 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWei Kang
Rolling bearing fault diagnosis method based on generative adversarial enhanced multi-scale convolutional neural network model
Mar 21, 2024
In order to solve the problem that current convolutional neural networks can not capture the correlation features between the time domain signals of rolling bearings effectively, and the model accuracy is limited by the number and quality of samples, a rolling bearing fault diagnosis method based on generative adversarial enhanced multi-scale convolutional neural network model is proposed. Firstly, Gram angular field coding technique is used to encode the time domain signal of the rolling bearing and generate the feature map to retain the complete information of the vibration signal. Then, the re-sulting data is divided into a training set, a validation set, and a test set. Among them, the training set is input into the gradient penalty Wasserstein distance generation adversarial network to complete the training, and a new sample with similar features to the training sample is obtained, and then the original training set is expanded. Next, multi-scale convolution is used to extract the fault features of the extended training set, and the feature graph is normalized by example to overcome the influence of the difference in feature distribution. Finally, the attention mechanism is applied to the adaptive weighting of normalized features and the extraction of deep features, and the fault diagnosis is completed by the softmax classifier. Compared with ResNet method, the experimental results show that the proposed method has better generalization performance and anti-noise performance.
Zipformer: A faster and better encoder for automatic speech recognition
Oct 17, 2023The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
PromptASR for contextualized ASR with controllable style
Sep 20, 2023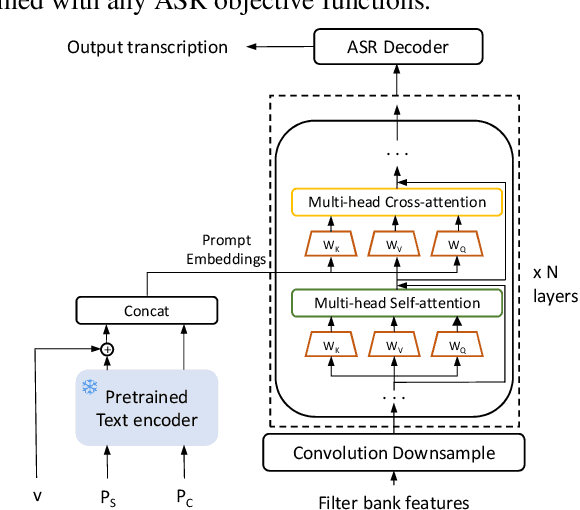
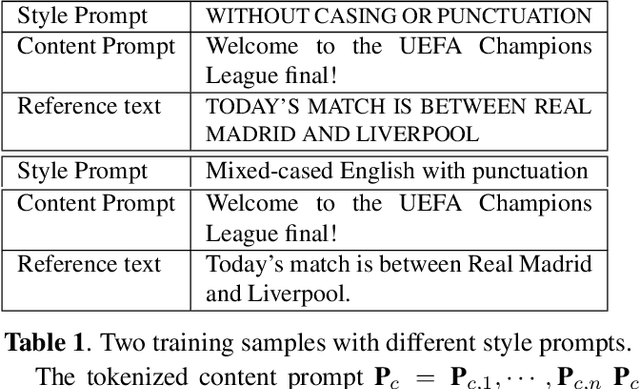
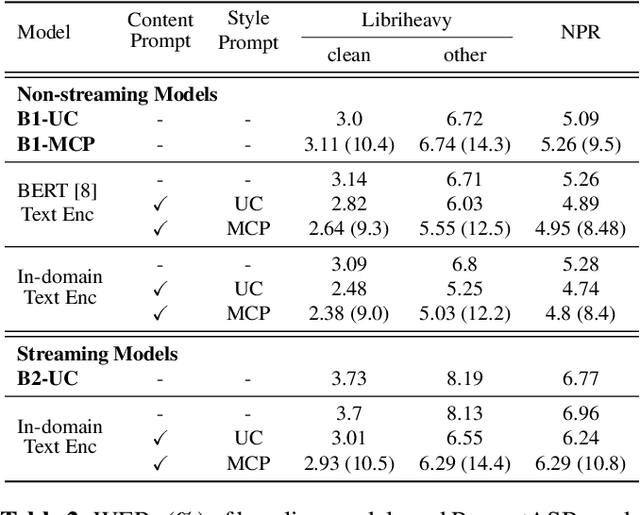

Prompts are crucial to large language models as they provide context information such as topic or logical relationships. Inspired by this, we propose PromptASR, a framework that integrates prompts in end-to-end automatic speech recognition (E2E ASR) systems to achieve contextualized ASR with controllable style of transcriptions. Specifically, a dedicated text encoder encodes the text prompts and the encodings are injected into the speech encoder by cross-attending the features from two modalities. When using the ground truth text from preceding utterances as content prompt, the proposed system achieves 21.9% and 6.8% relative word error rate reductions on a book reading dataset and an in-house dataset compared to a baseline ASR system. The system can also take word-level biasing lists as prompt to improve recognition accuracy on rare words. An additional style prompt can be given to the text encoder and guide the ASR system to output different styles of transcriptions. The code is available at icefall.
