 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS. Mahdi H. Miangoleh
Intrinsic Harmonization for Illumination-Aware Compositing
Dec 07, 2023




Despite significant advancements in network-based image harmonization techniques, there still exists a domain disparity between typical training pairs and real-world composites encountered during inference. Most existing methods are trained to reverse global edits made on segmented image regions, which fail to accurately capture the lighting inconsistencies between the foreground and background found in composited images. In this work, we introduce a self-supervised illumination harmonization approach formulated in the intrinsic image domain. First, we estimate a simple global lighting model from mid-level vision representations to generate a rough shading for the foreground region. A network then refines this inferred shading to generate a harmonious re-shading that aligns with the background scene. In order to match the color appearance of the foreground and background, we utilize ideas from prior harmonization approaches to perform parameterized image edits in the albedo domain. To validate the effectiveness of our approach, we present results from challenging real-world composites and conduct a user study to objectively measure the enhanced realism achieved compared to state-of-the-art harmonization methods.
Realistic Saliency Guided Image Enhancement
Jun 09, 2023

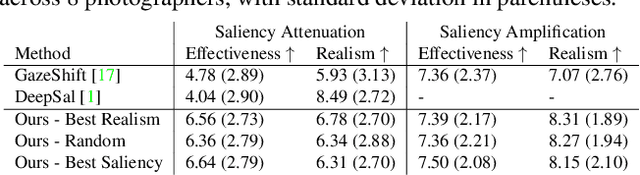
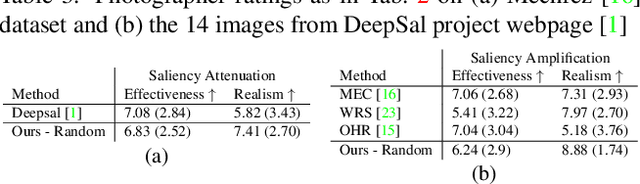
Common editing operations performed by professional photographers include the cleanup operations: de-emphasizing distracting elements and enhancing subjects. These edits are challenging, requiring a delicate balance between manipulating the viewer's attention while maintaining photo realism. While recent approaches can boast successful examples of attention attenuation or amplification, most of them also suffer from frequent unrealistic edits. We propose a realism loss for saliency-guided image enhancement to maintain high realism across varying image types, while attenuating distractors and amplifying objects of interest. Evaluations with professional photographers confirm that we achieve the dual objective of realism and effectiveness, and outperform the recent approaches on their own datasets, while requiring a smaller memory footprint and runtime. We thus offer a viable solution for automating image enhancement and photo cleanup operations.
* For more info visit http://yaksoy.github.io/realisticEditing/
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
May 28, 2021
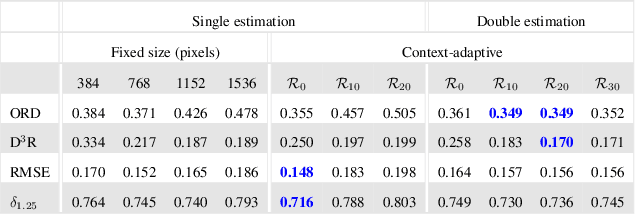


Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model.
* For more details visit http://yaksoy.github.io/highresdepth/