 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeli Ma
TFNet: Exploiting Temporal Cues for Fast and Accurate LiDAR Semantic Segmentation
Sep 17, 2023

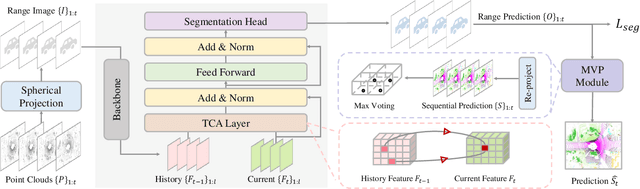


LiDAR semantic segmentation plays a crucial role in enabling autonomous driving and robots to understand their surroundings accurately and robustly. There are different types of methods, such as point-based, range-image-based, polar-based, and hybrid methods. Among these, range-image-based methods are widely used due to their efficiency. However, they face a significant challenge known as the ``many-to-one'' problem caused by the range image's limited horizontal and vertical angular resolution. As a result, around 20\% of the 3D points can be occluded. In this paper, we present TFNet, a range-image-based LiDAR semantic segmentation method that utilizes temporal information to address this issue. Specifically, we incorporate a temporal fusion layer to extract useful information from previous scans and integrate it with the current scan. We then design a max-voting-based post-processing technique to correct false predictions, particularly those caused by the ``many-to-one'' issue. We evaluated the approach on two benchmarks and demonstrate that the post-processing technique is generic and can be applied to various networks. We will release our code and models.
Synchronize Feature Extracting and Matching: A Single Branch Framework for 3D Object Tracking
Aug 24, 2023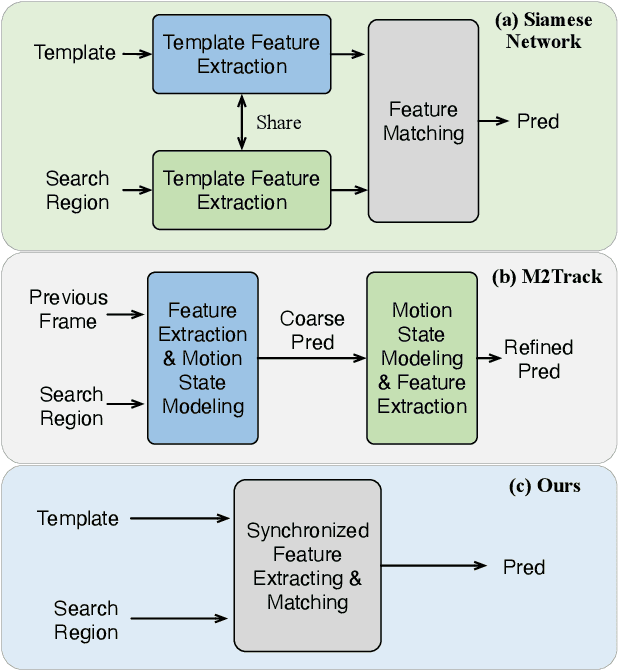
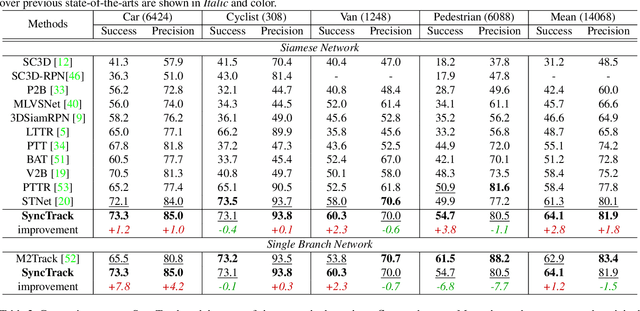
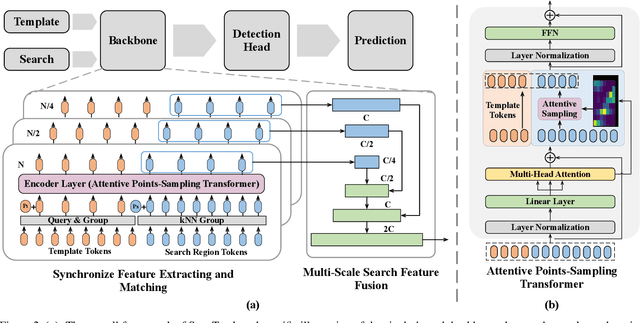
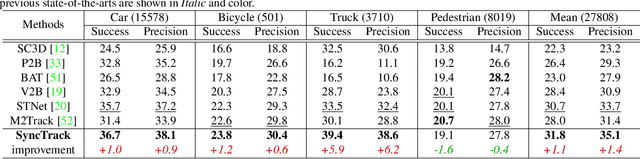
Siamese network has been a de facto benchmark framework for 3D LiDAR object tracking with a shared-parametric encoder extracting features from template and search region, respectively. This paradigm relies heavily on an additional matching network to model the cross-correlation/similarity of the template and search region. In this paper, we forsake the conventional Siamese paradigm and propose a novel single-branch framework, SyncTrack, synchronizing the feature extracting and matching to avoid forwarding encoder twice for template and search region as well as introducing extra parameters of matching network. The synchronization mechanism is based on the dynamic affinity of the Transformer, and an in-depth analysis of the relevance is provided theoretically. Moreover, based on the synchronization, we introduce a novel Attentive Points-Sampling strategy into the Transformer layers (APST), replacing the random/Farthest Points Sampling (FPS) method with sampling under the supervision of attentive relations between the template and search region. It implies connecting point-wise sampling with the feature learning, beneficial to aggregating more distinctive and geometric features for tracking with sparse points. Extensive experiments on two benchmark datasets (KITTI and NuScenes) show that SyncTrack achieves state-of-the-art performance in real-time tracking.
An Examination of the Compositionality of Large Generative Vision-Language Models
Aug 21, 2023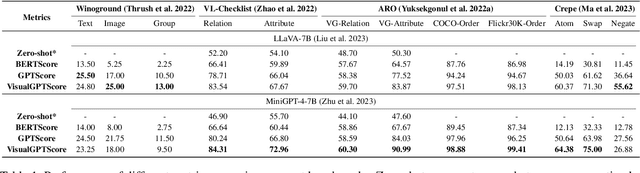
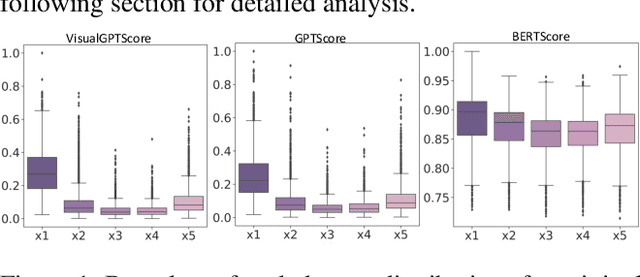


