 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYang Xie
Disentangled Latent Representation Learning for Tackling the Confounding M-Bias Problem in Causal Inference
Dec 08, 2023
In causal inference, it is a fundamental task to estimate the causal effect from observational data. However, latent confounders pose major challenges in causal inference in observational data, for example, confounding bias and M-bias. Recent data-driven causal effect estimators tackle the confounding bias problem via balanced representation learning, but assume no M-bias in the system, thus they fail to handle the M-bias. In this paper, we identify a challenging and unsolved problem caused by a variable that leads to confounding bias and M-bias simultaneously. To address this problem with co-occurring M-bias and confounding bias, we propose a novel Disentangled Latent Representation learning framework for learning latent representations from proxy variables for unbiased Causal effect Estimation (DLRCE) from observational data. Specifically, DLRCE learns three sets of latent representations from the measured proxy variables to adjust for the confounding bias and M-bias. Extensive experiments on both synthetic and three real-world datasets demonstrate that DLRCE significantly outperforms the state-of-the-art estimators in the case of the presence of both confounding bias and M-bias.
Research And Implementation Of Drug Target Interaction Confidence Measurement Method Based On Causal Intervention
May 31, 2023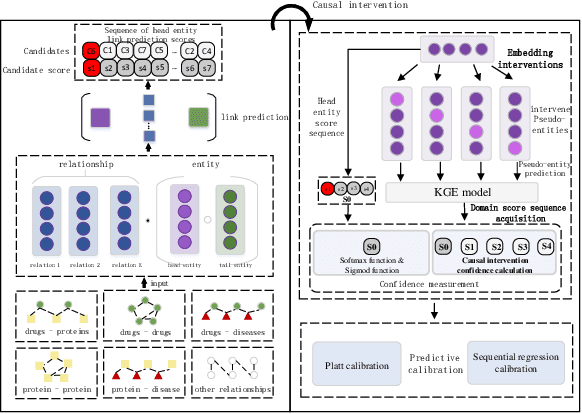
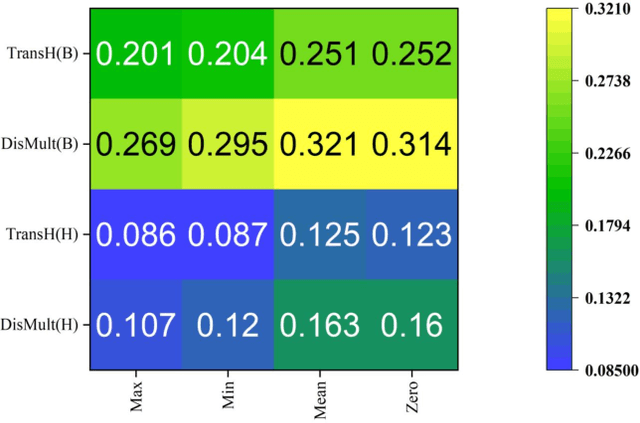
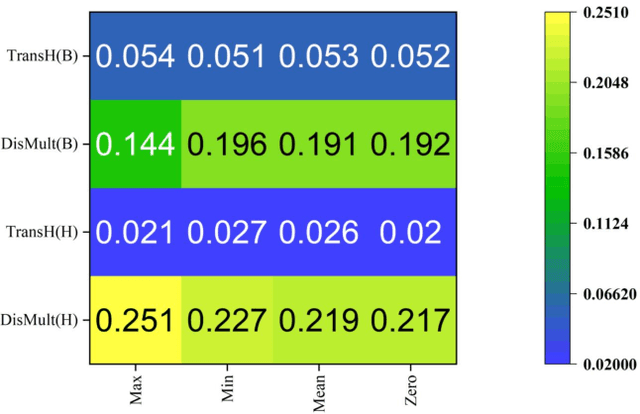
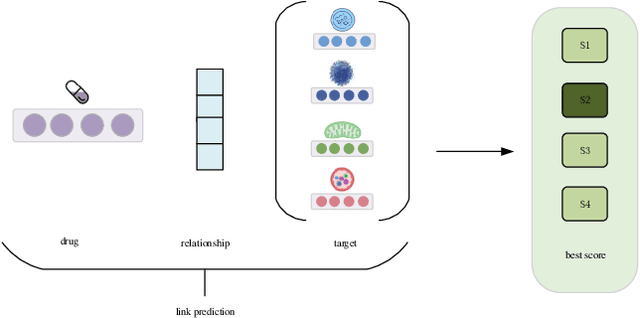
The identification and discovery of drug-target Interaction (DTI) is an important step in the field of Drug research and development, which can help scientists discover new drugs and accelerate the development process. KnowledgeGraph and the related knowledge graph Embedding (KGE) model develop rapidly and show good performance in the field of drug discovery in recent years. In the task of drug target identification, the lack of authenticity and accuracy