 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiry Ginosar
Can Language Models Learn to Listen?
Aug 21, 2023
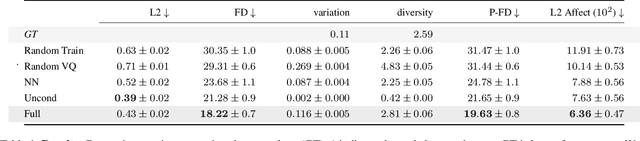
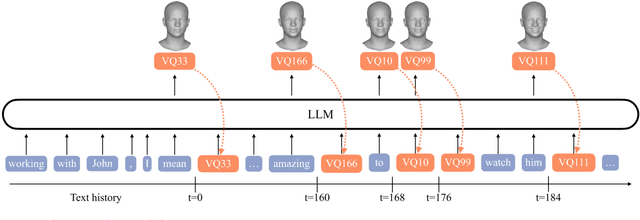
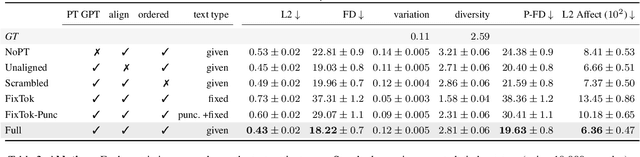

We present a framework for generating appropriate facial responses from a listener in dyadic social interactions based on the speaker's words. Given an input transcription of the speaker's words with their timestamps, our approach autoregressively predicts a response of a listener: a sequence of listener facial gestures, quantized using a VQ-VAE. Since gesture is a language component, we propose treating the quantized atomic motion elements as additional language token inputs to a transformer-based large language model. Initializing our transformer with the weights of a language model pre-trained only on text results in significantly higher quality listener responses than training a transformer from scratch. We show that our generated listener motion is fluent and reflective of language semantics through quantitative metrics and a qualitative user study. In our evaluation, we analyze the model's ability to utilize temporal and semantic aspects of spoken text. Project page: https://people.eecs.berkeley.edu/~evonne_ng/projects/text2listen/
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Apr 18, 2022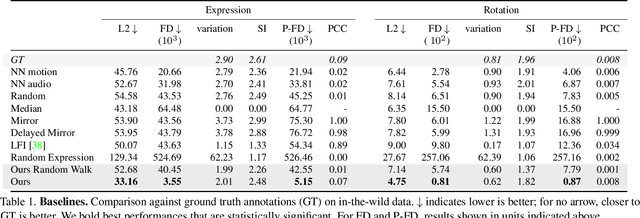
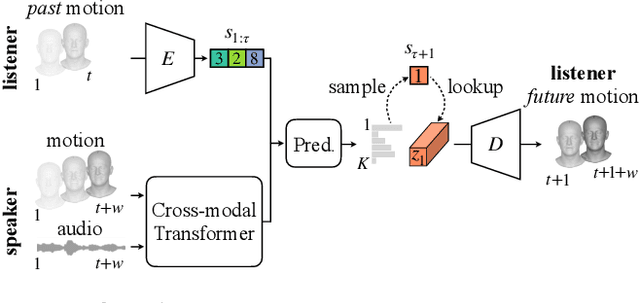
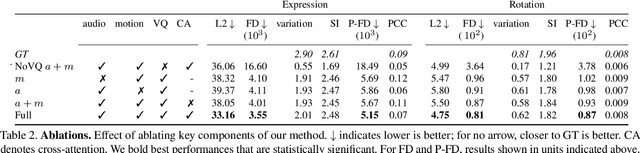
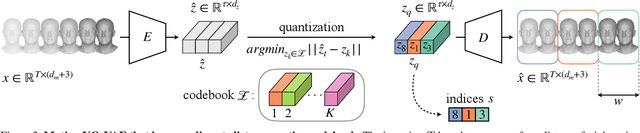
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.
Strumming to the Beat: Audio-Conditioned Contrastive Video Textures
Apr 06, 2021
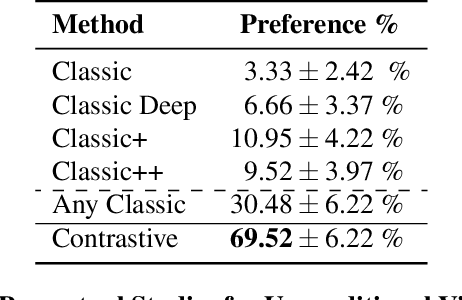

