 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXin Du
LAECIPS: Large Vision Model Assisted Adaptive Edge-Cloud Collaboration for IoT-based Perception System
Apr 16, 2024
Recent large vision models (e.g., SAM) enjoy great potential to facilitate intelligent perception with high accuracy. Yet, the resource constraints in the IoT environment tend to limit such large vision models to be locally deployed, incurring considerable inference latency thereby making it difficult to support real-time applications, such as autonomous driving and robotics. Edge-cloud collaboration with large-small model co-inference offers a promising approach to achieving high inference accuracy and low latency. However, existing edge-cloud collaboration methods are tightly coupled with the model architecture and cannot adapt to the dynamic data drifts in heterogeneous IoT environments. To address the issues, we propose LAECIPS, a new edge-cloud collaboration framework. In LAECIPS, both the large vision model on the cloud and the lightweight model on the edge are plug-and-play. We design an edge-cloud collaboration strategy based on hard input mining, optimized for both high accuracy and low latency. We propose to update the edge model and its collaboration strategy with the cloud under the supervision of the large vision model, so as to adapt to the dynamic IoT data streams. Theoretical analysis of LAECIPS proves its feasibility. Experiments conducted in a robotic semantic segmentation system using real-world datasets show that LAECIPS outperforms its state-of-the-art competitors in accuracy, latency, and communication overhead while having better adaptability to dynamic environments.
A Hierarchical Framework with Spatio-Temporal Consistency Learning for Emergence Detection in Complex Adaptive Systems
Jan 18, 2024Emergence, a global property of complex adaptive systems (CASs) constituted by interactive agents, is prevalent in real-world dynamic systems, e.g., network-level traffic congestions. Detecting its formation and evaporation helps to monitor the state of a system, allowing to issue a warning signal for harmful emergent phenomena. Since there is no centralized controller of CAS, detecting emergence based on each agent's local observation is desirable but challenging. Existing works are unable to capture emergence-related spatial patterns, and fail to model the nonlinear relationships among agents. This paper proposes a hierarchical framework with spatio-temporal consistency learning to solve these two problems by learning the system representation and agent representations, respectively. Especially, spatio-temporal encoders are tailored to capture agents' nonlinear relationships and the system's complex evolution. Representations of the agents and the system are learned by preserving the intrinsic spatio-temporal consistency in a self-supervised manner. Our method achieves more accurate detection than traditional methods and deep learning methods on three datasets with well-known yet hard-to-detect emergent behaviors. Notably, our hierarchical framework is generic, which can employ other deep learning methods for agent-level and system-level detection.
Digital Twin Brain: a simulation and assimilation platform for whole human brain
Aug 02, 2023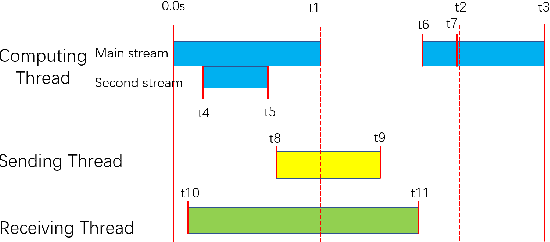
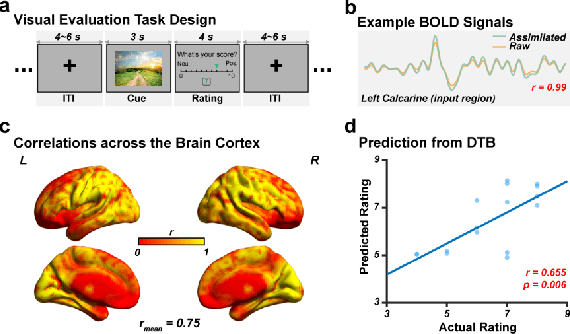
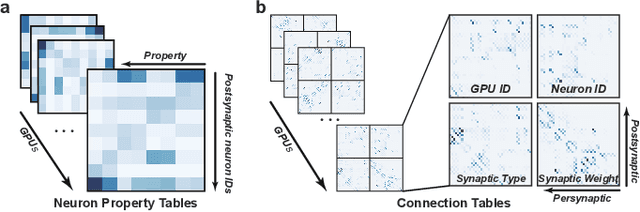
