 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeng Zhang
A Subspace-Constrained Tyler's Estimator and its Applications to Structure from Motion
Apr 17, 2024
We present the subspace-constrained Tyler's estimator (STE) designed for recovering a low-dimensional subspace within a dataset that may be highly corrupted with outliers. STE is a fusion of the Tyler's M-estimator (TME) and a variant of the fast median subspace. Our theoretical analysis suggests that, under a common inlier-outlier model, STE can effectively recover the underlying subspace, even when it contains a smaller fraction of inliers relative to other methods in the field of robust subspace recovery. We apply STE in the context of Structure from Motion (SfM) in two ways: for robust estimation of the fundamental matrix and for the removal of outlying cameras, enhancing the robustness of the SfM pipeline. Numerical experiments confirm the state-of-the-art performance of our method in these applications. This research makes significant contributions to the field of robust subspace recovery, particularly in the context of computer vision and 3D reconstruction.
Theoretical Guarantees for the Subspace-Constrained Tyler's Estimator
Mar 27, 2024This work analyzes the subspace-constrained Tyler's estimator (STE) designed for recovering a low-dimensional subspace within a dataset that may be highly corrupted with outliers. It assumes a weak inlier-outlier model and allows the fraction of inliers to be smaller than a fraction that leads to computational hardness of the robust subspace recovery problem. It shows that in this setting, if the initialization of STE, which is an iterative algorithm, satisfies a certain condition, then STE can effectively recover the underlying subspace. It further shows that under the generalized haystack model, STE initialized by the Tyler's M-estimator (TME), can recover the subspace when the fraction of iniliers is too small for TME to handle.
EnchantDance: Unveiling the Potential of Music-Driven Dance Movement
Dec 26, 2023The task of music-driven dance generation involves creating coherent dance movements that correspond to the given music. While existing methods can produce physically plausible dances, they often struggle to generalize to out-of-set data. The challenge arises from three aspects: 1) the high diversity of dance movements and significant differences in the distribution of music modalities, which make it difficult to generate music-aligned dance movements. 2) the lack of a large-scale music-dance dataset, which hinders the generation of generalized dance movements from music. 3) The protracted nature of dance movements poses a challenge to the maintenance of a consistent dance style. In this work, we introduce the EnchantDance framework, a state-of-the-art method for dance generation. Due to the redundancy of the original dance sequence along the time axis, EnchantDance first constructs a strong dance latent space and then trains a dance diffusion model on the dance latent space. To address the data gap, we construct a large-scale music-dance dataset, ChoreoSpectrum3D Dataset, which includes four dance genres and has a total duration of 70.32 hours, making it the largest reported music-dance dataset to date. To enhance consistency between music genre and dance style, we pre-train a music genre prediction network using transfer learning and incorporate music genre as extra conditional information in the training of the dance diffusion model. Extensive experiments demonstrate that our proposed framework achieves state-of-the-art performance on dance quality, diversity, and consistency.
Differentially Private Pre-Trained Model Fusion using Decentralized Federated Graph Matching
Nov 05, 2023Model fusion is becoming a crucial component in the context of model-as-a-service scenarios, enabling the delivery of high-quality model services to local users. However, this approach introduces privacy risks and imposes certain limitations on its applications. Ensuring secure model exchange and knowledge fusion among users becomes a significant challenge in this setting. To tackle this issue, we propose PrivFusion, a novel architecture that preserves privacy while facilitating model fusion under the constraints of local differential privacy. PrivFusion leverages a graph-based structure, enabling the fusion of models from multiple parties without necessitating retraining. By employing randomized mechanisms, PrivFusion ensures privacy guarantees throughout the fusion process. To enhance model privacy, our approach incorporates a hybrid local differentially private mechanism and decentralized federated graph matching, effectively protecting both activation values and weights. Additionally, we introduce a perturbation filter adapter to alleviate the impact of randomized noise, thereby preserving the utility of the fused model. Through extensive experiments conducted on diverse image datasets and real-world healthcare applications, we provide empirical evidence showcasing the effectiveness of PrivFusion in maintaining model performance while preserving privacy. Our contributions offer valuable insights and practical solutions for secure and collaborative data analysis within the domain of privacy-preserving model fusion.
