 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiwen Hu
Spike-NeRF: Neural Radiance Field Based On Spike Camera
Mar 25, 2024
As a neuromorphic sensor with high temporal resolution, spike cameras offer notable advantages over traditional cameras in high-speed vision applications such as high-speed optical estimation, depth estimation, and object tracking. Inspired by the success of the spike camera, we proposed Spike-NeRF, the first Neural Radiance Field derived from spike data, to achieve 3D reconstruction and novel viewpoint synthesis of high-speed scenes. Instead of the multi-view images at the same time of NeRF, the inputs of Spike-NeRF are continuous spike streams captured by a moving spike camera in a very short time. To reconstruct a correct and stable 3D scene from high-frequency but unstable spike data, we devised spike masks along with a distinctive loss function. We evaluate our method qualitatively and numerically on several challenging synthetic scenes generated by blender with the spike camera simulator. Our results demonstrate that Spike-NeRF produces more visually appealing results than the existing methods and the baseline we proposed in high-speed scenes. Our code and data will be released soon.
Learning to Robustly Reconstruct Low-light Dynamic Scenes from Spike Streams
Jan 19, 2024As a neuromorphic sensor with high temporal resolution, spike camera can generate continuous binary spike streams to capture per-pixel light intensity. We can use reconstruction methods to restore scene details in high-speed scenarios. However, due to limited information in spike streams, low-light scenes are difficult to effectively reconstruct. In this paper, we propose a bidirectional recurrent-based reconstruction framework, including a Light-Robust Representation (LR-Rep) and a fusion module, to better handle such extreme conditions. LR-Rep is designed to aggregate temporal information in spike streams, and a fusion module is utilized to extract temporal features. Additionally, we have developed a reconstruction benchmark for high-speed low-light scenes. Light sources in the scenes are carefully aligned to real-world conditions. Experimental results demonstrate the superiority of our method, which also generalizes well to real spike streams. Related codes and proposed datasets will be released after publication.
VOODOO 3D: Volumetric Portrait Disentanglement for One-Shot 3D Head Reenactment
Dec 07, 2023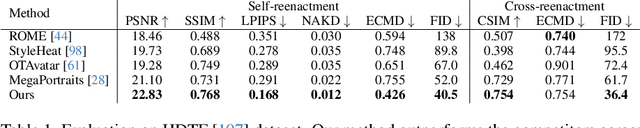
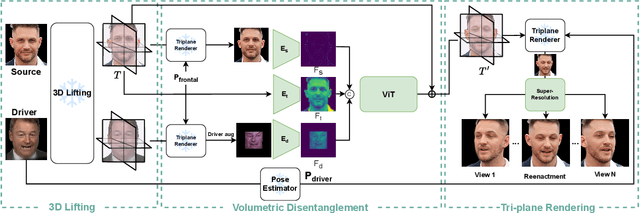


We present a 3D-aware one-shot head reenactment method based on a fully volumetric neural disentanglement framework for source appearance and driver expressions. Our method is real-time and produces high-fidelity and view-consistent output, suitable for 3D teleconferencing systems based on holographic displays. Existing cutting-edge 3D-aware reenactment methods often use neural radiance fields or 3D meshes to produce view-consistent appearance encoding, but, at the same time, they rely on linear face models, such as 3DMM, to achieve its disentanglement with facial expressions. As a result, their reenactment results often exhibit identity leakage from the driver or have unnatural expressions. To address these problems, we propose a neural self-supervised disentanglement approach that lifts both the source image and driver video frame into a shared 3D volumetric representation based on tri-planes. This representation can then be freely manipulated with expression tri-planes extracted from the driving images and rendered from an arbitrary view using neural radiance fields. We achieve this disentanglement via self-supervised learning on a large in-the-wild video dataset. We further introduce a highly effective fine-tuning approach to improve the generalizability of the 3D lifting using the same real-world data. We demonstrate state-of-the-art performance on a wide range of datasets, and also showcase high-quality 3D-aware head reenactment on highly challenging and diverse subjects, including non-frontal head poses and complex expressions for both source and driver.
