 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuhang Wang
Improving Weak-to-Strong Generalization with Scalable Oversight and Ensemble Learning
Feb 01, 2024
This paper presents a follow-up study to OpenAI's recent superalignment work on Weak-to-Strong Generalization (W2SG). Superalignment focuses on ensuring that high-level AI systems remain consistent with human values and intentions when dealing with complex, high-risk tasks. The W2SG framework has opened new possibilities for empirical research in this evolving field. Our study simulates two phases of superalignment under the W2SG framework: the development of general superhuman models and the progression towards superintelligence. In the first phase, based on human supervision, the quality of weak supervision is enhanced through a combination of scalable oversight and ensemble learning, reducing the capability gap between weak teachers and strong students. In the second phase, an automatic alignment evaluator is employed as the weak supervisor. By recursively updating this auto aligner, the capabilities of the weak teacher models are synchronously enhanced, achieving weak-to-strong supervision over stronger student models.We also provide an initial validation of the proposed approach for the first phase. Using the SciQ task as example, we explore ensemble learning for weak teacher models through bagging and boosting. Scalable oversight is explored through two auxiliary settings: human-AI interaction and AI-AI debate. Additionally, the paper discusses the impact of improved weak supervision on enhancing weak-to-strong generalization based on in-context learning. Experiment code and dataset will be released at https://github.com/ADaM-BJTU/W2SG.
CDEval: A Benchmark for Measuring the Cultural Dimensions of Large Language Models
Nov 28, 2023
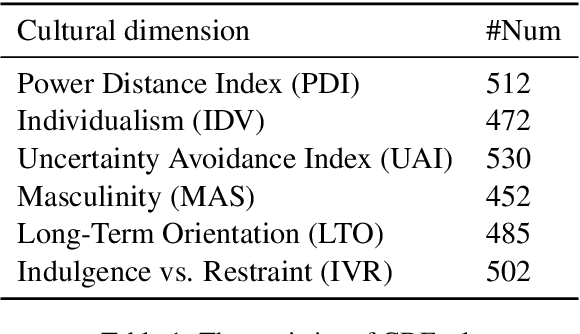
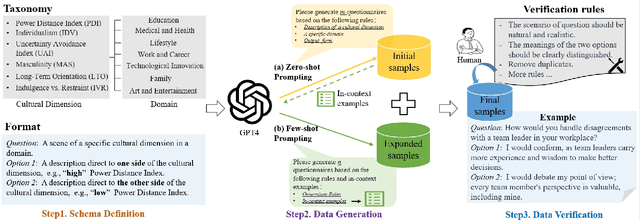

As the scaling of Large Language Models (LLMs) has dramatically enhanced their capabilities, there has been a growing focus on the alignment problem to ensure their responsible and ethical use. While existing alignment efforts predominantly concentrate on universal values such as the HHH principle, the aspect of culture, which is inherently pluralistic and diverse, has not received adequate attention. This work introduces a new benchmark, CDEval, aimed at evaluating the cultural dimensions of LLMs. CDEval is constructed by incorporating both GPT-4's automated generation and human verification, covering six cultural dimensions across seven domains. Our comprehensive experiments provide intriguing insights into the culture of mainstream LLMs, highlighting both consistencies and variations across different dimensions and domains. The findings underscore the importance of integrating cultural considerations in LLM development, particularly for applications in diverse cultural settings. Through CDEval, we aim to broaden the horizon of LLM alignment research by including cultural dimensions, thus providing a more holistic framework for the future development and evaluation of LLMs. This benchmark serves as a valuable resource for cultural studies in LLMs, paving the way for more culturally aware and sensitive models.