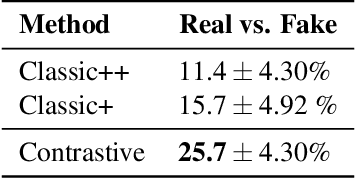
We introduce a non-parametric approach for infinite video texture synthesis using a representation learned via contrastive learning. We take inspiration from Video Textures, which showed that plausible new videos could be generated from a single one by stitching its frames together in a novel yet consistent order. This classic work, however, was constrained by its use of hand-designed distance metrics, limiting its use to simple, repetitive videos. We draw on recent techniques from self-supervised learning to learn this distance metric, allowing us to compare frames in a manner that scales to more challenging dynamics, and to condition on other data, such as audio. We learn representations for video frames and frame-to-frame transition probabilities by fitting a video-specific model trained using contrastive learning. To synthesize a texture, we randomly sample frames with high transition probabilities to generate diverse temporally smooth videos with novel sequences and transitions. The model naturally extends to an audio-conditioned setting without requiring any finetuning. Our model outperforms baselines on human perceptual scores, can handle a diverse range of input videos, and can combine semantic and audio-visual cues in order to synthesize videos that synchronize well with an audio signal.
Learning to Factorize and Relight a City
Aug 06, 2020
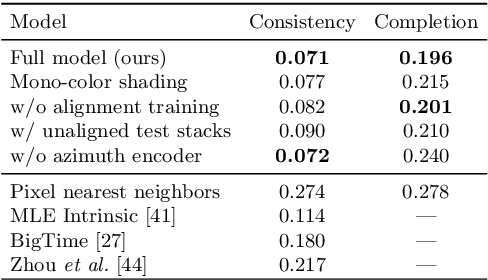


We propose a learning-based framework for disentangling outdoor scenes into temporally-varying illumination and permanent scene factors. Inspired by the classic intrinsic image decomposition, our learning signal builds upon two insights: 1) combining the disentangled factors should reconstruct the original image, and 2) the permanent factors should stay constant across multiple temporal samples of the same scene. To facilitate training, we assemble a city-scale dataset of outdoor timelapse imagery from Google Street View, where the same locations are captured repeatedly through time. This data represents an unprecedented scale of spatio-temporal outdoor imagery. We show that our learned disentangled factors can be used to manipulate novel images in realistic ways, such as changing lighting effects and scene geometry. Please visit factorize-a-city.github.io for animated results.
Body2Hands: Learning to Infer 3D Hands from Conversational Gesture Body Dynamics
Jul 23, 2020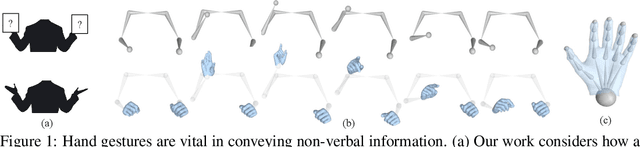
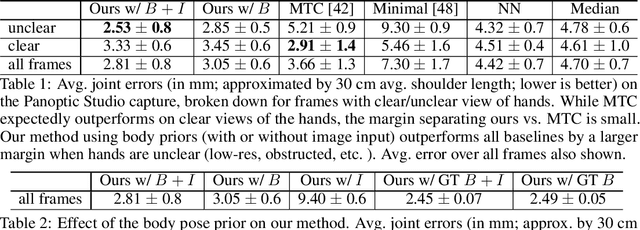
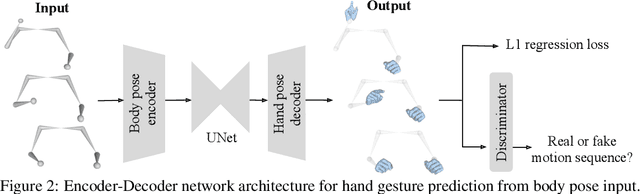