In this work, we present a computing platform named digital twin brain (DTB) that can simulate spiking neuronal networks of the whole human brain scale and more importantly, a personalized biological brain structure. In comparison to most brain simulations with a homogeneous global structure, we highlight that the sparseness, couplingness and heterogeneity in the sMRI, DTI and PET data of the brain has an essential impact on the efficiency of brain simulation, which is proved from the scaling experiments that the DTB of human brain simulation is communication-intensive and memory-access intensive computing systems rather than computation-intensive. We utilize a number of optimization techniques to balance and integrate the computation loads and communication traffics from the heterogeneous biological structure to the general GPU-based HPC and achieve leading simulation performance for the whole human brain-scaled spiking neuronal networks. On the other hand, the biological structure, equipped with a mesoscopic data assimilation, enables the DTB to investigate brain cognitive function by a reverse-engineering method, which is demonstrated by a digital experiment of visual evaluation on the DTB. Furthermore, we believe that the developing DTB will be a promising powerful platform for a large of research orients including brain-inspiredintelligence, rain disease medicine and brain-machine interface.
Physical-layer Adversarial Robustness for Deep Learning-based Semantic Communications
May 12, 2023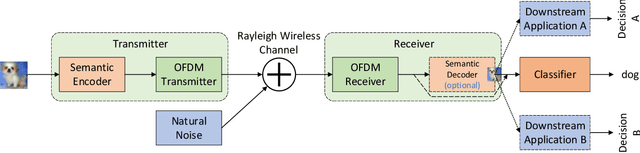


End-to-end semantic communications (ESC) rely on deep neural networks (DNN) to boost communication efficiency by only transmitting the semantics of data, showing great potential for high-demand mobile applications. We argue that central to the success of ESC is the robust interpretation of conveyed semantics at the receiver side, especially for security-critical applications such as automatic driving and smart healthcare. However, robustifying semantic interpretation is challenging as ESC is extremely vulnerable to physical-layer adversarial attacks due to the openness of wireless channels and the fragileness of neural models. Toward ESC robustness in practice, we ask the following two questions: Q1: For attacks, is it possible to generate semantic-oriented physical-layer adversarial attacks that are imperceptible, input-agnostic and controllable? Q2: Can we develop a defense strategy against such semantic distortions and previously proposed adversaries? To this end, we first present MobileSC, a novel semantic communication framework that considers the computation and memory efficiency in wireless environments. Equipped with this framework, we propose SemAdv, a physical-layer adversarial perturbation generator that aims to craft semantic adversaries over the air with the abovementioned criteria, thus answering the Q1. To better characterize the realworld effects for robust training and evaluation, we further introduce a novel adversarial training method SemMixed to harden the ESC against SemAdv attacks and existing strong threats, thus answering the Q2. Extensive experiments on three public benchmarks verify the effectiveness of our proposed methods against various physical adversarial attacks. We also show some interesting findings, e.g., our MobileSC can even be more robust than classical block-wise communication systems in the low SNR regime.