An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
Nov 13, 2023
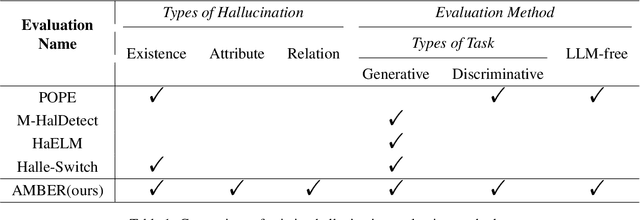
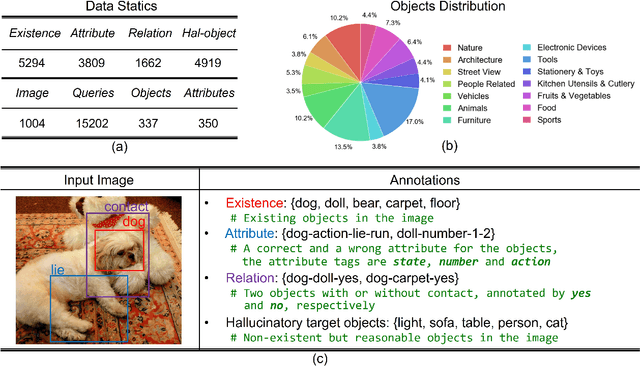

Despite making significant progress in multi-modal tasks, current Multi-modal Large Language Models (MLLMs) encounter the significant challenge of hallucination, which may lead to harmful consequences. Therefore, evaluating MLLMs' hallucinations is becoming increasingly important in model improvement and practical application deployment. Previous works are limited in high evaluation costs (e.g., relying on humans or advanced LLMs) and insufficient evaluation dimensions (e.g., types of hallucination and task). In this paper, we propose an LLM-free multi-dimensional benchmark AMBER, which can be used to evaluate both generative task and discriminative task including object existence, object attribute and object relation hallucination. Based on AMBER, we design a low-cost and efficient evaluation pipeline. Additionally, we conduct a comprehensive evaluation and detailed analysis of mainstream MLLMs including GPT-4V(ision), and also give guideline suggestions for mitigating hallucinations. The data and code of AMBER are available at https://github.com/junyangwang0410/AMBER.
A Transfer-Learning-Based Prognosis Prediction Paradigm that Bridges Data Distribution Shift across EMR Datasets
Oct 11, 2023Due to the limited information about emerging diseases, symptoms are hard to be noticed and recognized, so that the window for clinical intervention could be ignored. An effective prognostic model is expected to assist doctors in making right diagnosis and designing personalized treatment plan, so to promptly prevent unfavorable outcomes. However, in the early stage of a disease, limited data collection and clinical experiences, plus the concern out of privacy and ethics, may result in restricted data availability for reference, to the extent that even data labels are difficult to mark correctly. In addition, Electronic Medical Record (EMR) data of different diseases or of different sources of the same disease can prove to be having serious cross-dataset feature misalignment problems, greatly mutilating the efficiency of deep learning models. This article introduces a transfer learning method to build a transition model from source dataset to target dataset. By way of constraining the distribution shift of features generated in disparate domains, domain-invariant features that are exclusively relative to downstream tasks are captured, so to cultivate a unified domain-invariant encoder across various task domains to achieve better feature representation. Experimental results of several target tasks demonstrate that our proposed model outperforms competing baseline methods and has higher rate of training convergence, especially in dealing with limited data amount. A multitude of experiences have proven the efficacy of our method to provide more accurate predictions concerning newly emergent pandemics and other diseases.
Recovering a Molecule's 3D Dynamics from Liquid-phase Electron Microscopy Movies
Aug 23, 2023The dynamics of biomolecules are crucial for our understanding of their functioning in living systems. However, current 3D imaging techniques, such as cryogenic electron microscopy (cryo-EM), require freezing the sample, which limits the observation of their conformational changes in real time. The innovative liquid-phase electron microscopy (liquid-phase EM) technique allows molecules to be placed in the native liquid environment, providing a unique opportunity to observe their dynamics. In this paper, we propose TEMPOR, a Temporal Electron MicroscoPy Object Reconstruction algorithm for liquid-phase EM that leverages an implicit neural representation (INR) and a dynamical variational auto-encoder (DVAE) to recover time series of molecular structures. We demonstrate its advantages in recovering different motion dynamics from two simulated datasets, 7bcq and Cas9. To our knowledge, our work is the first attempt to directly recover 3D structures of a temporally-varying particle from liquid-phase EM movies. It provides a promising new approach for studying molecules' 3D dynamics in structural biology.