Improved Convergence Rates of Anderson Acceleration for a Large Class of Fixed-Point Iterations
Nov 04, 2023This paper studies Anderson acceleration (AA) for fixed-point methods ${x}^{(k+1)}=q({x}^{(k)})$. It provides the first proof that when the operator $q$ is linear and symmetric, AA improves the root-linear convergence factor over the fixed-point iterations. When $q$ is nonlinear, yet has a symmetric Jacobian at the solution, a slightly modified AA algorithm is proved to have an analogous root-linear convergence factor improvement over fixed-point iterations. Simulations verify our observations. Furthermore, experiments with different data models demonstrate AA is significantly superior to the standard fixed-point methods for Tyler's M-estimation.
STGIN: Spatial-Temporal Graph Interaction Network for Large-scale POI Recommendation
Sep 05, 2023
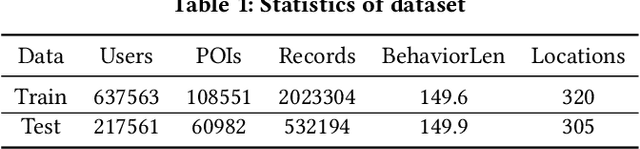
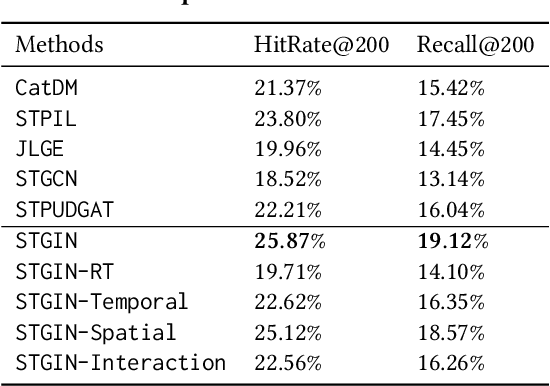

In Location-Based Services, Point-Of-Interest(POI) recommendation plays a crucial role in both user experience and business opportunities. Graph neural networks have been proven effective in providing personalized POI recommendation services. However, there are still two critical challenges. First, existing graph models attempt to capture users' diversified interests through a unified graph, which limits their ability to express interests in various spatial-temporal contexts. Second, the efficiency limitations of graph construction and graph sampling in large-scale systems make it difficult to adapt quickly to new real-time interests. To tackle the above challenges, we propose a novel Spatial-Temporal Graph Interaction Network. Specifically, we construct subgraphs of spatial, temporal, spatial-temporal, and global views respectively to precisely characterize the user's interests in various contexts. In addition, we design an industry-friendly framework to track the user's latest interests. Extensive experiments on the real-world dataset show that our method outperforms state-of-the-art models. This work has been successfully deployed in a large e-commerce platform, delivering a 1.1% CTR and 6.3% RPM improvement.