Cross-Modal Retrieval for Motion and Text via MildTriple Loss
May 07, 2023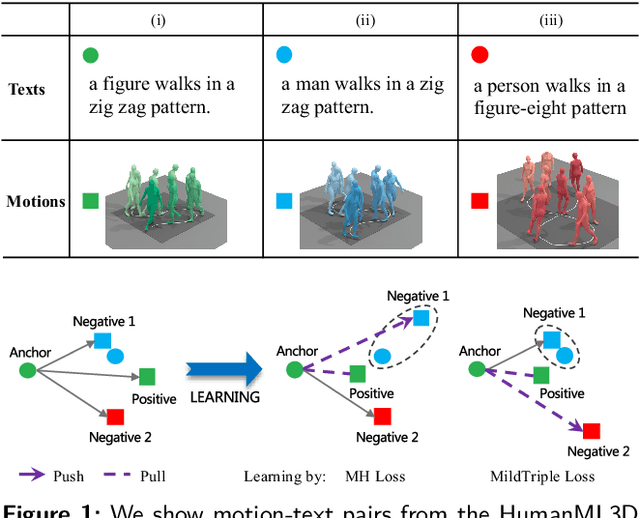
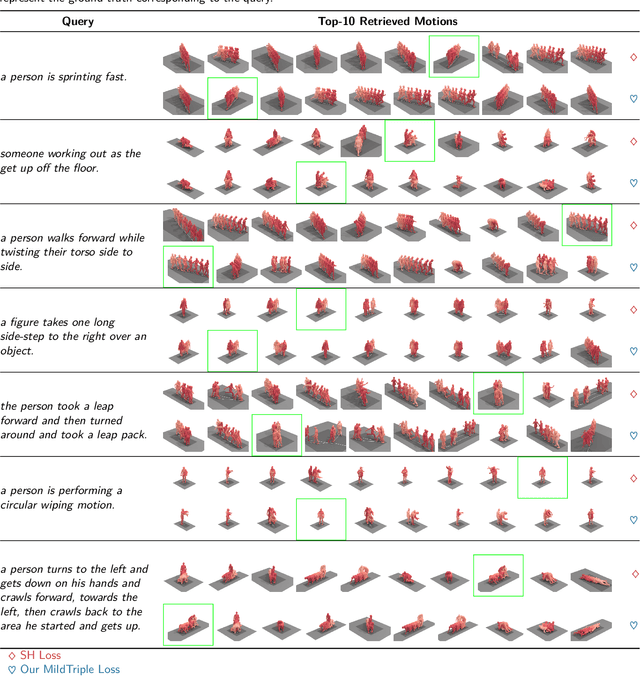
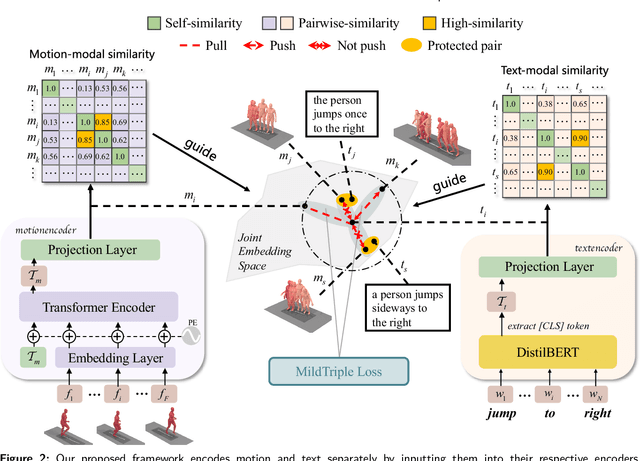

Cross-modal retrieval has become a prominent research topic in computer vision and natural language processing with advances made in image-text and video-text retrieval technologies. However, cross-modal retrieval between human motion sequences and text has not garnered sufficient attention despite the extensive application value it holds, such as aiding virtual reality applications in better understanding users' actions and language. This task presents several challenges, including joint modeling of the two modalities, demanding the understanding of person-centered information from text, and learning behavior features from 3D human motion sequences. Previous work on motion data modeling mainly relied on autoregressive feature extractors that may forget previous information, while we propose an innovative model that includes simple yet powerful transformer-based motion and text encoders, which can learn representations from the two different modalities and capture long-term dependencies. Furthermore, the overlap of the same atomic actions of different human motions can cause semantic conflicts, leading us to explore a new triplet loss function, MildTriple Loss. it leverages the similarity between samples in intra-modal space to guide soft-hard negative sample mining in the joint embedding space to train the triplet loss and reduce the violation caused by false negative samples. We evaluated our model and method on the latest HumanML3D and KIT Motion-Language datasets, achieving a 62.9\% recall for motion retrieval and a 71.5\% recall for text retrieval (based on R@10) on the HumanML3D dataset. Our code is available at https://github.com/eanson023/rehamot.
