 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRichard E. Turner
Aardvark Weather: end-to-end data-driven weather forecasting
Mar 30, 2024
Machine learning is revolutionising medium-range weather prediction. However it has only been applied to specific and individual components of the weather prediction pipeline. Consequently these data-driven approaches are unable to be deployed without input from conventional operational numerical weather prediction (NWP) systems, which is computationally costly and does not support end-to-end optimisation. In this work, we take a radically different approach and replace the entire NWP pipeline with a machine learning model. We present Aardvark Weather, the first end-to-end data-driven forecasting system which takes raw observations as input and provides both global and local forecasts. These global forecasts are produced for 24 variables at multiple pressure levels at one-degree spatial resolution and 24 hour temporal resolution, and are skillful with respect to hourly climatology at five to seven day lead times. Local forecasts are produced for temperature, mean sea level pressure, and wind speed at a geographically diverse set of weather stations, and are skillful with respect to an IFS-HRES interpolation baseline at multiple lead-times. Aardvark, by virtue of its simplicity and scalability, opens the door to a new paradigm for performing accurate and efficient data-driven medium-range weather forecasting.
A Generative Model of Symmetry Transformations
Mar 04, 2024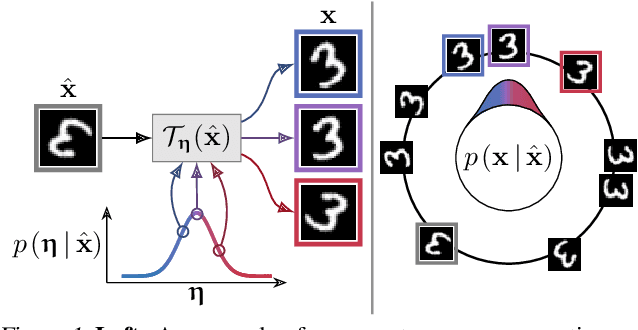
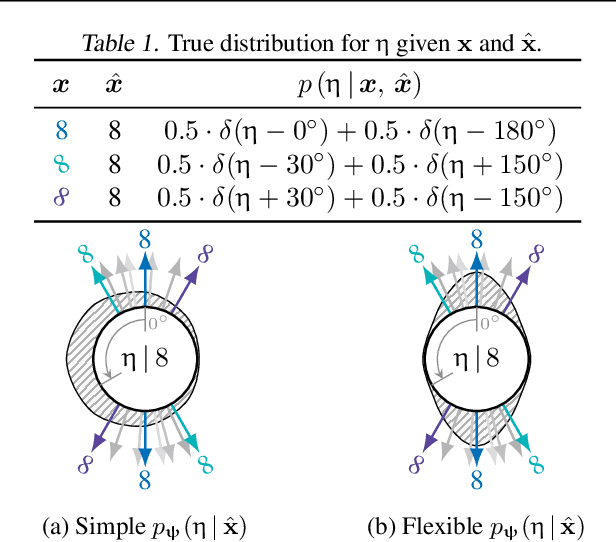
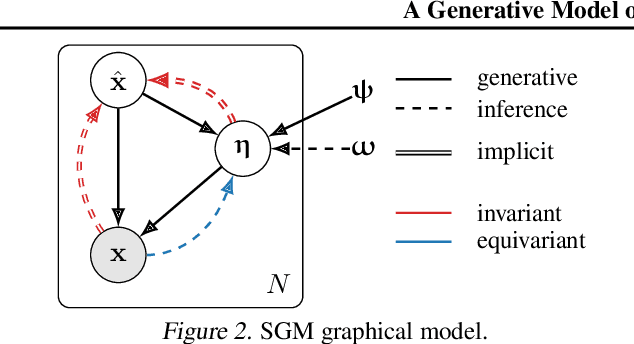
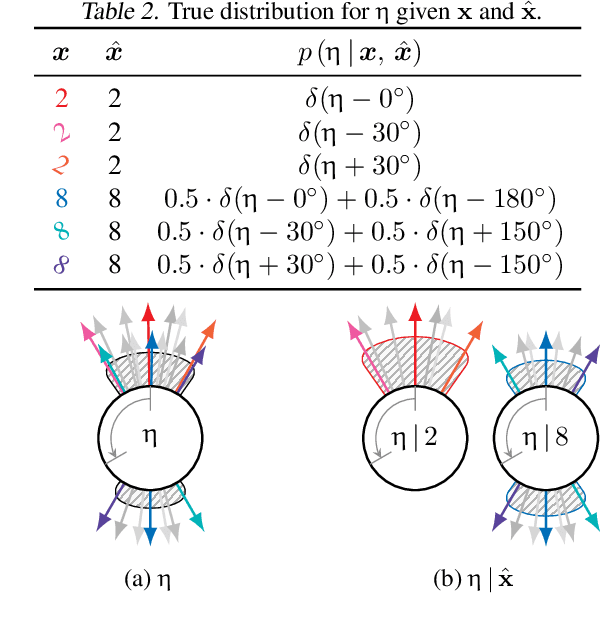
Correctly capturing the symmetry transformations of data can lead to efficient models with strong generalization capabilities, though methods incorporating symmetries often require prior knowledge. While recent advancements have been made in learning those symmetries directly from the dataset, most of this work has focused on the discriminative setting. In this paper, we construct a generative model that explicitly aims to capture symmetries in the data, resulting in a model that learns which symmetries are present in an interpretable way. We provide a simple algorithm for efficiently learning our generative model and demonstrate its ability to capture symmetries under affine and color transformations. Combining our symmetry model with existing generative models results in higher marginal test-log-likelihoods and robustness to data sparsification.
Can We Remove the Square-Root in Adaptive Gradient Methods? A Second-Order Perspective