With the success of Large Language Models (LLMs), a surge of Generative Vision-Language Models (GVLMs) have been constructed via multimodal instruction tuning. The tuning recipe substantially deviates from the common contrastive vision-language learning. However, the performance of GVLMs in multimodal compositional reasoning remains largely unexplored, as existing evaluation metrics and benchmarks focus predominantly on assessing contrastive models like CLIP. In this paper, we examine the potential evaluation metrics to assess the GVLMs and hypothesize generative score methods are suitable for evaluating compositionality. In addition, current benchmarks tend to prioritize syntactic correctness over semantics. The presence of morphological bias in these benchmarks can be exploited by GVLMs, leading to ineffective evaluations. To combat this, we define a MorphoBias Score to quantify the morphological bias and propose a novel LLM-based strategy to calibrate the bias. Moreover, a challenging task is added to evaluate the robustness of GVLMs against inherent inclination toward syntactic correctness. We include the calibrated dataset and the task into a new benchmark, namely MOrphologicall De-biased Benchmark (MODE). Our study provides the first unbiased benchmark for the compositionality of GVLMs, facilitating future research in this direction. We will release our code and datasets.
Correlation Pyramid Network for 3D Single Object Tracking
May 16, 2023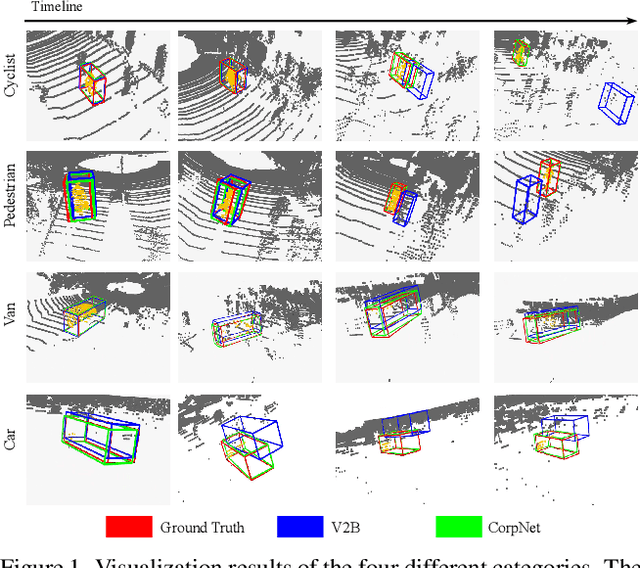
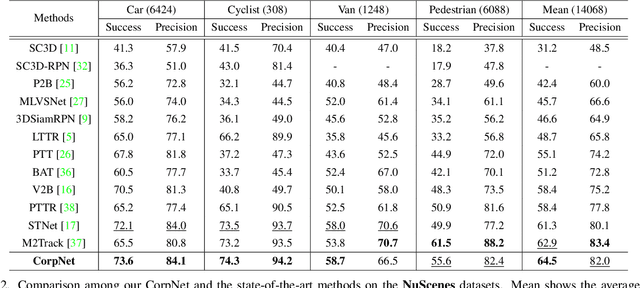
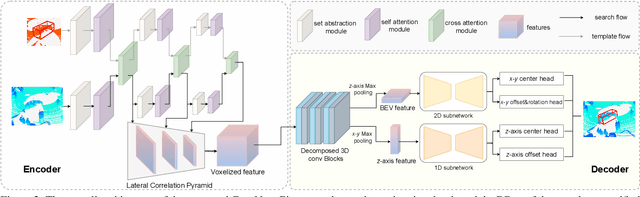
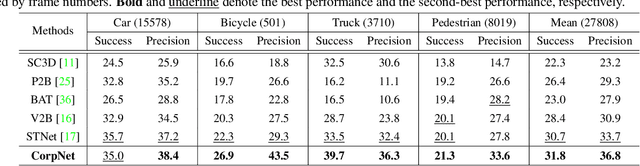
3D LiDAR-based single object tracking (SOT) has gained increasing attention as it plays a crucial role in 3D applications such as autonomous driving. The central problem is how to learn a target-aware representation from the sparse and incomplete point clouds. In this paper, we propose a novel Correlation Pyramid Network (CorpNet) with a unified encoder and a motion-factorized decoder. Specifically, the encoder introduces multi-level self attentions and cross attentions in its main branch to enrich the template and search region features and realize their fusion and interaction, respectively. Additionally, considering the sparsity characteristics of the point clouds, we design a lateral correlation pyramid structure for the encoder to keep as many points as possible by integrating hierarchical correlated features. The output features of the search region from the encoder can be directly fed into the decoder for predicting target locations without any extra matcher. Moreover, in the decoder of CorpNet, we design a motion-factorized head to explicitly learn the different movement patterns of the up axis and the x-y plane together. Extensive experiments on two commonly-used datasets show our CorpNet achieves state-of-the-art results while running in real-time.
Resilient Binary Neural Network
Feb 05, 2023