Universal Adversarial Backdoor Attacks to Fool Vertical Federated Learning in Cloud-Edge Collaboration
Apr 22, 2023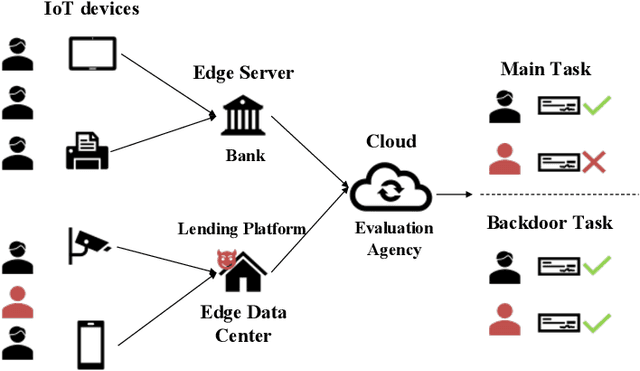
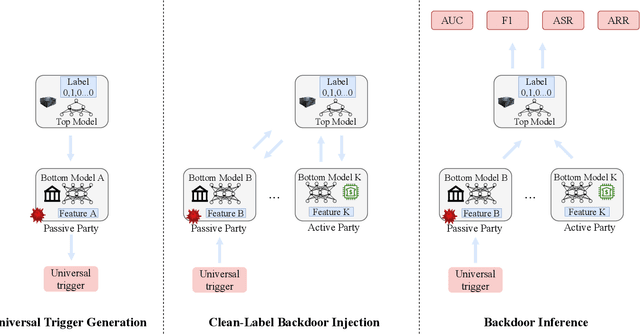
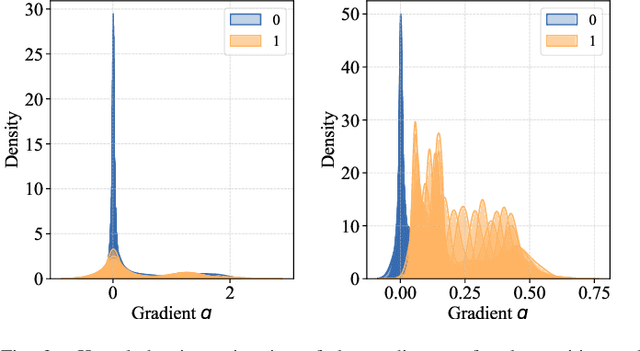
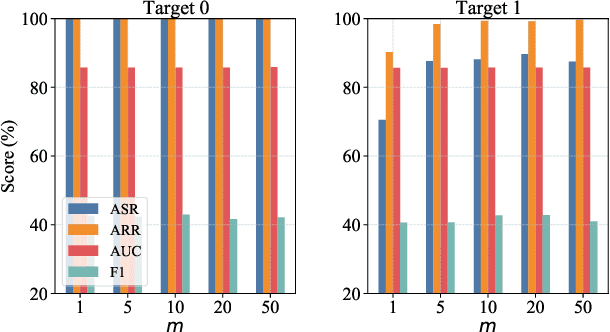
Vertical federated learning (VFL) is a cloud-edge collaboration paradigm that enables edge nodes, comprising resource-constrained Internet of Things (IoT) devices, to cooperatively train artificial intelligence (AI) models while retaining their data locally. This paradigm facilitates improved privacy and security for edges and IoT devices, making VFL an essential component of Artificial Intelligence of Things (AIoT) systems. Nevertheless, the partitioned structure of VFL can be exploited by adversaries to inject a backdoor, enabling them to manipulate the VFL predictions. In this paper, we aim to investigate the vulnerability of VFL in the context of binary classification tasks. To this end, we define a threat model for backdoor attacks in VFL and introduce a universal adversarial backdoor (UAB) attack to poison the predictions of VFL. The UAB attack, consisting of universal trigger generation and clean-label backdoor injection, is incorporated during the VFL training at specific iterations. This is achieved by alternately optimizing the universal trigger and model parameters of VFL sub-problems. Our work distinguishes itself from existing studies on designing backdoor attacks for VFL, as those require the knowledge of auxiliary information not accessible within the split VFL architecture. In contrast, our approach does not necessitate any additional data to execute the attack. On the LendingClub and Zhongyuan datasets, our approach surpasses existing state-of-the-art methods, achieving up to 100\% backdoor task performance while maintaining the main task performance. Our results in this paper make a major advance to revealing the hidden backdoor risks of VFL, hence paving the way for the future development of secure AIoT.
