 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Hou
How Well Do Large Language Models Understand Syntax? An Evaluation by Asking Natural Language Questions
Nov 14, 2023
While recent advancements in large language models (LLMs) bring us closer to achieving artificial general intelligence, the question persists: Do LLMs truly understand language, or do they merely mimic comprehension through pattern recognition? This study seeks to explore this question through the lens of syntax, a crucial component of sentence comprehension. Adopting a natural language question-answering (Q&A) scheme, we craft questions targeting nine syntactic knowledge points that are most closely related to sentence comprehension. Experiments conducted on 24 LLMs suggest that most have a limited grasp of syntactic knowledge, exhibiting notable discrepancies across different syntactic knowledge points. In particular, questions involving prepositional phrase attachment pose the greatest challenge, whereas those concerning adjectival modifier and indirect object are relatively easier for LLMs to handle. Furthermore, a case study on the training dynamics of the LLMs reveals that the majority of syntactic knowledge is learned during the initial stages of training, hinting that simply increasing the number of training tokens may not be the `silver bullet' for improving the comprehension ability of LLMs.
Is It Really Useful to Jointly Parse Constituency and Dependency Trees? A Revisit
Sep 21, 2023This work visits the topic of jointly parsing constituency and dependency trees, i.e., to produce compatible constituency and dependency trees simultaneously for input sentences, which is attractive considering that the two types of trees are complementary in representing syntax. Compared with previous works, we make progress in four aspects: (1) adopting a much more efficient decoding algorithm, (2) exploring joint modeling at the training phase, instead of only at the inference phase, (3) proposing high-order scoring components for constituent-dependency interaction, (4) gaining more insights via in-depth experiments and analysis.
Evading DeepFake Detectors via Adversarial Statistical Consistency
Apr 23, 2023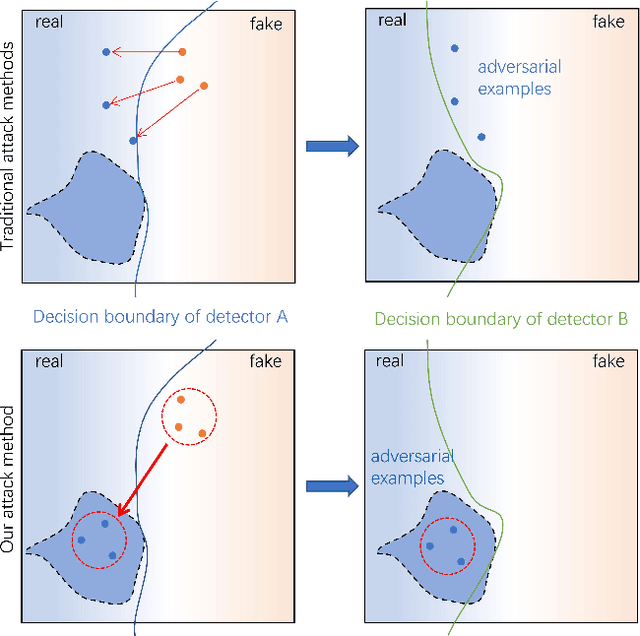
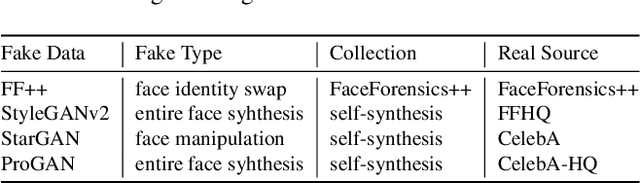
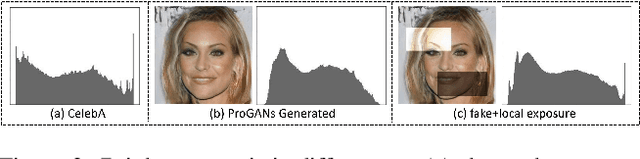
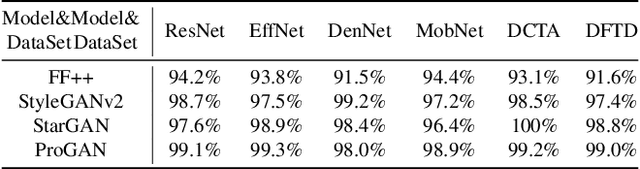
In recent years, as various realistic face forgery techniques known as DeepFake improves by leaps and bounds,more and more DeepFake detection techniques have been proposed. These methods typically rely on detecting statistical differences between natural (i.e., real) and DeepFakegenerated images in both spatial and frequency domains. In this work, we propose to explicitly minimize the statistical differences to evade state-of-the-art DeepFake detectors. To this end, we propose a statistical consistency attack (StatAttack) against DeepFake detectors, which contains two main parts. First, we select several statistical-sensitive natural degradations (i.e., exposure, blur, and noise) and add them to the fake images in an adversarial way. Second, we find that the statistical differences between natural and DeepFake images are positively associated with the distribution shifting between the two kinds of images, and we propose to use a distribution-aware loss to guide the optimization of different degradations. As a result, the feature distributions of generated adversarial examples is close to the natural images.Furthermore, we extend the StatAttack to a more powerful version, MStatAttack, where we extend the single-layer degradation to multi-layer degradations sequentially and use the loss to tune the combination weights jointly. Comprehensive experimental results on four spatial-based detectors and two frequency-based detectors with four datasets demonstrate the effectiveness of our proposed attack method in both white-box and black-box settings.