Binary neural networks (BNNs) have received ever-increasing popularity for their great capability of reducing storage burden as well as quickening inference time. However, there is a severe performance drop compared with real-valued networks, due to its intrinsic frequent weight oscillation during training. In this paper, we introduce a Resilient Binary Neural Network (ReBNN) to mitigate the frequent oscillation for better BNNs' training. We identify that the weight oscillation mainly stems from the non-parametric scaling factor. To address this issue, we propose to parameterize the scaling factor and introduce a weighted reconstruction loss to build an adaptive training objective. For the first time, we show that the weight oscillation is controlled by the balanced parameter attached to the reconstruction loss, which provides a theoretical foundation to parameterize it in back propagation. Based on this, we learn our ReBNN by calculating the balanced parameter based on its maximum magnitude, which can effectively mitigate the weight oscillation with a resilient training process. Extensive experiments are conducted upon various network models, such as ResNet and Faster-RCNN for computer vision, as well as BERT for natural language processing. The results demonstrate the overwhelming performance of our ReBNN over prior arts. For example, our ReBNN achieves 66.9% Top-1 accuracy with ResNet-18 backbone on the ImageNet dataset, surpassing existing state-of-the-arts by a significant margin. Our code is open-sourced at https://github.com/SteveTsui/ReBNN.
Recurrent Bilinear Optimization for Binary Neural Networks
Sep 04, 2022



Binary Neural Networks (BNNs) show great promise for real-world embedded devices. As one of the critical steps to achieve a powerful BNN, the scale factor calculation plays an essential role in reducing the performance gap to their real-valued counterparts. However, existing BNNs neglect the intrinsic bilinear relationship of real-valued weights and scale factors, resulting in a sub-optimal model caused by an insufficient training process. To address this issue, Recurrent Bilinear Optimization is proposed to improve the learning process of BNNs (RBONNs) by associating the intrinsic bilinear variables in the back propagation process. Our work is the first attempt to optimize BNNs from the bilinear perspective. Specifically, we employ a recurrent optimization and Density-ReLU to sequentially backtrack the sparse real-valued weight filters, which will be sufficiently trained and reach their performance limits based on a controllable learning process. We obtain robust RBONNs, which show impressive performance over state-of-the-art BNNs on various models and datasets. Particularly, on the task of object detection, RBONNs have great generalization performance. Our code is open-sourced on https://github.com/SteveTsui/RBONN .
ConvMAE: Masked Convolution Meets Masked Autoencoders
May 19, 2022