ClassPruning: Speed Up Image Restoration Networks by Dynamic N:M Pruning
Nov 10, 2022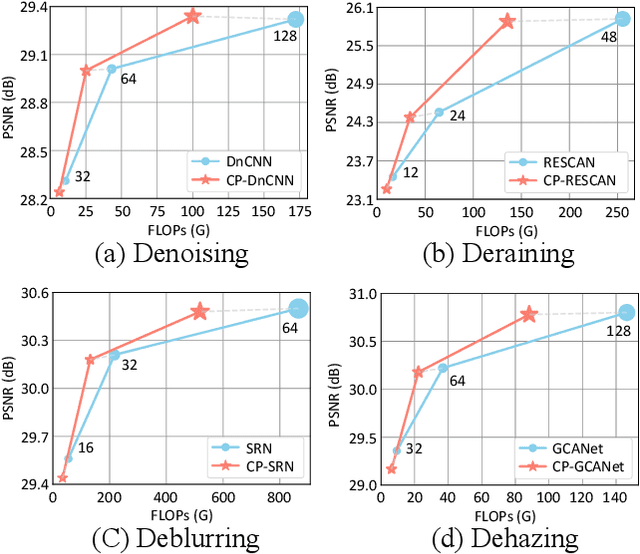
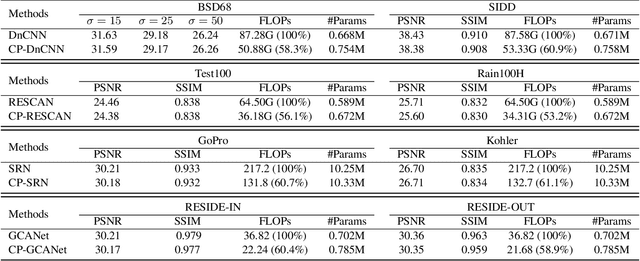

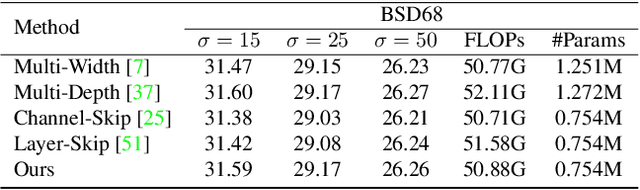
Image restoration tasks have achieved tremendous performance improvements with the rapid advancement of deep neural networks. However, most prevalent deep learning models perform inference statically, ignoring that different images have varying restoration difficulties and lightly degraded images can be well restored by slimmer subnetworks. To this end, we propose a new solution pipeline dubbed ClassPruning that utilizes networks with different capabilities to process images with varying restoration difficulties. In particular, we use a lightweight classifier to identify the image restoration difficulty, and then the sparse subnetworks with different capabilities can be sampled based on predicted difficulty by performing dynamic N:M fine-grained structured pruning on base restoration networks. We further propose a novel training strategy along with two additional loss terms to stabilize training and improve performance. Experiments demonstrate that ClassPruning can help existing methods save approximately 40% FLOPs while maintaining performance.