of the model will lead to the increase of misjudgment rate and the low efficiency of drug development. To solve the above problems, this study focused on the problem of drug target link prediction with knowledge mapping as the core technology, and adopted the confidence measurement method based on causal intervention to measure the triplet score, so as to improve the accuracy of drug target interaction prediction model. By comparing with the traditional Softmax and Sigmod confidence measurement methods on different KGE models, the results show that the confidence measurement method based on causal intervention can effectively improve the accuracy of DTI link prediction, especially for high-precision models. The predicted results are more conducive to guiding the design and development of followup experiments of drug development, so as to improve the efficiency of drug development.
hBert + BiasCorp -- Fighting Racism on the Web
Apr 06, 2021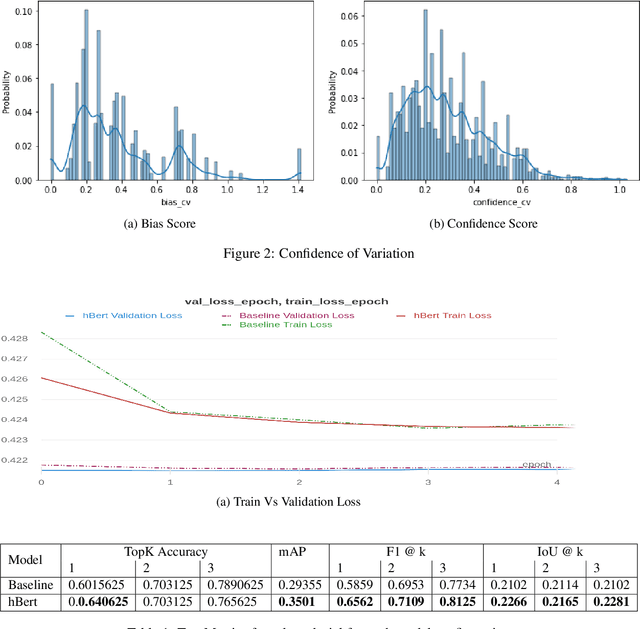
Subtle and overt racism is still present both in physical and online communities today and has impacted many lives in different segments of the society. In this short piece of work, we present how we're tackling this societal issue with Natural Language Processing. We are releasing BiasCorp, a dataset containing 139,090 comments and news segment from three specific sources - Fox News, BreitbartNews and YouTube. The first batch (45,000 manually annotated) is ready for publication. We are currently in the final phase of manually labeling the remaining dataset using Amazon Mechanical Turk. BERT has been used widely in several downstream tasks. In this work, we present hBERT, where we modify certain layers of the pretrained BERT model with the new Hopfield Layer. hBert generalizes well across different distributions with the added advantage of a reduced model complexity. We are also releasing a JavaScript library and a Chrome Extension Application, to help developers make use of our trained model in web applications (say chat application) and for users to identify and report racially biased contents on the web respectively.