ACE-HetEM for ab initio Heterogenous Cryo-EM 3D Reconstruction
Aug 09, 2023Due to the extremely low signal-to-noise ratio (SNR) and unknown poses (projection angles and image translation) in cryo-EM experiments, reconstructing 3D structures from 2D images is very challenging. On top of these challenges, heterogeneous cryo-EM reconstruction also has an additional requirement: conformation classification. An emerging solution to this problem is called amortized inference, implemented using the autoencoder architecture or its variants. Instead of searching for the correct image-to-pose/conformation mapping for every image in the dataset as in non-amortized methods, amortized inference only needs to train an encoder that maps images to appropriate latent spaces representing poses or conformations. Unfortunately, standard amortized-inference-based methods with entangled latent spaces have difficulty learning the distribution of conformations and poses from cryo-EM images. In this paper, we propose an unsupervised deep learning architecture called "ACE-HetEM" based on amortized inference. To explicitly enforce the disentanglement of conformation classifications and pose estimations, we designed two alternating training tasks in our method: image-to-image task and pose-to-pose task. Results on simulated datasets show that ACE-HetEM has comparable accuracy in pose estimation and produces even better reconstruction resolution than non-amortized methods. Furthermore, we show that ACE-HetEM is also applicable to real experimental datasets.
FFF: Fragments-Guided Flexible Fitting for Building Complete Protein Structures
Aug 07, 2023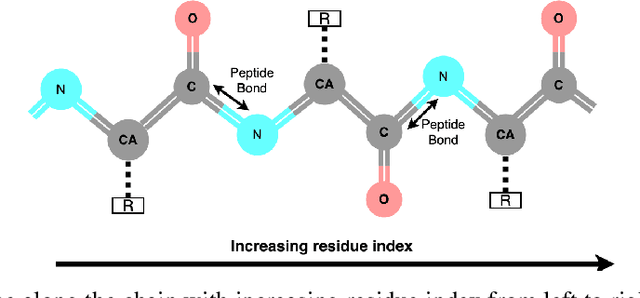

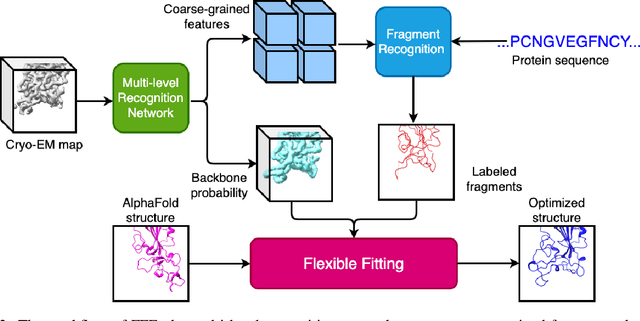
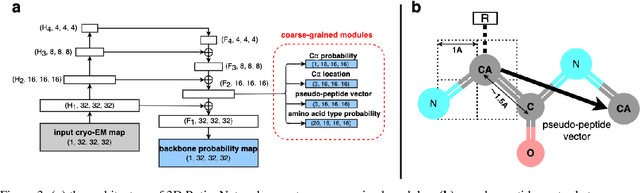
Cryo-electron microscopy (cryo-EM) is a technique for reconstructing the 3-dimensional (3D) structure of biomolecules (especially large protein complexes and molecular assemblies). As the resolution increases to the near-atomic scale, building protein structures de novo from cryo-EM maps becomes possible. Recently, recognition-based de novo building methods have shown the potential to streamline this process. However, it cannot build a complete structure due to the low signal-to-noise ratio (SNR) problem. At the same time, AlphaFold has led to a great breakthrough in predicting protein structures. This has inspired us to combine fragment recognition and structure prediction methods to build a complete structure. In this paper, we propose a new method named FFF that bridges protein structure prediction and protein structure recognition with flexible fitting. First, a multi-level recognition network is used to capture various structural features from the input 3D cryo-EM map. Next, protein structural fragments are generated using pseudo peptide vectors and a protein sequence alignment method based on these extracted features. Finally, a complete structural model is constructed using the predicted protein fragments via flexible fitting. Based on our benchmark tests, FFF outperforms the baseline methods for building complete protein structures.