We propose a novel learned deep prior of body motion for 3D hand shape synthesis and estimation in the domain of conversational gestures. Our model builds upon the insight that body motion and hand gestures are strongly correlated in non-verbal communication settings. We formulate the learning of this prior as a prediction task of 3D hand shape over time given body motion input alone. Trained with 3D pose estimations obtained from a large-scale dataset of internet videos, our hand prediction model produces convincing 3D hand gestures given only the 3D motion of the speaker's arms as input. We demonstrate the efficacy of our method on hand gesture synthesis from body motion input, and as a strong body prior for single-view image-based 3D hand pose estimation. We demonstrate that our method outperforms previous state-of-the-art approaches and can generalize beyond the monologue-based training data to multi-person conversations. Video results are available at http://people.eecs.berkeley.edu/~evonne_ng/projects/body2hands/.
Learning Individual Styles of Conversational Gesture
Jun 10, 2019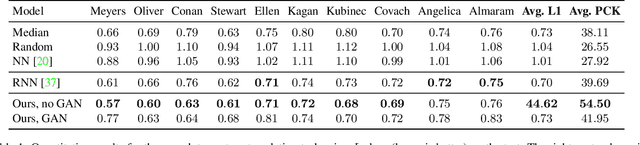


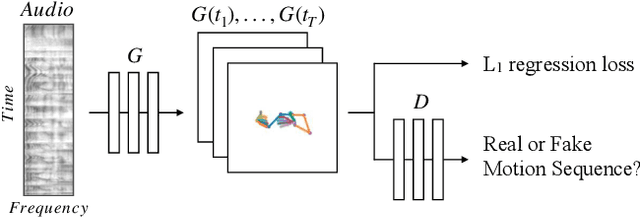
Human speech is often accompanied by hand and arm gestures. Given audio speech input, we generate plausible gestures to go along with the sound. Specifically, we perform cross-modal translation from "in-the-wild'' monologue speech of a single speaker to their hand and arm motion. We train on unlabeled videos for which we only have noisy pseudo ground truth from an automatic pose detection system. Our proposed model significantly outperforms baseline methods in a quantitative comparison. To support research toward obtaining a computational understanding of the relationship between gesture and speech, we release a large video dataset of person-specific gestures. The project website with video, code and data can be found at http://people.eecs.berkeley.edu/~shiry/speech2gesture .
Everybody Dance Now
Aug 22, 2018


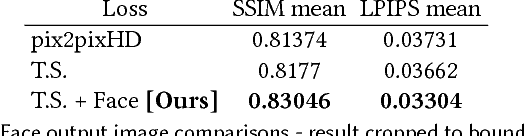
This paper presents a simple method for "do as I do" motion transfer: given a source video of a person dancing we can transfer that performance to a novel (amateur) target after only a few minutes of the target subject performing standard moves. We pose this problem as a per-frame image-to-image translation with spatio-temporal smoothing. Using pose detections as an intermediate representation between source and target, we learn a mapping from pose images to a target subject's appearance. We adapt this setup for temporally coherent video generation including realistic face synthesis. Our video demo can be found at https://youtu.be/PCBTZh41Ris .
Photographic home styles in Congress: a computer vision approach
Dec 05, 2016
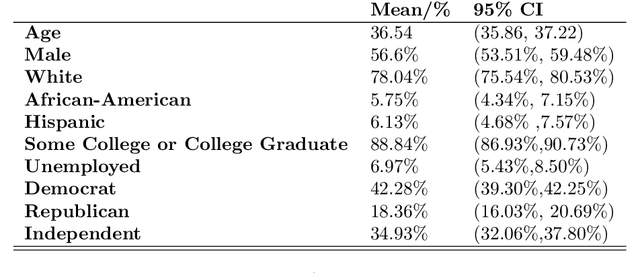