Modular Degradation Simulation and Restoration for Under-Display Camera
Sep 23, 2022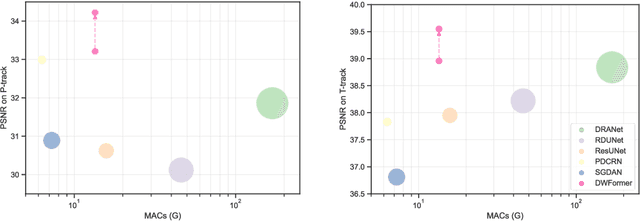
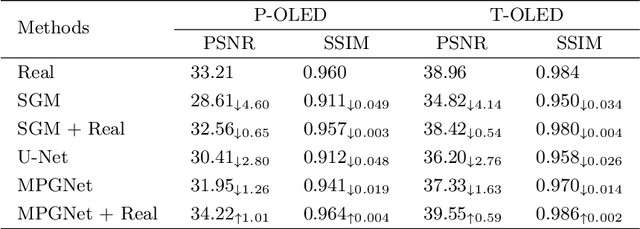
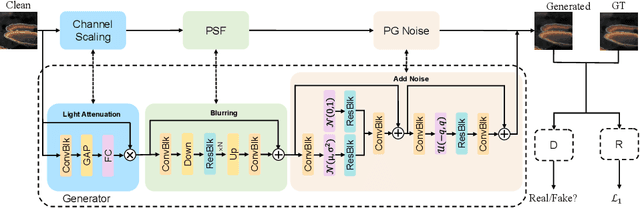
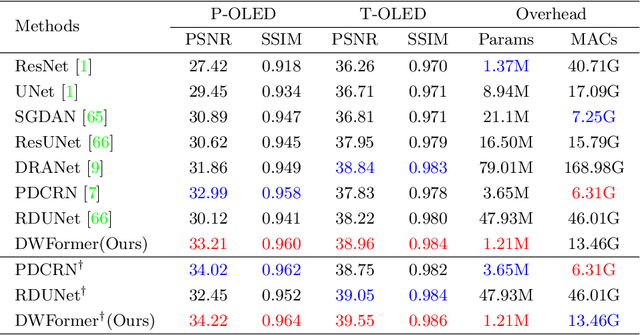
Under-display camera (UDC) provides an elegant solution for full-screen smartphones. However, UDC captured images suffer from severe degradation since sensors lie under the display. Although this issue can be tackled by image restoration networks, these networks require large-scale image pairs for training. To this end, we propose a modular network dubbed MPGNet trained using the generative adversarial network (GAN) framework for simulating UDC imaging. Specifically, we note that the UDC imaging degradation process contains brightness attenuation, blurring, and noise corruption. Thus we model each degradation with a characteristic-related modular network, and all modular networks are cascaded to form the generator. Together with a pixel-wise discriminator and supervised loss, we can train the generator to simulate the UDC imaging degradation process. Furthermore, we present a Transformer-style network named DWFormer for UDC image restoration. For practical purposes, we use depth-wise convolution instead of the multi-head self-attention to aggregate local spatial information. Moreover, we propose a novel channel attention module to aggregate global information, which is critical for brightness recovery. We conduct evaluations on the UDC benchmark, and our method surpasses the previous state-of-the-art models by 1.23 dB on the P-OLED track and 0.71 dB on the T-OLED track, respectively.