Feb 13, 2024Adaptive gradient optimizers like Adam(W) are the default training algorithms for many deep learning architectures, such as transformers. Their diagonal preconditioner is based on the gradient outer product which is incorporated into the parameter update via a square root. While these methods are often motivated as approximate second-order methods, the square root represents a fundamental difference. In this work, we investigate how the behavior of adaptive methods changes when we remove the root, i.e. strengthen their second-order motivation. Surprisingly, we find that such square-root-free adaptive methods close the generalization gap to SGD on convolutional architectures, while maintaining their root-based counterpart's performance on transformers. The second-order perspective also has practical benefits for the development of adaptive methods with non-diagonal preconditioner. In contrast to root-based counterparts like Shampoo, they do not require numerically unstable matrix square roots and therefore work well in low precision, which we demonstrate empirically. This raises important questions regarding the currently overlooked role of adaptivity for the success of adaptive methods since the success is often attributed to sign descent induced by the root.
Denoising Diffusion Probabilistic Models in Six Simple Steps
Feb 10, 2024Denoising Diffusion Probabilistic Models (DDPMs) are a very popular class of deep generative model that have been successfully applied to a diverse range of problems including image and video generation, protein and material synthesis, weather forecasting, and neural surrogates of partial differential equations. Despite their ubiquity it is hard to find an introduction to DDPMs which is simple, comprehensive, clean and clear. The compact explanations necessary in research papers are not able to elucidate all of the different design steps taken to formulate the DDPM and the rationale of the steps that are presented is often omitted to save space. Moreover, the expositions are typically presented from the variational lower bound perspective which is unnecessary and arguably harmful as it obfuscates why the method is working and suggests generalisations that do not perform well in practice. On the other hand, perspectives that take the continuous time-limit are beautiful and general, but they have a high barrier-to-entry as they require background knowledge of stochastic differential equations and probability flow. In this note, we distill down the formulation of the DDPM into six simple steps each of which comes with a clear rationale. We assume that the reader is familiar with fundamental topics in machine learning including basic probabilistic modelling, Gaussian distributions, maximum likelihood estimation, and deep learning.