FedBone: Towards Large-Scale Federated Multi-Task Learning
Jun 30, 2023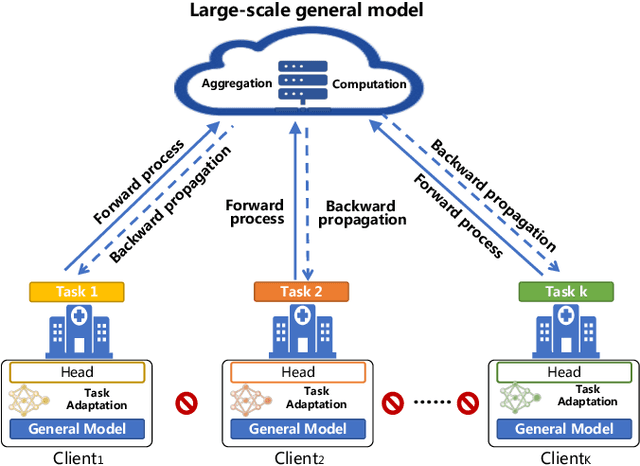

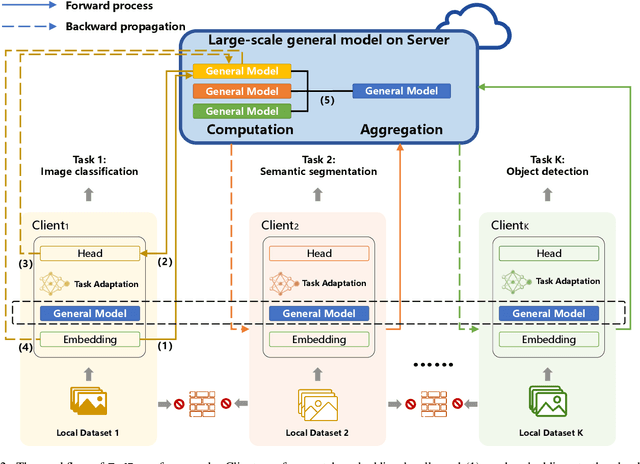
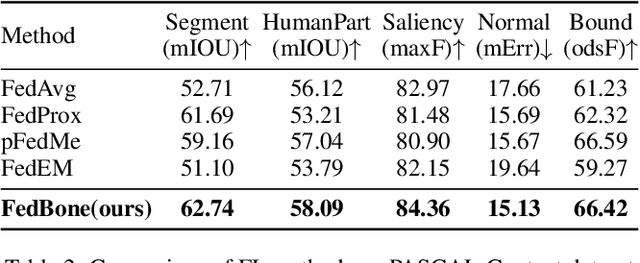
Heterogeneous federated multi-task learning (HFMTL) is a federated learning technique that combines heterogeneous tasks of different clients to achieve more accurate, comprehensive predictions. In real-world applications, visual and natural language tasks typically require large-scale models to extract high-level abstract features. However, large-scale models cannot be directly applied to existing federated multi-task learning methods. Existing HFML methods also disregard the impact of gradient conflicts on multi-task optimization during the federated aggregation process. In this work, we propose an innovative framework called FedBone, which enables the construction of large-scale models with better generalization from the perspective of server-client split learning and gradient projection. We split the entire model into two components: a large-scale general model (referred to as the general model) on the cloud server and multiple task-specific models (referred to as the client model) on edge clients, solving the problem of insufficient computing power on edge clients. The conflicting gradient projection technique is used to enhance the generalization of the large-scale general model between different tasks. The proposed framework is evaluated on two benchmark datasets and a real ophthalmic dataset. Comprehensive results demonstrate that FedBone efficiently adapts to heterogeneous local tasks of each client and outperforms existing federated learning algorithms in most dense prediction and classification tasks with off-the-shelf computational resources on the client side.