Libriheavy: a 50,000 hours ASR corpus with punctuation casing and context
Sep 15, 2023In this paper, we introduce Libriheavy, a large-scale ASR corpus consisting of 50,000 hours of read English speech derived from LibriVox. To the best of our knowledge, Libriheavy is the largest freely-available corpus of speech with supervisions. Different from other open-sourced datasets that only provide normalized transcriptions, Libriheavy contains richer information such as punctuation, casing and text context, which brings more flexibility for system building. Specifically, we propose a general and efficient pipeline to locate, align and segment the audios in previously published Librilight to its corresponding texts. The same as Librilight, Libriheavy also has three training subsets small, medium, large of the sizes 500h, 5000h, 50000h respectively. We also extract the dev and test evaluation sets from the aligned audios and guarantee there is no overlapping speakers and books in training sets. Baseline systems are built on the popular CTC-Attention and transducer models. Additionally, we open-source our dataset creatation pipeline which can also be used to other audio alignment tasks.
A Surrogate Data Assimilation Model for the Estimation of Dynamical System in a Limited Area
Jul 14, 2023



We propose a novel learning-based surrogate data assimilation (DA) model for efficient state estimation in a limited area. Our model employs a feedforward neural network for online computation, eliminating the need for integrating high-dimensional limited-area models. This approach offers significant computational advantages over traditional DA algorithms. Furthermore, our method avoids the requirement of lateral boundary conditions for the limited-area model in both online and offline computations. The design of our surrogate DA model is built upon a robust theoretical framework that leverages two fundamental concepts: observability and effective region. The concept of observability enables us to quantitatively determine the optimal amount of observation data necessary for accurate DA. Meanwhile, the concept of effective region substantially reduces the computational burden associated with computing observability and generating training data.
Delay-penalized CTC implemented based on Finite State Transducer
May 19, 2023



Connectionist Temporal Classification (CTC) suffers from the latency problem when applied to streaming models. We argue that in CTC lattice, the alignments that can access more future context are preferred during training, thereby leading to higher symbol delay. In this work we propose the delay-penalized CTC which is augmented with latency penalty regularization. We devise a flexible and efficient implementation based on the differentiable Finite State Transducer (FST). Specifically, by attaching a binary attribute to CTC topology, we can locate the frames that firstly emit non-blank tokens on the resulting CTC lattice, and add the frame offsets to the log-probabilities. Experimental results demonstrate the effectiveness of our proposed delay-penalized CTC, which is able to balance the delay-accuracy trade-off. Furthermore, combining the delay-penalized transducer enables the CTC model to achieve better performance and lower latency. Our work is open-sourced and publicly available https://github.com/k2-fsa/k2.