Rethinking Performance Gains in Image Dehazing Networks
Sep 23, 2022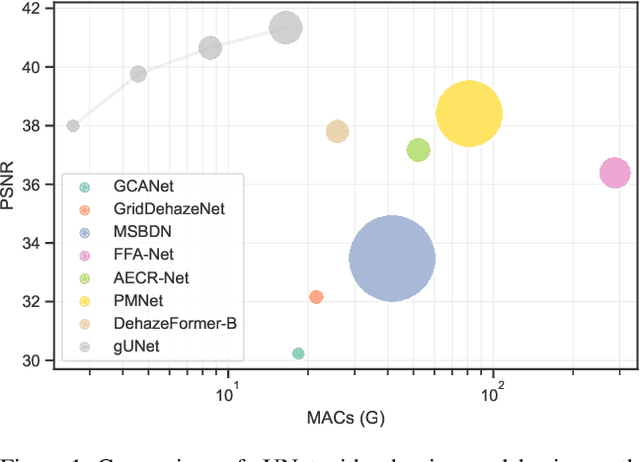
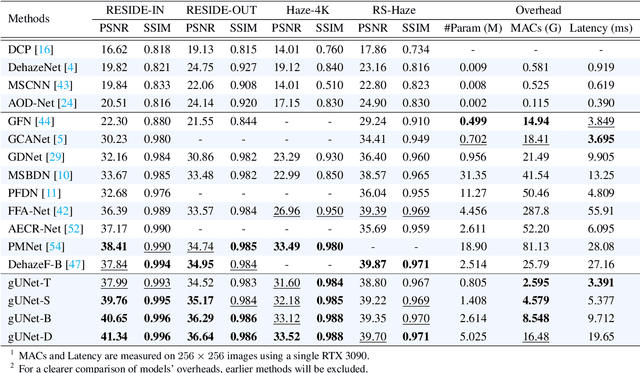
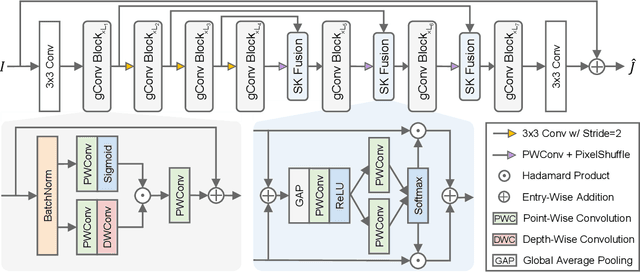
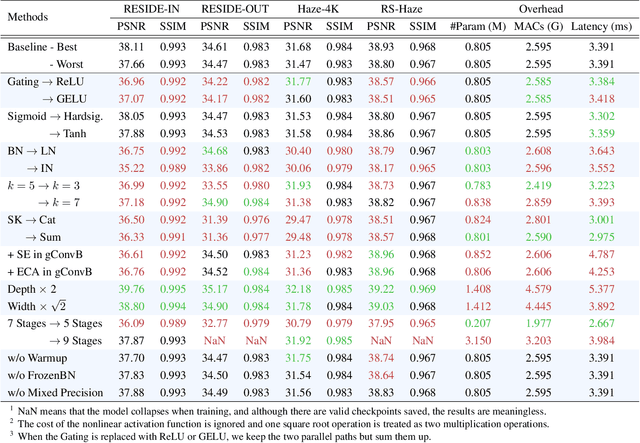
Image dehazing is an active topic in low-level vision, and many image dehazing networks have been proposed with the rapid development of deep learning. Although these networks' pipelines work fine, the key mechanism to improving image dehazing performance remains unclear. For this reason, we do not target to propose a dehazing network with fancy modules; rather, we make minimal modifications to popular U-Net to obtain a compact dehazing network. Specifically, we swap out the convolutional blocks in U-Net for residual blocks with the gating mechanism, fuse the feature maps of main paths and skip connections using the selective kernel, and call the resulting U-Net variant gUNet. As a result, with a significantly reduced overhead, gUNet is superior to state-of-the-art methods on multiple image dehazing datasets. Finally, we verify these key designs to the performance gain of image dehazing networks through extensive ablation studies.