Scalable Optimal Margin Distribution Machine
May 08, 2023
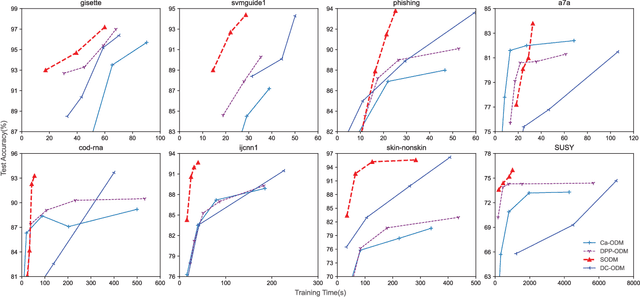
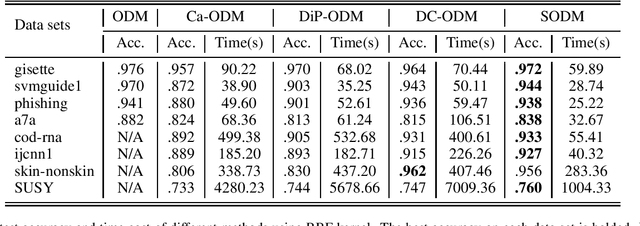
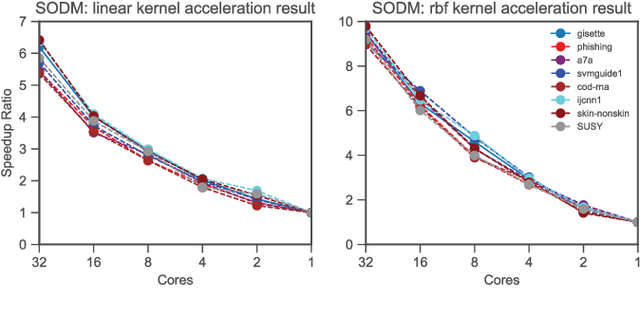
Optimal margin Distribution Machine (ODM) is a newly proposed statistical learning framework rooting in the novel margin theory, which demonstrates better generalization performance than the traditional large margin based counterparts. Nonetheless, it suffers from the ubiquitous scalability problem regarding both computation time and memory as other kernel methods. This paper proposes a scalable ODM, which can achieve nearly ten times speedup compared to the original ODM training method. For nonlinear kernels, we propose a novel distribution-aware partition method to make the local ODM trained on each partition be close and converge fast to the global one. When linear kernel is applied, we extend a communication efficient SVRG method to accelerate the training further. Extensive empirical studies validate that our proposed method is highly computational efficient and almost never worsen the generalization.
Understanding Overfitting in Adversarial Training via Kernel Regression
Apr 19, 2023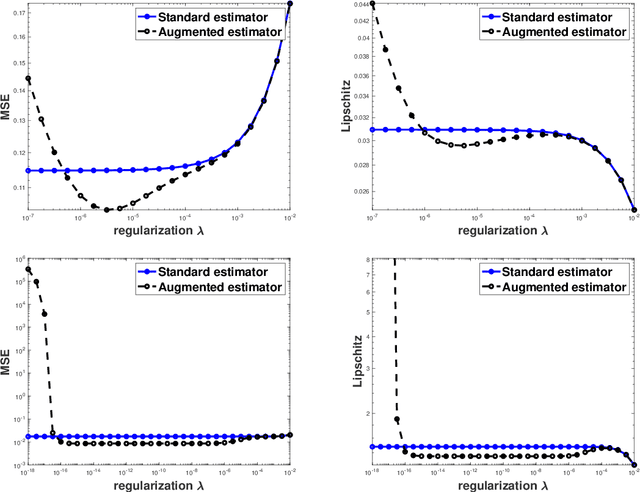
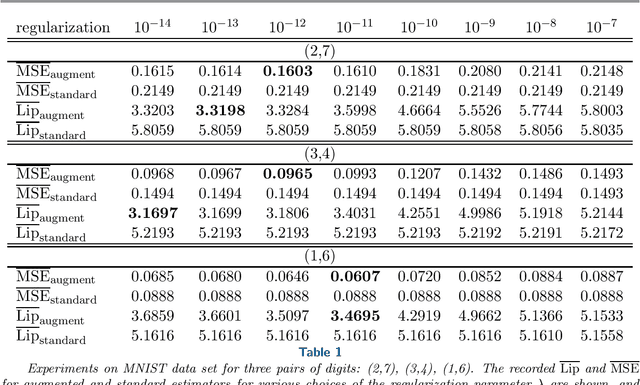

Adversarial training and data augmentation with noise are widely adopted techniques to enhance the performance of neural networks. This paper investigates adversarial training and data augmentation with noise in the context of regularized regression in a reproducing kernel Hilbert space (RKHS). We establish the limiting formula for these techniques as the attack and noise size, as well as the regularization parameter, tend to zero. Based on this limiting formula, we analyze specific scenarios and demonstrate that, without appropriate regularization, these two methods may have larger generalization error and Lipschitz constant than standard kernel regression. However, by selecting the appropriate regularization parameter, these two methods can outperform standard kernel regression and achieve smaller generalization error and Lipschitz constant. These findings support the empirical observations that adversarial training can lead to overfitting, and appropriate regularization methods, such as early stopping, can alleviate this issue.
