 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuichi Yu
STT: Stateful Tracking with Transformers for Autonomous Driving
Apr 30, 2024
Tracking objects in three-dimensional space is critical for autonomous driving. To ensure safety while driving, the tracker must be able to reliably track objects across frames and accurately estimate their states such as velocity and acceleration in the present. Existing works frequently focus on the association task while either neglecting the model performance on state estimation or deploying complex heuristics to predict the states. In this paper, we propose STT, a Stateful Tracking model built with Transformers, that can consistently track objects in the scenes while also predicting their states accurately. STT consumes rich appearance, geometry, and motion signals through long term history of detections and is jointly optimized for both data association and state estimation tasks. Since the standard tracking metrics like MOTA and MOTP do not capture the combined performance of the two tasks in the wider spectrum of object states, we extend them with new metrics called S-MOTA and MOTPS that address this limitation. STT achieves competitive real-time performance on the Waymo Open Dataset.
R4D: Utilizing Reference Objects for Long-Range Distance Estimation
Jun 10, 2022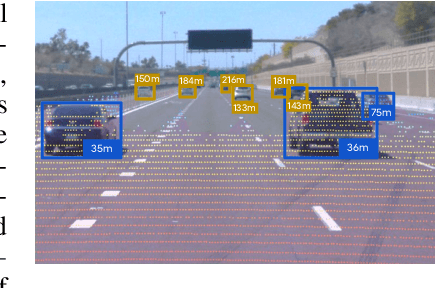

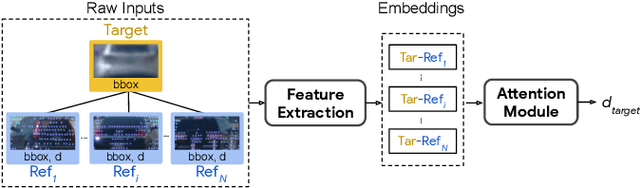
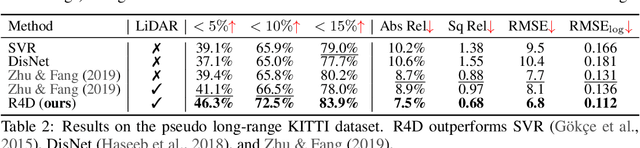
Estimating the distance of objects is a safety-critical task for autonomous driving. Focusing on short-range objects, existing methods and datasets neglect the equally important long-range objects. In this paper, we introduce a challenging and under-explored task, which we refer to as Long-Range Distance Estimation, as well as two datasets to validate new methods developed for this task. We then proposeR4D, the first framework to accurately estimate the distance of long-range objects by using references with known distances in the scene. Drawing inspiration from human perception, R4D builds a graph by connecting a target object to all references. An edge in the graph encodes the relative distance information between a pair of target and reference objects. An attention module is then used to weigh the importance of reference objects and combine them into one target object distance prediction. Experiments on the two proposed datasets demonstrate the effectiveness and robustness of R4D by showing significant improvements compared to existing baselines. We are looking to make the proposed dataset, Waymo OpenDataset - Long-Range Labels, available publicly at waymo.com/open/download.
Depth Estimation Matters Most: Improving Per-Object Depth Estimation for Monocular 3D Detection and Tracking
Jun 08, 2022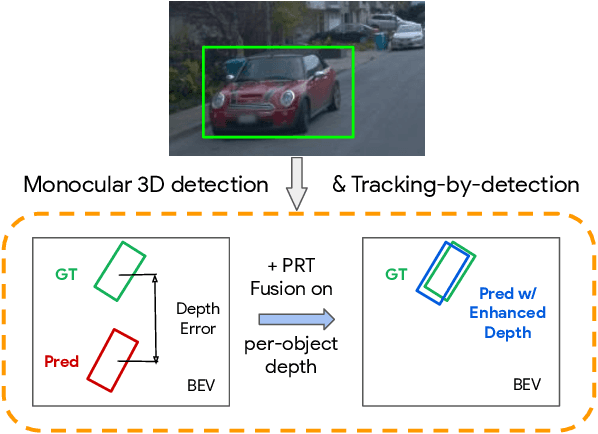
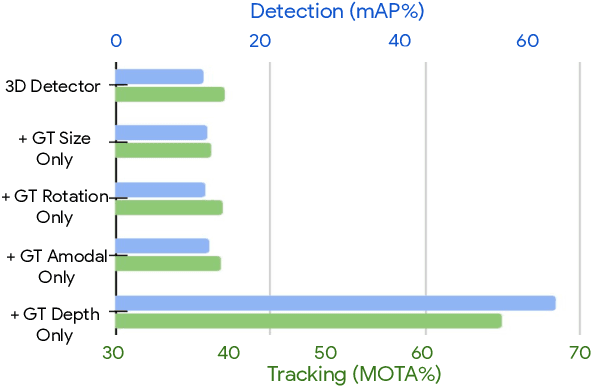
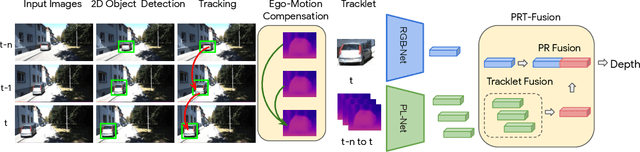
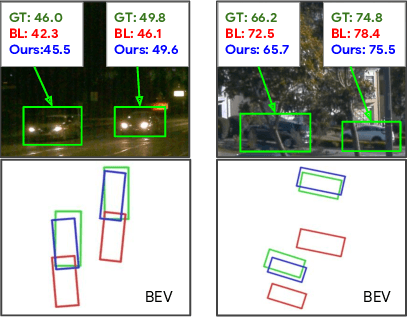
Monocular image-based 3D perception has become an active research area in recent years owing to its applications in autonomous driving. Approaches to monocular 3D perception including detection and tracking, however, often yield inferior performance when compared to LiDAR-based techniques. Through systematic analysis, we identified that per-object depth estimation accuracy is a major factor bounding the performance. Motivated by this observation, we propose a multi-level fusion method that combines different representations (RGB and pseudo-LiDAR) and temporal information across multiple frames for objects (tracklets) to enhance per-object depth estimation. Our proposed fusion method achieves the state-of-the-art performance of per-object depth estimation on the Waymo Open Dataset, the KITTI detection dataset, and the KITTI MOT dataset. We further demonstrate that by simply replacing estimated depth with fusion-enhanced depth, we can achieve significant improvements in monocular 3D perception tasks, including detection and tracking.
SoDA: Multi-Object Tracking with Soft Data Association
Aug 19, 2020