FreSCo: Frequency-Domain Scan Context for LiDAR-based Place Recognition with Translation and Rotation Invariance
Jun 25, 2022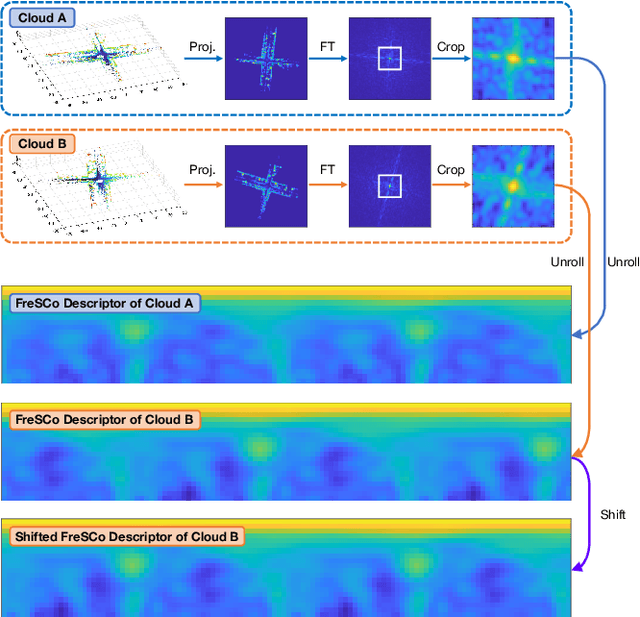
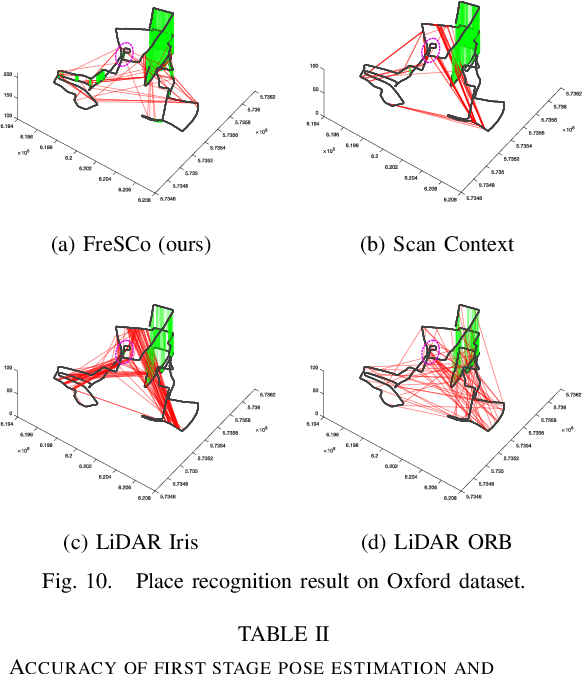
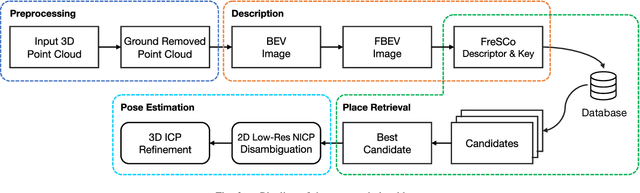
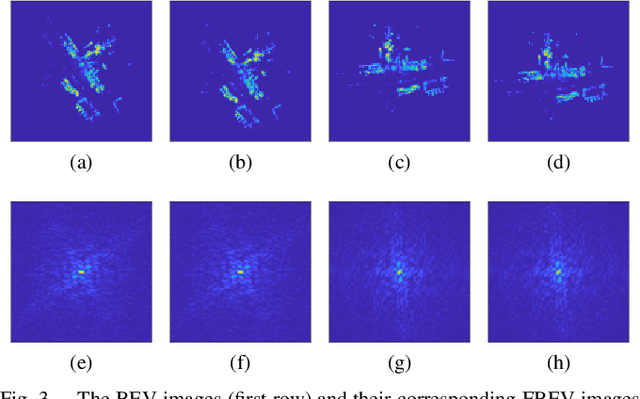
Place recognition plays a crucial role in re-localization and loop closure detection tasks for robots and vehicles. This paper seeks a well-defined global descriptor for LiDAR-based place recognition. Compared to local descriptors, global descriptors show remarkable performance in urban road scenes but are usually viewpoint-dependent. To this end, we propose a simple yet robust global descriptor dubbed FreSCo that decomposes the viewpoint difference during revisit and achieves both translation and rotation invariance by leveraging Fourier Transform and circular shift technique. Besides, a fast two-stage pose estimation method is proposed to estimate the relative pose after place retrieval by utilizing the compact 2D point cloud extracted from the scenes. Experiments show that FreSCo exhibited superior performance than contemporaneous methods on sequences of different scenes from multiple datasets. The code will be publicly available at https://github.com/soytony/FreSCo.