ConvPath: A Software Tool for Lung Adenocarcinoma Digital Pathological Image Analysis Aided by Convolutional Neural Network
Sep 20, 2018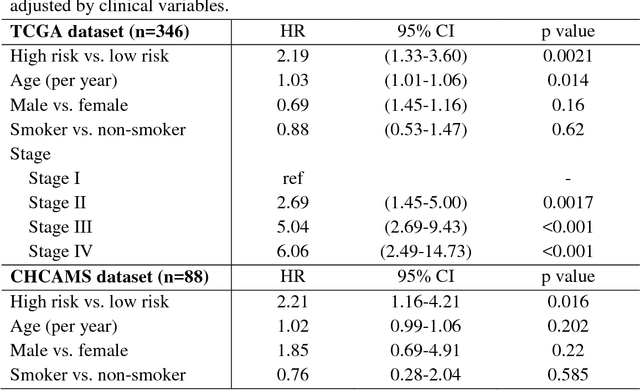
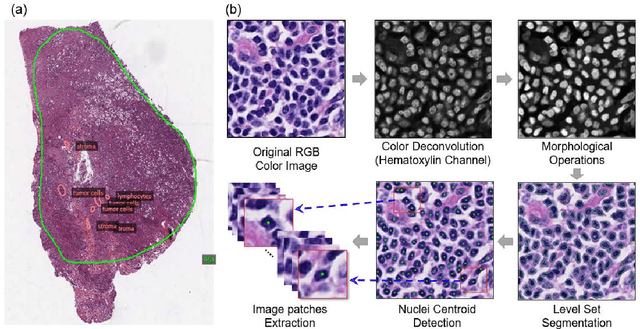
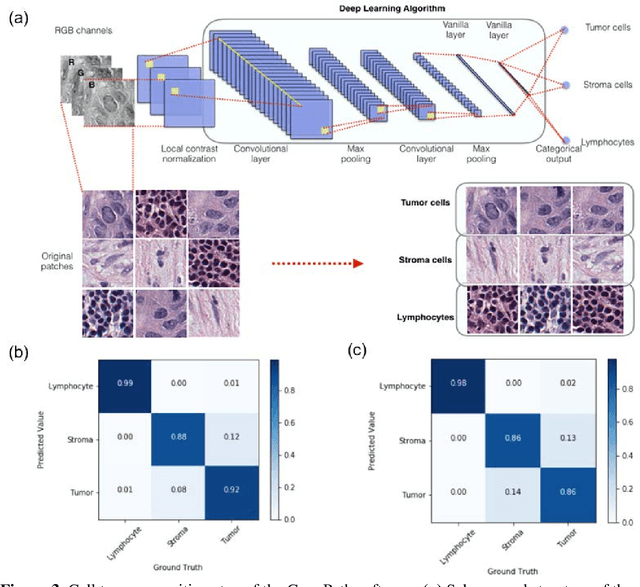
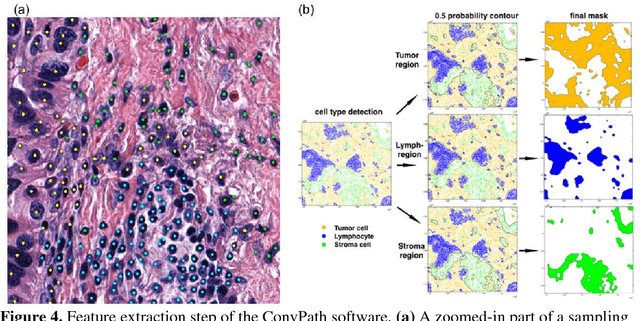
The spatial distributions of different types of cells could reveal a cancer cell growth pattern, its relationships with the tumor microenvironment and the immune response of the body, all of which represent key hallmarks of cancer. However, manually recognizing and localizing all the cells in pathology slides are almost impossible. In this study, we developed an automated cell type classification pipeline, ConvPath, which includes nuclei segmentation, convolutional neural network-based tumor, stromal and lymphocytes classification, and extraction of tumor microenvironment related features for lung cancer pathology images. The overall classification accuracy is 92.9% and 90.1% in training and independent testing datasets, respectively. By identifying cells and classifying cell types, this pipeline can convert a pathology image into a spatial map of tumor, stromal and lymphocyte cells. From this spatial map, we can extracted features that characterize the tumor micro-environment. Based on these features, we developed an image feature-based prognostic model and validated the model in two independent cohorts. The predicted risk group serves as an independent prognostic factor, after adjusting for clinical variables that include age, gender, smoking status, and stage.