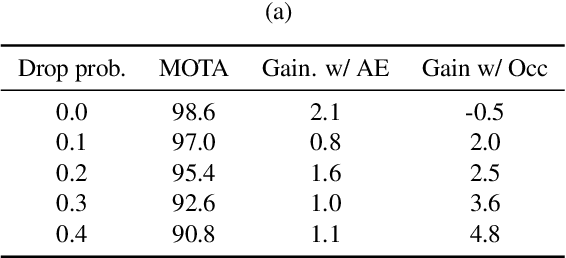
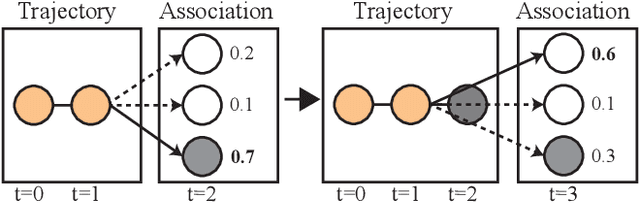
Robust multi-object tracking (MOT) is a prerequisite fora safe deployment of self-driving cars. Tracking objects, however, remains a highly challenging problem, especially in cluttered autonomous driving scenes in which objects tend to interact with each other in complex ways and frequently get occluded. We propose a novel approach to MOT that uses attention to compute track embeddings that encode the spatiotemporal dependencies between observed objects. This attention measurement encoding allows our model to relax hard data associations, which may lead to unrecoverable errors. Instead, our model aggregates information from all object detections via soft data associations. The resulting latent space representation allows our model to learn to reason about occlusions in a holistic data-driven way and maintain track estimates for objects even when they are occluded. Our experimental results on the Waymo OpenDataset suggest that our approach leverages modern large-scale datasets and performs favorably compared to the state of the art in visual multi-object tracking.
Uncertainty Modeling of Contextual-Connection between Tracklets for Unconstrained Video-based Face Recognition
May 07, 2019



Unconstrained video-based face recognition is a challenging problem due to significant within-video variations caused by pose, occlusion and blur. To tackle this problem, an effective idea is to propagate the identity from high-quality faces to low-quality ones through contextual connections, which are constructed based on context such as body appearance. However, previous methods have often propagated erroneous information due to lack of uncertainty modeling of the noisy contextual connections. In this paper, we propose the Uncertainty-Gated Graph (UGG), which conducts graph-based identity propagation between tracklets, which are represented by nodes in a graph. UGG explicitly models the uncertainty of the contextual connections by adaptively updating the weights of the edge gates according to the identity distributions of the nodes during inference. UGG is a generic graphical model that can be applied at only inference time or with end-to-end training. We demonstrate the effectiveness of UGG with state-of-the-art results in the recently released challenging Cast Search in Movies and IARPA Janus Surveillance Video Benchmark dataset.
Modeling Local Geometric Structure of 3D Point Clouds using Geo-CNN
Nov 19, 2018



