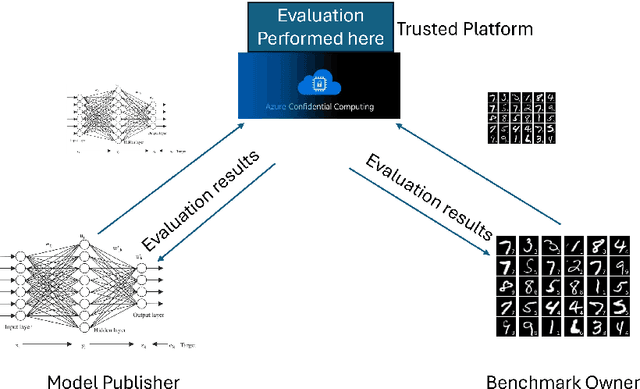
Benchmarking is the de-facto standard for evaluating LLMs, due to its speed, replicability and low cost. However, recent work has pointed out that the majority of the open source benchmarks available today have been contaminated or leaked into LLMs, meaning that LLMs have access to test data during pretraining and/or fine-tuning. This raises serious concerns about the validity of benchmarking studies conducted so far and the future of evaluation using benchmarks. To solve this problem, we propose Private Benchmarking, a solution where test datasets are kept private and models are evaluated without revealing the test data to the model. We describe various scenarios (depending on the trust placed on model owners or dataset owners), and present solutions to avoid data contamination using private benchmarking. For scenarios where the model weights need to be kept private, we describe solutions from confidential computing and cryptography that can aid in private benchmarking. Finally, we present solutions the problem of benchmark dataset auditing, to ensure that private benchmarks are of sufficiently high quality.
A Unified Framework and Dataset for Assessing Gender Bias in Vision-Language Models
Feb 21, 2024Large vision-language models (VLMs) are widely getting adopted in industry and academia. In this work we build a unified framework to systematically evaluate gender-profession bias in VLMs. Our evaluation encompasses all supported inference modes of the recent VLMs, including image-to-text, text-to-text, text-to-image, and image-to-image. We construct a synthetic, high-quality dataset of text and images that blurs gender distinctions across professional actions to benchmark gender bias. In our benchmarking of recent vision-language models (VLMs), we observe that different input-output modalities result in distinct bias magnitudes and directions. We hope our work will help guide future progress in improving VLMs to learn socially unbiased representations. We will release our data and code.
MAFIA: Multi-Adapter Fused Inclusive LanguAge Models
Feb 12, 2024Pretrained Language Models (PLMs) are widely used in NLP for various tasks. Recent studies have identified various biases that such models exhibit and have proposed methods to correct these biases. However, most of the works address a limited set of bias dimensions independently such as gender, race, or religion. Moreover, the methods typically involve finetuning the full model to maintain the performance on the downstream task. In this work, we aim to modularly debias a pretrained language model across multiple dimensions. Previous works extensively explored debiasing PLMs using limited US-centric counterfactual data augmentation (CDA). We use structured knowledge and a large generative model to build a diverse CDA across multiple bias dimensions in a semi-automated way. We highlight how existing debiasing methods do not consider interactions between multiple societal biases and propose a debiasing model that exploits the synergy amongst various societal biases and enables multi-bias debiasing simultaneously. An extensive evaluation on multiple tasks and languages demonstrates the efficacy of our approach.
CultureLLM: Incorporating Cultural Differences into Large Language Models
Feb 09, 2024Large language models (LLMs) are reported to be partial to certain cultures owing to the training data dominance from the English corpora. Since multilingual cultural data are often expensive to collect, existing efforts handle this by prompt engineering or culture-specific pre-training. However, they might overlook the knowledge deficiency of low-resource culture and require extensive computing resources. In this paper, we propose CultureLLM, a cost-effective solution to incorporate cultural differences into LLMs. CultureLLM adopts World Value Survey (WVS) as seed data and generates semantically equivalent training data via the proposed semantic data augmentation. Using only 50 seed samples from WVS with augmented data, we fine-tune culture-specific LLMs and one unified model (CultureLLM-One) for 9 cultures covering rich and low-resource languages. Extensive experiments on 60 culture-related datasets demonstrate that CultureLLM significantly outperforms various counterparts such as GPT-3.5 (by 8.1%) and Gemini Pro (by 9.5%) with comparable performance to GPT-4 or even better. Our human study shows that the generated samples are semantically equivalent to the original samples, providing an effective solution for LLMs augmentation.
MAPLE: Multilingual Evaluation of Parameter Efficient Finetuning of Large Language Models
Jan 15, 2024Parameter efficient finetuning has emerged as a viable solution for improving the performance of Large Language Models without requiring massive resources and compute. Prior work on multilingual evaluation has shown that there is a large gap between the performance of LLMs on English and other languages. Further, there is also a large gap between the performance of smaller open-source models and larger LLMs. Finetuning can be an effective way to bridge this gap and make language models more equitable. In this work, we finetune the LLaMA-7B and Mistral-7B models on synthetic multilingual instruction tuning data to determine its effect on model performance on five downstream tasks covering twenty three languages in all. Additionally, we experiment with various parameters, such as rank for low-rank adaptation and values of quantisation to determine their effects on downstream performance and find that higher rank and higher quantisation values benefit low-resource languages. We find that parameter efficient finetuning of smaller open source models sometimes bridges the gap between the performance of these models and the larger ones, however, English performance can take a hit. We also find that finetuning sometimes improves performance on low-resource languages, while degrading performance on high-resource languages.