Learning to Listen: Modeling Non-Deterministic Dyadic Facial Motion
Apr 18, 2022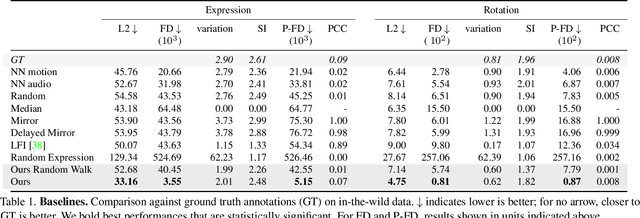
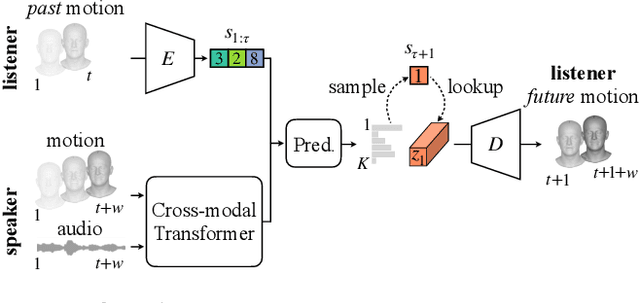
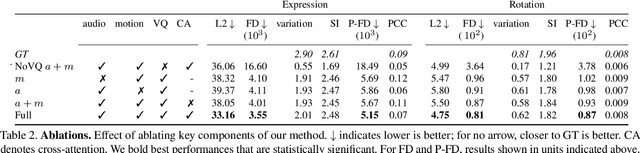
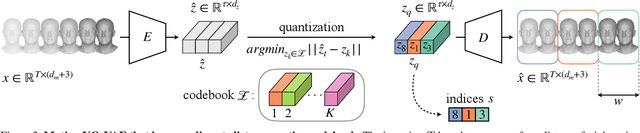
We present a framework for modeling interactional communication in dyadic conversations: given multimodal inputs of a speaker, we autoregressively output multiple possibilities of corresponding listener motion. We combine the motion and speech audio of the speaker using a motion-audio cross attention transformer. Furthermore, we enable non-deterministic prediction by learning a discrete latent representation of realistic listener motion with a novel motion-encoding VQ-VAE. Our method organically captures the multimodal and non-deterministic nature of nonverbal dyadic interactions. Moreover, it produces realistic 3D listener facial motion synchronous with the speaker (see video). We demonstrate that our method outperforms baselines qualitatively and quantitatively via a rich suite of experiments. To facilitate this line of research, we introduce a novel and large in-the-wild dataset of dyadic conversations. Code, data, and videos available at https://evonneng.github.io/learning2listen/.
A Robust Visual Sampling Model Inspired by Receptive Field
Jan 04, 2022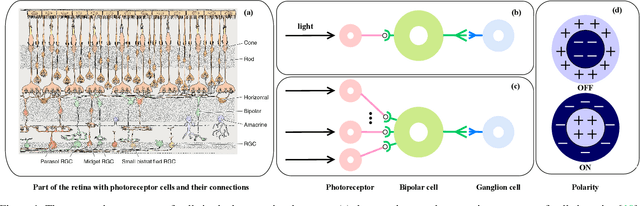
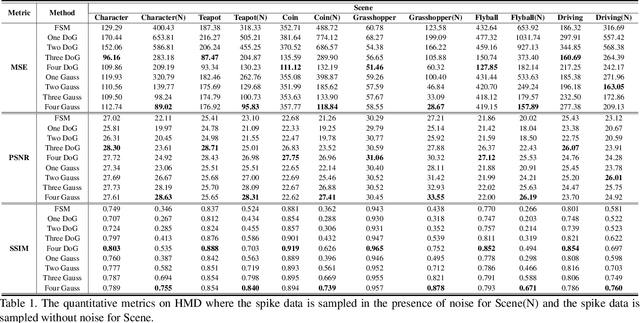


Spike camera mimicking the retina fovea can report per-pixel luminance intensity accumulation by firing spikes. As a bio-inspired vision sensor with high temporal resolution, it has a huge potential for computer vision. However, the sampling model in current Spike camera is so susceptible to quantization and noise that it cannot capture the texture details of objects effectively. In this work, a robust visual sampling model inspired by receptive field (RVSM) is proposed where wavelet filter generated by difference of Gaussian (DoG) and Gaussian filter are used to simulate receptive field. Using corresponding method similar to inverse wavelet transform, spike data from RVSM can be converted into images. To test the performance, we also propose a high-speed motion spike dataset (HMD) including a variety of motion scenes. By comparing reconstructed images in HMD, we find RVSM can improve the ability of capturing information of Spike camera greatly. More importantly, due to mimicking receptive field mechanism to collect regional information, RVSM can filter high intensity noise effectively and improves the problem that Spike camera is sensitive to noise largely. Besides, due to the strong generalization of sampling structure, RVSM is also suitable for other neuromorphic vision sensor. Above experiments are finished in a Spike camera simulator.