Recent advances in deep convolutional neural networks (CNNs) have motivated researchers to adapt CNNs to directly model points in 3D point clouds. Modeling local structure has been proven to be important for the success of convolutional architectures, and researchers exploited the modeling of local point sets in the feature extraction hierarchy. However, limited attention has been paid to explicitly model the geometric structure amongst points in a local region. To address this problem, we propose Geo-CNN, which applies a generic convolution-like operation dubbed as GeoConv to each point and its local neighborhood. Local geometric relationships among points are captured when extracting edge features between the center and its neighboring points. We first decompose the edge feature extraction process onto three orthogonal bases, and then aggregate the extracted features based on the angles between the edge vector and the bases. This encourages the network to preserve the geometric structure in Euclidean space throughout the feature extraction hierarchy. GeoConv is a generic and efficient operation that can be easily integrated into 3D point cloud analysis pipelines for multiple applications. We evaluate Geo-CNN on ModelNet40 and KITTI and achieve state-of-the-art performance.
C-WSL: Count-guided Weakly Supervised Localization
Jul 25, 2018



We introduce count-guided weakly supervised localization (C-WSL), an approach that uses per-class object count as a new form of supervision to improve weakly supervised localization (WSL). C-WSL uses a simple count-based region selection algorithm to select high-quality regions, each of which covers a single object instance during training, and improves existing WSL methods by training with the selected regions. To demonstrate the effectiveness of C-WSL, we integrate it into two WSL architectures and conduct extensive experiments on VOC2007 and VOC2012. Experimental results show that C-WSL leads to large improvements in WSL and that the proposed approach significantly outperforms the state-of-the-art methods. The results of annotation experiments on VOC2007 suggest that a modest extra time is needed to obtain per-class object counts compared to labeling only object categories in an image. Furthermore, we reduce the annotation time by more than $2\times$ and $38\times$ compared to center-click and bounding-box annotations.
VITON: An Image-based Virtual Try-on Network
Jun 12, 2018



We present an image-based VIirtual Try-On Network (VITON) without using 3D information in any form, which seamlessly transfers a desired clothing item onto the corresponding region of a person using a coarse-to-fine strategy. Conditioned upon a new clothing-agnostic yet descriptive person representation, our framework first generates a coarse synthesized image with the target clothing item overlaid on that same person in the same pose. We further enhance the initial blurry clothing area with a refinement network. The network is trained to learn how much detail to utilize from the target clothing item, and where to apply to the person in order to synthesize a photo-realistic image in which the target item deforms naturally with clear visual patterns. Experiments on our newly collected Zalando dataset demonstrate its promise in the image-based virtual try-on task over state-of-the-art generative models.
Representing Videos based on Scene Layouts for Recognizing Agent-in-Place Actions
Apr 04, 2018



We address the recognition of agent-in-place actions, which are associated with agents who perform them and places where they occur, in the context of outdoor home surveillance. We introduce a representation of the geometry and topology of scene layouts so that a network can generalize from the layouts observed in the training set to unseen layouts in the test set. This Layout-Induced Video Representation (LIVR) abstracts away low-level appearance variance and encodes geometric and topological relationships of places in a specific scene layout. LIVR partitions the semantic features of a video clip into different places to force the network to learn place-based feature descriptions; to predict the confidence of each action, LIVR aggregates features from the place associated with an action and its adjacent places on the scene layout. We introduce the Agent-in-Place Action dataset to show that our method allows neural network models to generalize significantly better to unseen scenes.
Dynamic Zoom-in Network for Fast Object Detection in Large Images
Mar 27, 2018



We introduce a generic framework that reduces the computational cost of object detection while retaining accuracy for scenarios where objects with varied sizes appear in high resolution images. Detection progresses in a coarse-to-fine manner, first on a down-sampled version of the image and then on a sequence of higher resolution regions identified as likely to improve the detection accuracy. Built upon reinforcement learning, our approach consists of a model (R-net) that uses coarse detection results to predict the potential accuracy gain for analyzing a region at a higher resolution and another model (Q-net) that sequentially selects regions to zoom in. Experiments on the Caltech Pedestrians dataset show that our approach reduces the number of processed pixels by over 50% without a drop in detection accuracy. The merits of our approach become more significant on a high resolution test set collected from YFCC100M dataset, where our approach maintains high detection performance while reducing the number of processed pixels by about 70% and the detection time by over 50%.