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Nov 13, 2023Recently, there has been a rapid advancement in research on Large Language Models (LLMs), resulting in significant progress in several Natural Language Processing (NLP) tasks. Consequently, there has been a surge in LLM evaluation research to comprehend the models' capabilities and limitations. However, much of this research has been confined to the English language, leaving LLM building and evaluation for non-English languages relatively unexplored. There has been an introduction of several new LLMs, necessitating their evaluation on non-English languages. This study aims to expand our MEGA benchmarking suite by including six new datasets to form the MEGAVERSE benchmark. The benchmark comprises 22 datasets covering 81 languages, including low-resource African languages. We evaluate several state-of-the-art LLMs like GPT-3.5-Turbo, GPT4, PaLM2, and Llama2 on the MEGAVERSE datasets. Additionally, we include two multimodal datasets in the benchmark and assess the performance of the LLaVa-v1.5 model. Our experiments suggest that GPT4 and PaLM2 outperform the Llama models on various tasks, notably on low-resource languages, with GPT4 outperforming PaLM2 on more datasets than vice versa. However, issues such as data contamination must be addressed to obtain an accurate assessment of LLM performance on non-English languages.
Representativeness as a Forgotten Lesson for Multilingual and Code-switched Data Collection and Preparation
Oct 31, 2023Multilingualism is widespread around the world and code-switching (CSW) is a common practice among different language pairs/tuples across locations and regions. However, there is still not much progress in building successful CSW systems, despite the recent advances in Massive Multilingual Language Models (MMLMs). We investigate the reasons behind this setback through a critical study about the existing CSW data sets (68) across language pairs in terms of the collection and preparation (e.g. transcription and annotation) stages. This in-depth analysis reveals that \textbf{a)} most CSW data involves English ignoring other language pairs/tuples \textbf{b)} there are flaws in terms of representativeness in data collection and preparation stages due to ignoring the location based, socio-demographic and register variation in CSW. In addition, lack of clarity on the data selection and filtering stages shadow the representativeness of CSW data sets. We conclude by providing a short check-list to improve the representativeness for forthcoming studies involving CSW data collection and preparation.
Partial Rank Similarity Minimization Method for Quality MOS Prediction of Unseen Speech Synthesis Systems in Zero-Shot and Semi-supervised setting
Oct 08, 2023This paper introduces a novel objective function for quality mean opinion score (MOS) prediction of unseen speech synthesis systems. The proposed function measures the similarity of relative positions of predicted MOS values, in a mini-batch, rather than the actual MOS values. That is the partial rank similarity is measured (PRS) rather than the individual MOS values as with the L1 loss. Our experiments on out-of-domain speech synthesis systems demonstrate that the PRS outperforms L1 loss in zero-shot and semi-supervised settings, exhibiting stronger correlation with ground truth. These findings highlight the importance of considering rank order, as done by PRS, when training MOS prediction models. We also argue that mean squared error and linear correlation coefficient metrics may be unreliable for evaluating MOS prediction models. In conclusion, PRS-trained models provide a robust framework for evaluating speech quality and offer insights for developing high-quality speech synthesis systems. Code and models are available at github.com/nii-yamagishilab/partial_rank_similarity/
Are Large Language Model-based Evaluators the Solution to Scaling Up Multilingual Evaluation?
Sep 14, 2023Large Language Models (LLMs) have demonstrated impressive performance on Natural Language Processing (NLP) tasks, such as Question Answering, Summarization, and Classification. The use of LLMs as evaluators, that can rank or score the output of other models (usually LLMs) has become increasingly popular, due to the limitations of current evaluation techniques including the lack of appropriate benchmarks, metrics, cost, and access to human annotators. While LLMs are capable of handling approximately 100 languages, the majority of languages beyond the top 20 lack systematic evaluation across various tasks, metrics, and benchmarks. This creates an urgent need to scale up multilingual evaluation to ensure a precise understanding of LLM performance across diverse languages. LLM-based evaluators seem like the perfect solution to this problem, as they do not require human annotators, human-created references, or benchmarks and can theoretically be used to evaluate any language covered by the LLM. In this paper, we investigate whether LLM-based evaluators can help scale up multilingual evaluation. Specifically, we calibrate LLM-based evaluation against 20k human judgments of five metrics across three text-generation tasks in eight languages. Our findings indicate that LLM-based evaluators may exhibit bias towards higher scores and should be used with caution and should always be calibrated with a dataset of native speaker judgments, particularly in low-resource and non-Latin script languages.