Transformer Neural Autoregressive Flows
Jan 03, 2024Density estimation, a central problem in machine learning, can be performed using Normalizing Flows (NFs). NFs comprise a sequence of invertible transformations, that turn a complex target distribution into a simple one, by exploiting the change of variables theorem. Neural Autoregressive Flows (NAFs) and Block Neural Autoregressive Flows (B-NAFs) are arguably the most perfomant members of the NF family. However, they suffer scalability issues and training instability due to the constraints imposed on the network structure. In this paper, we propose a novel solution to these challenges by exploiting transformers to define a new class of neural flows called Transformer Neural Autoregressive Flows (T-NAFs). T-NAFs treat each dimension of a random variable as a separate input token, using attention masking to enforce an autoregressive constraint. We take an amortization-inspired approach where the transformer outputs the parameters of an invertible transformation. The experimental results demonstrate that T-NAFs consistently match or outperform NAFs and B-NAFs across multiple datasets from the UCI benchmark. Remarkably, T-NAFs achieve these results using an order of magnitude fewer parameters than previous approaches, without composing multiple flows.
Structured Inverse-Free Natural Gradient: Memory-Efficient & Numerically-Stable KFAC for Large Neural Nets
Dec 16, 2023Second-order methods for deep learning -- such as KFAC -- can be useful for neural net training. However, they are often memory-inefficient and numerically unstable for low-precision training since their preconditioning Kronecker factors are dense, and require high-precision matrix inversion or decomposition. Consequently, such methods are not widely used for training large neural networks such as transformer-based models. We address these two issues by (i) formulating an inverse-free update of KFAC and (ii) imposing structures in each of the Kronecker factors, resulting in a method we term structured inverse-free natural gradient descent (SINGD). On large modern neural networks, we show that, in contrast to KFAC, SINGD is memory efficient and numerically robust, and often outperforms AdamW even in half precision. Hence, our work closes a gap between first-order and second-order methods in modern low precision training for large neural nets.
Identifiable Feature Learning for Spatial Data with Nonlinear ICA
Nov 28, 2023Recently, nonlinear ICA has surfaced as a popular alternative to the many heuristic models used in deep representation learning and disentanglement. An advantage of nonlinear ICA is that a sophisticated identifiability theory has been developed; in particular, it has been proven that the original components can be recovered under sufficiently strong latent dependencies. Despite this general theory, practical nonlinear ICA algorithms have so far been mainly limited to data with one-dimensional latent dependencies, especially time-series data. In this paper, we introduce a new nonlinear ICA framework that employs $t$-process (TP) latent components which apply naturally to data with higher-dimensional dependency structures, such as spatial and spatio-temporal data. In particular, we develop a new learning and inference algorithm that extends variational inference methods to handle the combination of a deep neural network mixing function with the TP prior, and employs the method of inducing points for computational efficacy. On the theoretical side, we show that such TP independent components are identifiable under very general conditions. Further, Gaussian Process (GP) nonlinear ICA is established as a limit of the TP Nonlinear ICA model, and we prove that the identifiability of the latent components at this GP limit is more restricted. Namely, those components are identifiable if and only if they have distinctly different covariance kernels. Our algorithm and identifiability theorems are explored on simulated spatial data and real world spatio-temporal data.
Diffusion-Augmented Neural Processes
Nov 16, 2023Over the last few years, Neural Processes have become a useful modelling tool in many application areas, such as healthcare and climate sciences, in which data are scarce and prediction uncertainty estimates are indispensable. However, the current state of the art in the field (AR CNPs; Bruinsma et al., 2023) presents a few issues that prevent its widespread deployment. This work proposes an alternative, diffusion-based approach to NPs which, through conditioning on noised datasets, addresses many of these limitations, whilst also exceeding SOTA performance.