Blank-regularized CTC for Frame Skipping in Neural Transducer
May 19, 2023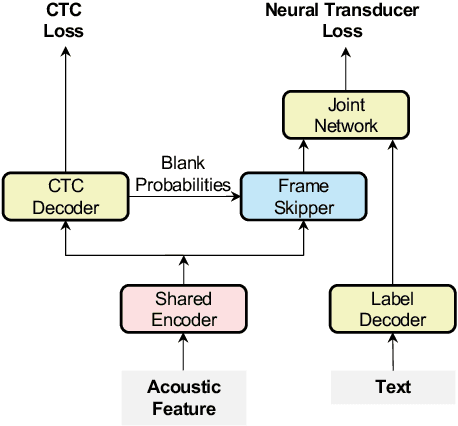
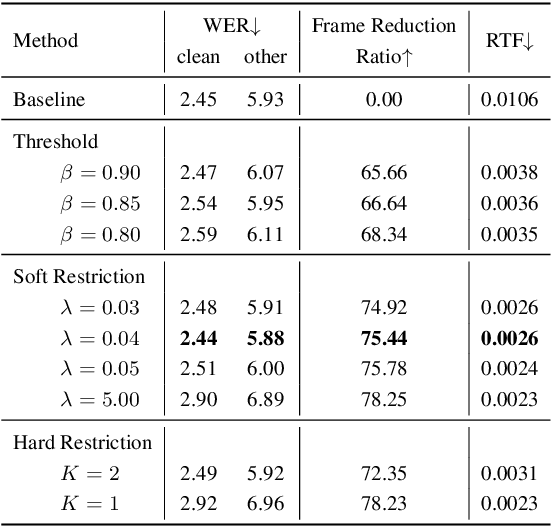
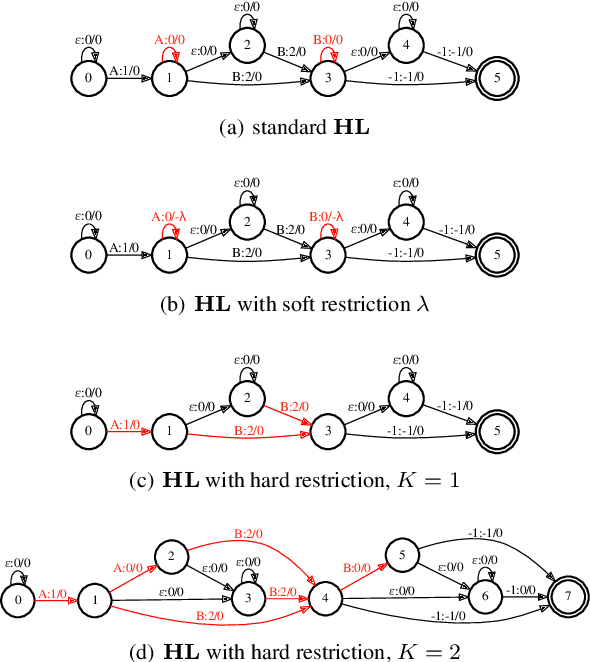
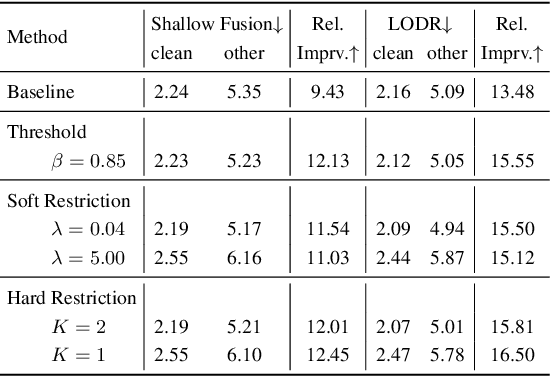
Neural Transducer and connectionist temporal classification (CTC) are popular end-to-end automatic speech recognition systems. Due to their frame-synchronous design, blank symbols are introduced to address the length mismatch between acoustic frames and output tokens, which might bring redundant computation. Previous studies managed to accelerate the training and inference of neural Transducers by discarding frames based on the blank symbols predicted by a co-trained CTC. However, there is no guarantee that the co-trained CTC can maximize the ratio of blank symbols. This paper proposes two novel regularization methods to explicitly encourage more blanks by constraining the self-loop of non-blank symbols in the CTC. It is interesting to find that the frame reduction ratio of the neural Transducer can approach the theoretical boundary. Experiments on LibriSpeech corpus show that our proposed method accelerates the inference of neural Transducer by 4 times without sacrificing performance. Our work is open-sourced and publicly available https://github.com/k2-fsa/icefall.