Vision Transformers (ViT) become widely-adopted architectures for various vision tasks. Masked auto-encoding for feature pretraining and multi-scale hybrid convolution-transformer architectures can further unleash the potentials of ViT, leading to state-of-the-art performances on image classification, detection and semantic segmentation. In this paper, our ConvMAE framework demonstrates that multi-scale hybrid convolution-transformer can learn more discriminative representations via the mask auto-encoding scheme. However, directly using the original masking strategy leads to the heavy computational cost and pretraining-finetuning discrepancy. To tackle the issue, we adopt the masked convolution to prevent information leakage in the convolution blocks. A simple block-wise masking strategy is proposed to ensure computational efficiency. We also propose to more directly supervise the multi-scale features of the encoder to boost multi-scale features. Based on our pretrained ConvMAE models, ConvMAE-Base improves ImageNet-1K finetuning accuracy by 1.4% compared with MAE-Base. On object detection, ConvMAE-Base finetuned for only 25 epochs surpasses MAE-Base fined-tuned for 100 epochs by 2.9% box AP and 2.2% mask AP respectively. Code and pretrained models are available at https://github.com/Alpha-VL/ConvMAE.
TerViT: An Efficient Ternary Vision Transformer
Jan 21, 2022



Vision transformers (ViTs) have demonstrated great potential in various visual tasks, but suffer from expensive computational and memory cost problems when deployed on resource-constrained devices. In this paper, we introduce a ternary vision transformer (TerViT) to ternarize the weights in ViTs, which are challenged by the large loss surface gap between real-valued and ternary parameters. To address the issue, we introduce a progressive training scheme by first training 8-bit transformers and then TerViT, and achieve a better optimization than conventional methods. Furthermore, we introduce channel-wise ternarization, by partitioning each matrix to different channels, each of which is with an unique distribution and ternarization interval. We apply our methods to popular DeiT and Swin backbones, and extensive results show that we can achieve competitive performance. For example, TerViT can quantize Swin-S to 13.1MB model size while achieving above 79% Top-1 accuracy on ImageNet dataset.
A Simple Long-Tailed Recognition Baseline via Vision-Language Model
Nov 29, 2021



The visual world naturally exhibits a long-tailed distribution of open classes, which poses great challenges to modern visual systems. Existing approaches either perform class re-balancing strategies or directly improve network modules to address the problem. However, they still train models with a finite set of predefined labels, limiting their supervision information and restricting their transferability to novel instances. Recent advances in large-scale contrastive visual-language pretraining shed light on a new pathway for visual recognition. With open-vocabulary supervisions, pretrained contrastive vision-language models learn powerful multimodal representations that are promising to handle data deficiency and unseen concepts. By calculating the semantic similarity between visual and text inputs, visual recognition is converted to a vision-language matching problem. Inspired by this, we propose BALLAD to leverage contrastive vision-language models for long-tailed recognition. We first continue pretraining the vision-language backbone through contrastive learning on a specific long-tailed target dataset. Afterward, we freeze the backbone and further employ an additional adapter layer to enhance the representations of tail classes on balanced training samples built with re-sampling strategies. Extensive experiments have been conducted on three popular long-tailed recognition benchmarks. As a result, our simple and effective approach sets the new state-of-the-art performances and outperforms competitive baselines with a large margin. Code is released at https://github.com/gaopengcuhk/BALLAD.
CLIP-Adapter: Better Vision-Language Models with Feature Adapters
Oct 09, 2021



Large-scale contrastive vision-language pre-training has shown significant progress in visual representation learning. Unlike traditional visual systems trained by a fixed set of discrete labels, a new paradigm was introduced in \cite{radford2021learning} to directly learn to align images with raw texts in an open-vocabulary setting. On downstream tasks, a carefully chosen text prompt is employed to make zero-shot predictions.~To avoid non-trivial prompt engineering, context optimization \cite{zhou2021coop} has been proposed to learn continuous vectors as task-specific prompts with few-shot training examples.~In this paper, we show that there is an alternative path to achieve better vision-language models other than prompt tuning.~While prompt tuning is for the textual inputs, we propose CLIP-Adapter to conduct fine-tuning with feature adapters on either visual or language branch. Specifically, CLIP-Adapter adopts an additional bottleneck layer to learn new features and performs residual-style feature blending with the original pre-trained features.~As a consequence, CLIP-Adapter is able to outperform context optimization while maintains a simple design. Experiments and extensive ablation studies on various visual classification tasks demonstrate the effectiveness of our approach.