Watch Those Words: Video Falsification Detection Using Word-Conditioned Facial Motion
Dec 21, 2021
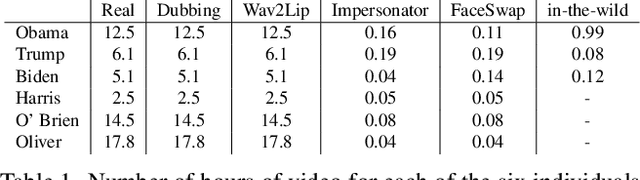

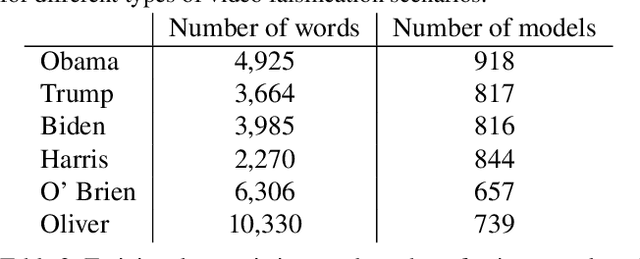
In today's era of digital misinformation, we are increasingly faced with new threats posed by video falsification techniques. Such falsifications range from cheapfakes (e.g., lookalikes or audio dubbing) to deepfakes (e.g., sophisticated AI media synthesis methods), which are becoming perceptually indistinguishable from real videos. To tackle this challenge, we propose a multi-modal semantic forensic approach to discover clues that go beyond detecting discrepancies in visual quality, thereby handling both simpler cheapfakes and visually persuasive deepfakes. In this work, our goal is to verify that the purported person seen in the video is indeed themselves by detecting anomalous correspondences between their facial movements and the words they are saying. We leverage the idea of attribution to learn person-specific biometric patterns that distinguish a given speaker from others. We use interpretable Action Units (AUs) to capture a persons' face and head movement as opposed to deep CNN visual features, and we are the first to use word-conditioned facial motion analysis. Unlike existing person-specific approaches, our method is also effective against attacks that focus on lip manipulation. We further demonstrate our method's effectiveness on a range of fakes not seen in training including those without video manipulation, that were not addressed in prior work.
SCFlow: Optical Flow Estimation for Spiking Camera
Oct 08, 2021



As a bio-inspired sensor with high temporal resolution, Spiking camera has an enormous potential in real applications, especially for motion estimation in high-speed scenes. Optical flow estimation has achieved remarkable success in image-based and event-based vision, but % existing methods cannot be directly applied in spike stream from spiking camera. conventional optical flow algorithms are not well matched to the spike stream data. This paper presents, SCFlow, a novel deep learning pipeline for optical flow estimation for spiking camera. Importantly, we introduce an proper input representation of a given spike stream, which is fed into SCFlow as the sole input. We introduce the \textit{first} spiking camera simulator (SPCS). Furthermore, based on SPCS, we first propose two optical flow datasets for spiking camera (SPIkingly Flying Things and Photo-realistic High-speed Motion, denoted as SPIFT and PHM respectively) corresponding to random high-speed and well-designed scenes. Empirically, we show that the SCFlow can predict optical flow from spike stream in different high-speed scenes, and express superiority to existing methods on the datasets. \textit{All codes and constructed datasets will be released after publication}.