Delay-penalized transducer for low-latency streaming ASR
Oct 31, 2022



In streaming automatic speech recognition (ASR), it is desirable to reduce latency as much as possible while having minimum impact on recognition accuracy. Although a few existing methods are able to achieve this goal, they are difficult to implement due to their dependency on external alignments. In this paper, we propose a simple way to penalize symbol delay in transducer model, so that we can balance the trade-off between symbol delay and accuracy for streaming models without external alignments. Specifically, our method adds a small constant times (T/2 - t), where T is the number of frames and t is the current frame, to all the non-blank log-probabilities (after normalization) that are fed into the two dimensional transducer recursion. For both streaming Conformer models and unidirectional long short-term memory (LSTM) models, experimental results show that it can significantly reduce the symbol delay with an acceptable performance degradation. Our method achieves similar delay-accuracy trade-off to the previously published FastEmit, but we believe our method is preferable because it has a better justification: it is equivalent to penalizing the average symbol delay. Our work is open-sourced and publicly available (https://github.com/k2-fsa/k2).
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
Oct 31, 2022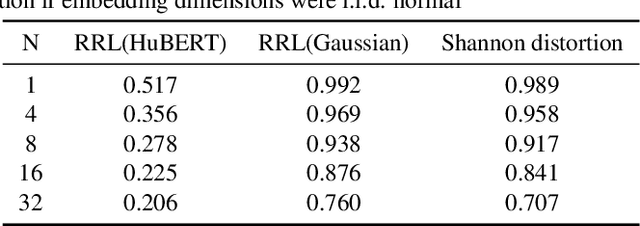
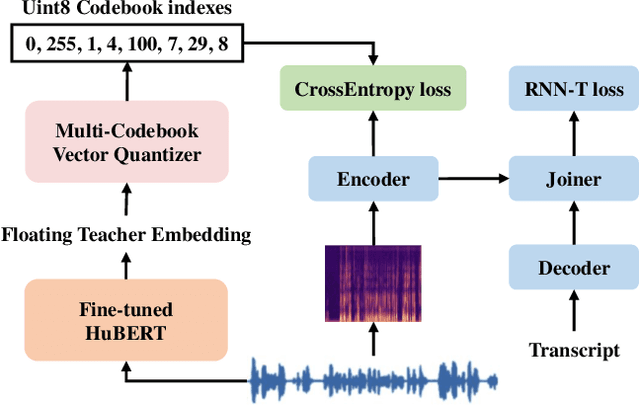


Knowledge distillation(KD) is a common approach to improve model performance in automatic speech recognition (ASR), where a student model is trained to imitate the output behaviour of a teacher model. However, traditional KD methods suffer from teacher label storage issue, especially when the training corpora are large. Although on-the-fly teacher label generation tackles this issue, the training speed is significantly slower as the teacher model has to be evaluated every batch. In this paper, we reformulate the generation of teacher label as a codec problem. We propose a novel Multi-codebook Vector Quantization (MVQ) approach that compresses teacher embeddings to codebook indexes (CI). Based on this, a KD training framework (MVQ-KD) is proposed where a student model predicts the CI generated from the embeddings of a self-supervised pre-trained teacher model. Experiments on the LibriSpeech clean-100 hour show that MVQ-KD framework achieves comparable performance as traditional KD methods (l1, l2), while requiring 256 times less storage. When the full LibriSpeech dataset is used, MVQ-KD framework results in 13.8% and 8.2% relative word error rate reductions (WERRs) for non -streaming transducer on test-clean and test-other and 4.0% and 4.9% for streaming transducer. The implementation of this work is already released as a part of the open-source project icefall.
Fast and parallel decoding for transducer
Oct 31, 2022



The transducer architecture is becoming increasingly popular in the field of speech recognition, because it is naturally streaming as well as high in accuracy. One of the drawbacks of transducer is that it is difficult to decode in a fast and parallel way due to an unconstrained number of symbols that can be emitted per time step. In this work, we introduce a constrained version of transducer loss to learn strictly monotonic alignments between the sequences; we also improve the standard greedy search and beam search algorithms by limiting the number of symbols that can be emitted per time step in transducer decoding, making it more efficient to decode in parallel with batches. Furthermore, we propose an finite state automaton-based (FSA) parallel beam search algorithm that can run with graphs on GPU efficiently. The experiment results show that we achieve slight word error rate (WER) improvement as well as significant speedup in decoding. Our work is open-sourced and publicly available\footnote{https://github.com/k2-fsa/icefall}.