Theoretical Guarantees for Sparse Principal Component Analysis based on the Elastic Net
Dec 29, 2022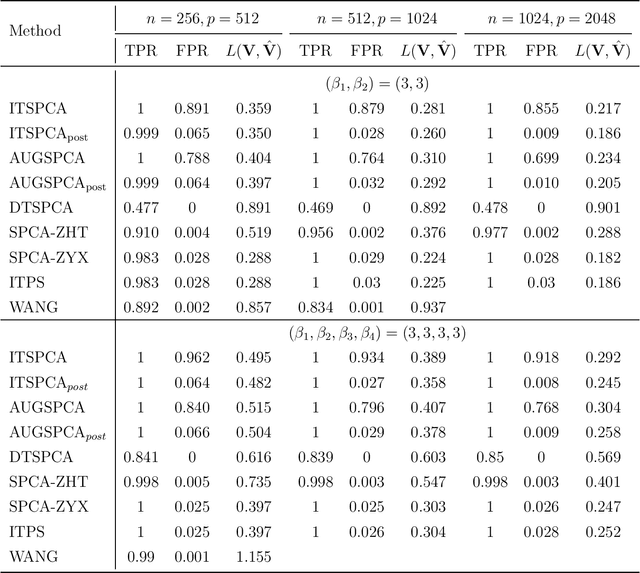
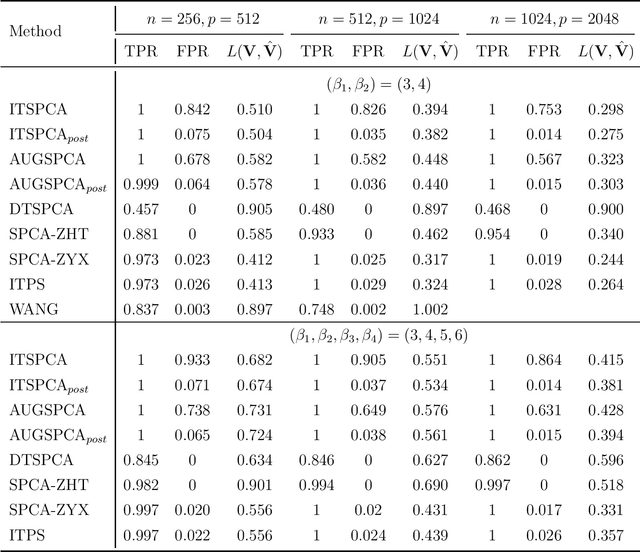
Sparse principal component analysis (SPCA) has been widely used for dimensionality reduction and feature extraction in high-dimensional data analysis. Despite there are many methodological and theoretical developments in the past two decades, the theoretical guarantees of the popular SPCA algorithm proposed by Zou, Hastie & Tibshirani (2006) based on the elastic net are still unknown. We aim to close this important theoretical gap in this paper. We first revisit the SPCA algorithm of Zou et al. (2006) and present our implementation. Also, we study a computationally more efficient variant of the SPCA algorithm in Zou et al. (2006) that can be considered as the limiting case of SPCA. We provide the guarantees of convergence to a stationary point for both algorithms. We prove that, under a sparse spiked covariance model, both algorithms can recover the principal subspace consistently under mild regularity conditions. We show that their estimation error bounds match the best available bounds of existing works or the minimax rates up to some logarithmic factors. Moreover, we demonstrate the numerical performance of both algorithms in simulation studies.