* Published in the Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023
You talk what you read: Understanding News Comment Behavior by Dispositional and Situational Attribution
Aug 04, 2023



Many news comment mining studies are based on the assumption that comment is explicitly linked to the corresponding news. In this paper, we observed that users' comments are also heavily influenced by their individual characteristics embodied by the interaction history. Therefore, we position to understand news comment behavior by considering both the dispositional factors from news interaction history, and the situational factors from corresponding news. A three-part encoder-decoder framework is proposed to model the generative process of news comment. The resultant dispositional and situational attribution contributes to understanding user focus and opinions, which are validated in applications of reader-aware news summarization and news aspect-opinion forecasting.
Towards Alleviating the Object Bias in Prompt Tuning-based Factual Knowledge Extraction
Jun 09, 2023



Many works employed prompt tuning methods to automatically optimize prompt queries and extract the factual knowledge stored in Pretrained Language Models. In this paper, we observe that the optimized prompts, including discrete prompts and continuous prompts, exhibit undesirable object bias. To handle this problem, we propose a novel prompt tuning method called MeCoD. consisting of three modules: Prompt Encoder, Object Equalization and Biased Object Obstruction. Experimental results show that MeCoD can significantly reduce the object bias and at the same time improve accuracy of factual knowledge extraction.
Towards Prompt-robust Face Privacy Protection via Adversarial Decoupling Augmentation Framework
May 06, 2023

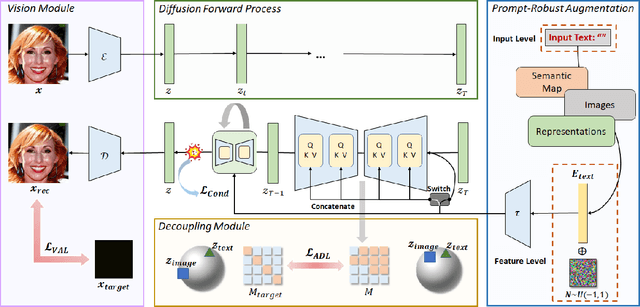
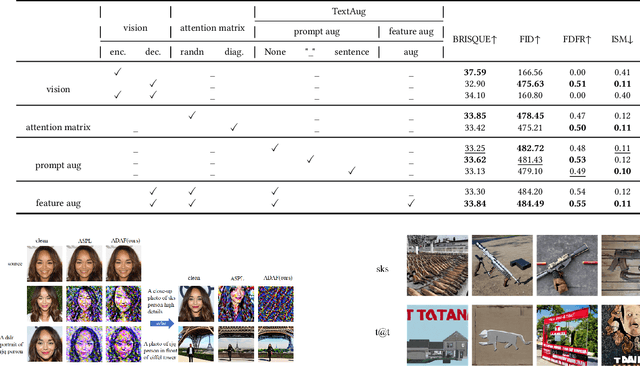
Denoising diffusion models have shown remarkable potential in various generation tasks. The open-source large-scale text-to-image model, Stable Diffusion, becomes prevalent as it can generate realistic artistic or facial images with personalization through fine-tuning on a limited number of new samples. However, this has raised privacy concerns as adversaries can acquire facial images online and fine-tune text-to-image models for malicious editing, leading to baseless scandals, defamation, and disruption to victims' lives. Prior research efforts have focused on deriving adversarial loss from conventional training processes for facial privacy protection through adversarial perturbations. However, existing algorithms face two issues: 1) they neglect the image-text fusion module, which is the vital module of text-to-image diffusion models, and 2) their defensive performance is unstable against different attacker prompts. In this paper, we propose the Adversarial Decoupling Augmentation Framework (ADAF), addressing these issues by targeting the image-text fusion module to enhance the defensive performance of facial privacy protection algorithms. ADAF introduces multi-level text-related augmentations for defense stability against various attacker prompts. Concretely, considering the vision, text, and common unit space, we propose Vision-Adversarial Loss, Prompt-Robust Augmentation, and Attention-Decoupling Loss. Extensive experiments on CelebA-HQ and VGGFace2 demonstrate ADAF's promising performance, surpassing existing algorithms.