While members of Congress now routinely communicate with constituents using images on a variety of internet platforms, little is known about how images are used as a means of strategic political communication. This is due primarily to computational limitations which have prevented large-scale, systematic analyses of image features. New developments in computer vision, however, are bringing the systematic study of images within reach. Here, we develop a framework for understanding visual political communication by extending Fenno's analysis of home style (Fenno 1978) to images and introduce "photographic" home styles. Using approximately 192,000 photographs collected from MCs Facebook profiles, we build machine learning software with convolutional neural networks and conduct an image manipulation experiment to explore how the race of people that MCs pose with shape photographic home styles. We find evidence that electoral pressures shape photographic home styles and demonstrate that Democratic and Republican members of Congress use images in very different ways.
A Century of Portraits: A Visual Historical Record of American High School Yearbooks
Nov 09, 2015
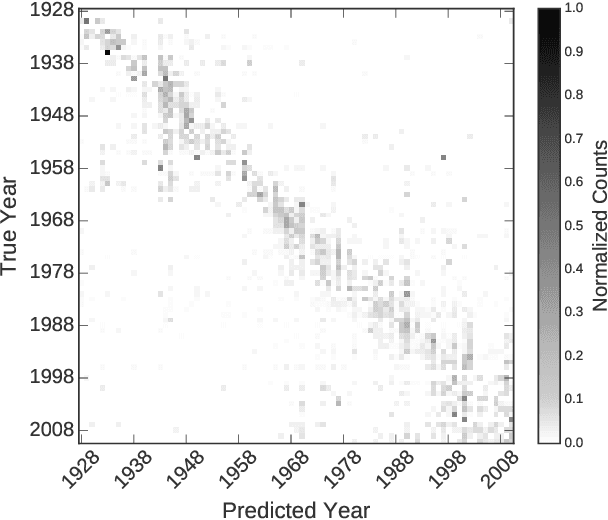


Many details about our world are not captured in written records because they are too mundane or too abstract to describe in words. Fortunately, since the invention of the camera, an ever-increasing number of photographs capture much of this otherwise lost information. This plethora of artifacts documenting our "visual culture" is a treasure trove of knowledge as yet untapped by historians. We present a dataset of 37,921 frontal-facing American high school yearbook photos that allow us to use computation to glimpse into the historical visual record too voluminous to be evaluated manually. The collected portraits provide a constant visual frame of reference with varying content. We can therefore use them to consider issues such as a decade's defining style elements, or trends in fashion and social norms over time. We demonstrate that our historical image dataset may be used together with weakly-supervised data-driven techniques to perform scalable historical analysis of large image corpora with minimal human effort, much in the same way that large text corpora together with natural language processing revolutionized historians' workflow. Furthermore, we demonstrate the use of our dataset in dating grayscale portraits using deep learning methods.
Detecting People in Cubist Art
Sep 22, 2014
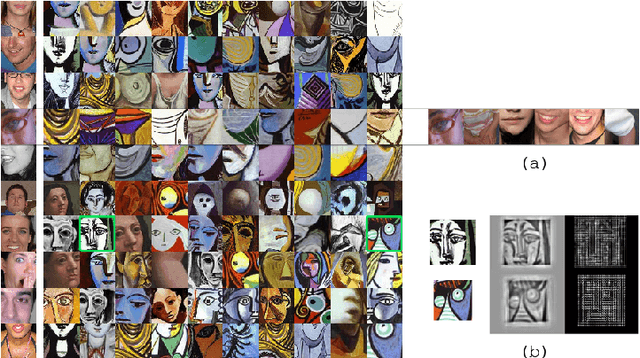
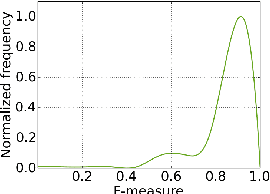

Although the human visual system is surprisingly robust to extreme distortion when recognizing objects, most evaluations of computer object detection methods focus only on robustness to natural form deformations such as people's pose changes. To determine whether algorithms truly mirror the flexibility of human vision, they must be compared against human vision at its limits. For example, in Cubist abstract art, painted objects are distorted by object fragmentation and part-reorganization, to the point that human vision often fails to recognize them. In this paper, we evaluate existing object detection methods on these abstract renditions of objects, comparing human annotators to four state-of-the-art object detectors on a corpus of Picasso paintings. Our results demonstrate that while human perception significantly outperforms current methods, human perception and part-based models exhibit a similarly graceful degradation in object detection performance as the objects become increasingly abstract and fragmented, corroborating the theory of part-based object representation in the brain.