Kronecker-Factored Approximate Curvature for Modern Neural Network Architectures
Nov 01, 2023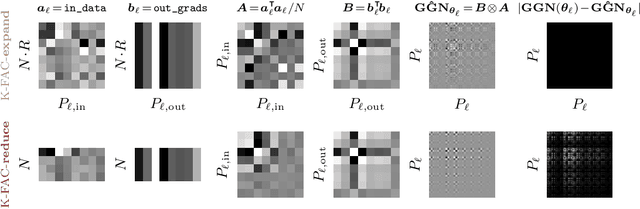
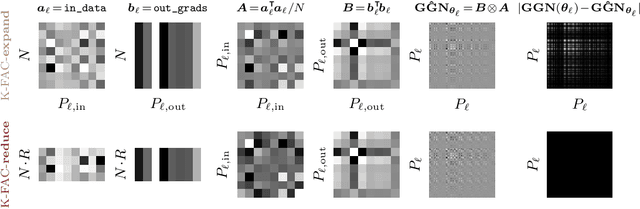
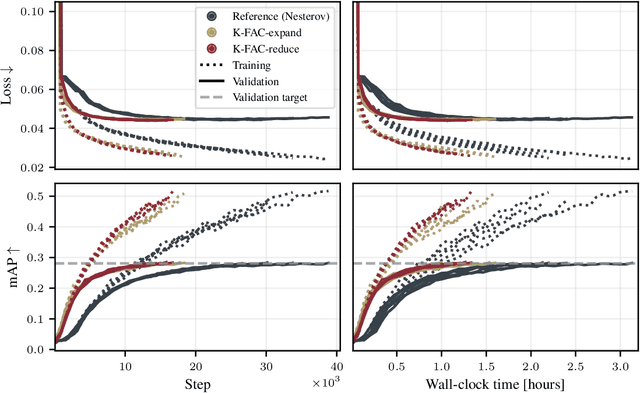

The core components of many modern neural network architectures, such as transformers, convolutional, or graph neural networks, can be expressed as linear layers with $\textit{weight-sharing}$. Kronecker-Factored Approximate Curvature (K-FAC), a second-order optimisation method, has shown promise to speed up neural network training and thereby reduce computational costs. However, there is currently no framework to apply it to generic architectures, specifically ones with linear weight-sharing layers. In this work, we identify two different settings of linear weight-sharing layers which motivate two flavours of K-FAC -- $\textit{expand}$ and $\textit{reduce}$. We show that they are exact for deep linear networks with weight-sharing in their respective setting. Notably, K-FAC-reduce is generally faster than K-FAC-expand, which we leverage to speed up automatic hyperparameter selection via optimising the marginal likelihood for a Wide ResNet. Finally, we observe little difference between these two K-FAC variations when using them to train both a graph neural network and a vision transformer. However, both variations are able to reach a fixed validation metric target in $50$-$75\%$ of the number of steps of a first-order reference run, which translates into a comparable improvement in wall-clock time. This highlights the potential of applying K-FAC to modern neural network architectures.
Sim2Real for Environmental Neural Processes
Oct 30, 2023Machine learning (ML)-based weather models have recently undergone rapid improvements. These models are typically trained on gridded reanalysis data from numerical data assimilation systems. However, reanalysis data comes with limitations, such as assumptions about physical laws and low spatiotemporal resolution. The gap between reanalysis and reality has sparked growing interest in training ML models directly on observations such as weather stations. Modelling scattered and sparse environmental observations requires scalable and flexible ML architectures, one of which is the convolutional conditional neural process (ConvCNP). ConvCNPs can learn to condition on both gridded and off-the-grid context data to make uncertainty-aware predictions at target locations. However, the sparsity of real observations presents a challenge for data-hungry deep learning models like the ConvCNP. One potential solution is 'Sim2Real': pre-training on reanalysis and fine-tuning on observational data. We analyse Sim2Real with a ConvCNP trained to interpolate surface air temperature over Germany, using varying numbers of weather stations for fine-tuning. On held-out weather stations, Sim2Real training substantially outperforms the same model architecture trained only with reanalysis data or only with station data, showing that reanalysis data can serve as a stepping stone for learning from real observations. Sim2Real could thus enable more accurate models for weather prediction and climate monitoring.