 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYağız Aksoy
Intrinsic Harmonization for Illumination-Aware Compositing
Dec 07, 2023




Despite significant advancements in network-based image harmonization techniques, there still exists a domain disparity between typical training pairs and real-world composites encountered during inference. Most existing methods are trained to reverse global edits made on segmented image regions, which fail to accurately capture the lighting inconsistencies between the foreground and background found in composited images. In this work, we introduce a self-supervised illumination harmonization approach formulated in the intrinsic image domain. First, we estimate a simple global lighting model from mid-level vision representations to generate a rough shading for the foreground region. A network then refines this inferred shading to generate a harmonious re-shading that aligns with the background scene. In order to match the color appearance of the foreground and background, we utilize ideas from prior harmonization approaches to perform parameterized image edits in the albedo domain. To validate the effectiveness of our approach, we present results from challenging real-world composites and conduct a user study to objectively measure the enhanced realism achieved compared to state-of-the-art harmonization methods.
Intrinsic Image Decomposition via Ordinal Shading
Nov 21, 2023Intrinsic decomposition is a fundamental mid-level vision problem that plays a crucial role in various inverse rendering and computational photography pipelines. Generating highly accurate intrinsic decompositions is an inherently under-constrained task that requires precisely estimating continuous-valued shading and albedo. In this work, we achieve high-resolution intrinsic decomposition by breaking the problem into two parts. First, we present a dense ordinal shading formulation using a shift- and scale-invariant loss in order to estimate ordinal shading cues without restricting the predictions to obey the intrinsic model. We then combine low- and high-resolution ordinal estimations using a second network to generate a shading estimate with both global coherency and local details. We encourage the model to learn an accurate decomposition by computing losses on the estimated shading as well as the albedo implied by the intrinsic model. We develop a straightforward method for generating dense pseudo ground truth using our model's predictions and multi-illumination data, enabling generalization to in-the-wild imagery. We present an exhaustive qualitative and quantitative analysis of our predicted intrinsic components against state-of-the-art methods. Finally, we demonstrate the real-world applicability of our estimations by performing otherwise difficult editing tasks such as recoloring and relighting.
Realistic Saliency Guided Image Enhancement
Jun 09, 2023

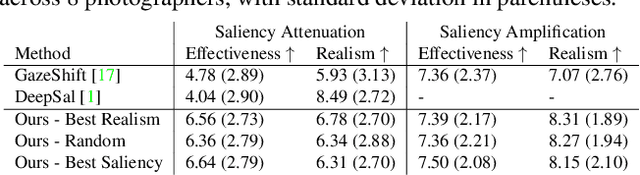
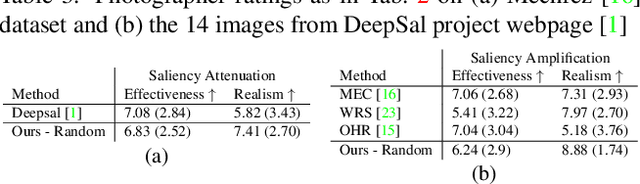
Common editing operations performed by professional photographers include the cleanup operations: de-emphasizing distracting elements and enhancing subjects. These edits are challenging, requiring a delicate balance between manipulating the viewer's attention while maintaining photo realism. While recent approaches can boast successful examples of attention attenuation or amplification, most of them also suffer from frequent unrealistic edits. We propose a realism loss for saliency-guided image enhancement to maintain high realism across varying image types, while attenuating distractors and amplifying objects of interest. Evaluations with professional photographers confirm that we achieve the dual objective of realism and effectiveness, and outperform the recent approaches on their own datasets, while requiring a smaller memory footprint and runtime. We thus offer a viable solution for automating image enhancement and photo cleanup operations.
* For more info visit http://yaksoy.github.io/realisticEditing/
Computational Flash Photography through Intrinsics
Jun 09, 2023



Flash is an essential tool as it often serves as the sole controllable light source in everyday photography. However, the use of flash is a binary decision at the time a photograph is captured with limited control over its characteristics such as strength or color. In this work, we study the computational control of the flash light in photographs taken with or without flash. We present a physically motivated intrinsic formulation for flash photograph formation and develop flash decomposition and generation methods for flash and no-flash photographs, respectively. We demonstrate that our intrinsic formulation outperforms alternatives in the literature and allows us to computationally control flash in in-the-wild images.
Boosting Monocular Depth Estimation Models to High-Resolution via Content-Adaptive Multi-Resolution Merging
May 28, 2021
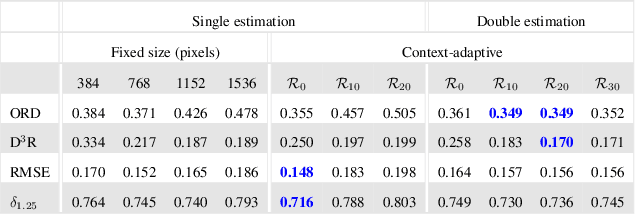


Neural networks have shown great abilities in estimating depth from a single image. However, the inferred depth maps are well below one-megapixel resolution and often lack fine-grained details, which limits their practicality. Our method builds on our analysis on how the input resolution and the scene structure affects depth estimation performance. We demonstrate that there is a trade-off between a consistent scene structure and the high-frequency details, and merge low- and high-resolution estimations to take advantage of this duality using a simple depth merging network. We present a double estimation method that improves the whole-image depth estimation and a patch selection method that adds local details to the final result. We demonstrate that by merging estimations at different resolutions with changing context, we can generate multi-megapixel depth maps with a high level of detail using a pre-trained model.
* For more details visit http://yaksoy.github.io/highresdepth/
Designing Effective Inter-Pixel Information Flow for Natural Image Matting
Jul 17, 2017



We present a novel, purely affinity-based natural image matting algorithm. Our method relies on carefully defined pixel-to-pixel connections that enable effective use of information available in the image. We control the information flow from the known-opacity regions into the unknown region, as well as within the unknown region itself, by utilizing multiple definitions of pixel affinities. Among other forms of information flow, we introduce color-mixture flow, which builds upon local linear embedding and effectively encapsulates the relation between different pixel opacities. Our resulting novel linear system formulation can be solved in closed-form and is robust against several fundamental challenges of natural matting such as holes and remote intricate structures. Our evaluation using the alpha matting benchmark suggests a significant performance improvement over the current methods. While our method is primarily designed as a standalone matting tool, we show that it can also be used for regularizing mattes obtained by sampling-based methods. We extend our formulation to layer color estimation and show that the use of multiple channels of flow increases the layer color quality. We also demonstrate our performance in green-screen keying and further analyze the characteristics of the affinities used in our method.