Normalized Avatar Synthesis Using StyleGAN and Perceptual Refinement
Jun 21, 2021


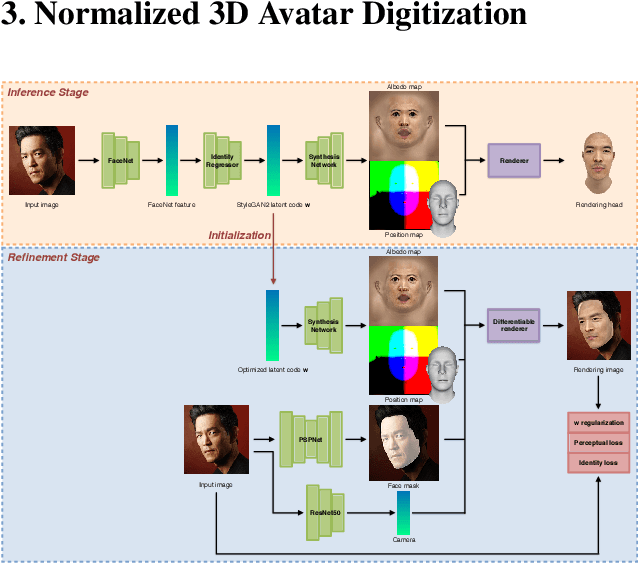
We introduce a highly robust GAN-based framework for digitizing a normalized 3D avatar of a person from a single unconstrained photo. While the input image can be of a smiling person or taken in extreme lighting conditions, our method can reliably produce a high-quality textured model of a person's face in neutral expression and skin textures under diffuse lighting condition. Cutting-edge 3D face reconstruction methods use non-linear morphable face models combined with GAN-based decoders to capture the likeness and details of a person but fail to produce neutral head models with unshaded albedo textures which is critical for creating relightable and animation-friendly avatars for integration in virtual environments. The key challenges for existing methods to work is the lack of training and ground truth data containing normalized 3D faces. We propose a two-stage approach to address this problem. First, we adopt a highly robust normalized 3D face generator by embedding a non-linear morphable face model into a StyleGAN2 network. This allows us to generate detailed but normalized facial assets. This inference is then followed by a perceptual refinement step that uses the generated assets as regularization to cope with the limited available training samples of normalized faces. We further introduce a Normalized Face Dataset, which consists of a combination photogrammetry scans, carefully selected photographs, and generated fake people with neutral expressions in diffuse lighting conditions. While our prepared dataset contains two orders of magnitude less subjects than cutting edge GAN-based 3D facial reconstruction methods, we show that it is possible to produce high-quality normalized face models for very challenging unconstrained input images, and demonstrate superior performance to the current state-of-the-art.
Photorealistic Facial Texture Inference Using Deep Neural Networks
Dec 02, 2016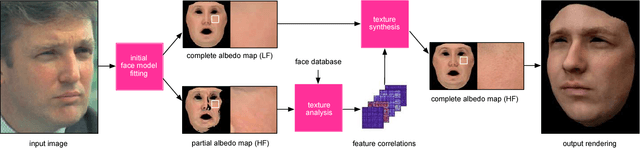
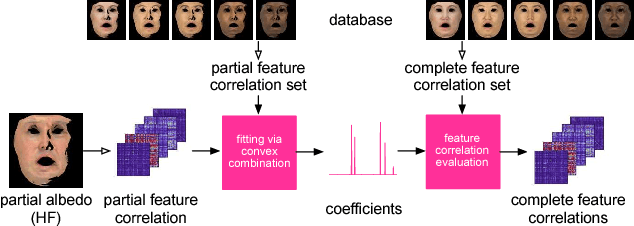
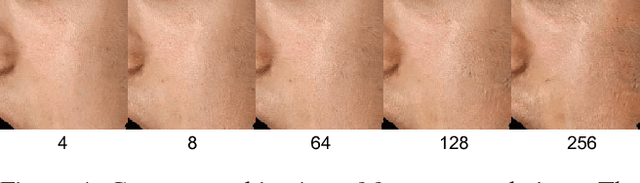
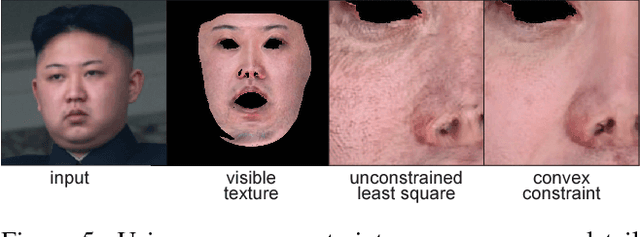
We present a data-driven inference method that can synthesize a photorealistic texture map of a complete 3D face model given a partial 2D view of a person in the wild. After an initial estimation of shape and low-frequency albedo, we compute a high-frequency partial texture map, without the shading component, of the visible face area. To extract the fine appearance details from this incomplete input, we introduce a multi-scale detail analysis technique based on mid-layer feature correlations extracted from a deep convolutional neural network. We demonstrate that fitting a convex combination of feature correlations from a high-resolution face database can yield a semantically plausible facial detail description of the entire face. A complete and photorealistic texture map can then be synthesized by iteratively optimizing for the reconstructed feature correlations. Using these high-resolution textures and a commercial rendering framework, we can produce high-fidelity 3D renderings that are visually comparable to those obtained with state-of-the-art multi-view face capture systems. We demonstrate successful face reconstructions from a wide range of low resolution input images, including those of historical figures. In addition to extensive evaluations, we validate the realism of our results using a crowdsourced user study.