 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYun Yang
A Practical Beamforming Design for Active RIS-assisted MU-MISO Systems
Jan 08, 2024
Reconfigurable Intelligent Surfaces (RIS) have been proposed as a revolutionary technology with the potential to address several critical requirements of 6G communication systems. Despite its powerful ability for radio environment reconfiguration, the ``double fading'' effect constricts the practical system performance enhancements due to the significant path loss. A new active RIS architecture has been recently proposed to overcome this challenge. However, existing active RIS studies rely on an ideal amplification model without considering the practical hardware limitation of amplifiers, which may cause performance degradation using such inaccurate active RIS modeling. Motivated by this fact, in this paper we first investigate the amplification principle of typical active RIS and propose a more accurate amplification model based on amplifier hardware characteristics. Then, based on the new amplification model, we propose a novel joint transmit beamforming and RIS reflection beamforming design considering the incident signal power on practical active RIS for multiuser multi-input single-output (MU-MISO) communication system. Fractional programming (FP), majorization minimization (MM) and block coordinate descent (BCD) methods are used to solve for the complex problem. Simulation results indicate the importance of the consideration of practical amplifier hardware characteristics in the joint beamforming designs and demonstrate the effectiveness of the proposed algorithm compared to other benchmarks.
Bayesian Model Selection via Mean-Field Variational Approximation
Dec 17, 2023This article considers Bayesian model selection via mean-field (MF) variational approximation. Towards this goal, we study the non-asymptotic properties of MF inference under the Bayesian framework that allows latent variables and model mis-specification. Concretely, we show a Bernstein von-Mises (BvM) theorem for the variational distribution from MF under possible model mis-specification, which implies the distributional convergence of MF variational approximation to a normal distribution centering at the maximal likelihood estimator (within the specified model). Motivated by the BvM theorem, we propose a model selection criterion using the evidence lower bound (ELBO), and demonstrate that the model selected by ELBO tends to asymptotically agree with the one selected by the commonly used Bayesian information criterion (BIC) as sample size tends to infinity. Comparing to BIC, ELBO tends to incur smaller approximation error to the log-marginal likelihood (a.k.a. model evidence) due to a better dimension dependence and full incorporation of the prior information. Moreover, we show the geometric convergence of the coordinate ascent variational inference (CAVI) algorithm under the parametric model framework, which provides a practical guidance on how many iterations one typically needs to run when approximating the ELBO. These findings demonstrate that variational inference is capable of providing a computationally efficient alternative to conventional approaches in tasks beyond obtaining point estimates, which is also empirically demonstrated by our extensive numerical experiments.
A Gromov--Wasserstein Geometric View of Spectrum-Preserving Graph Coarsening
Jun 15, 2023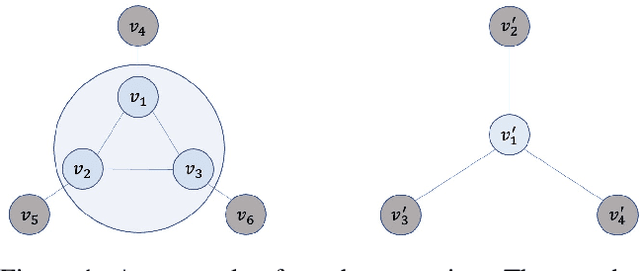
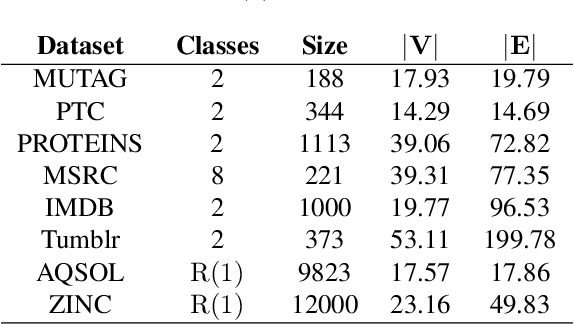
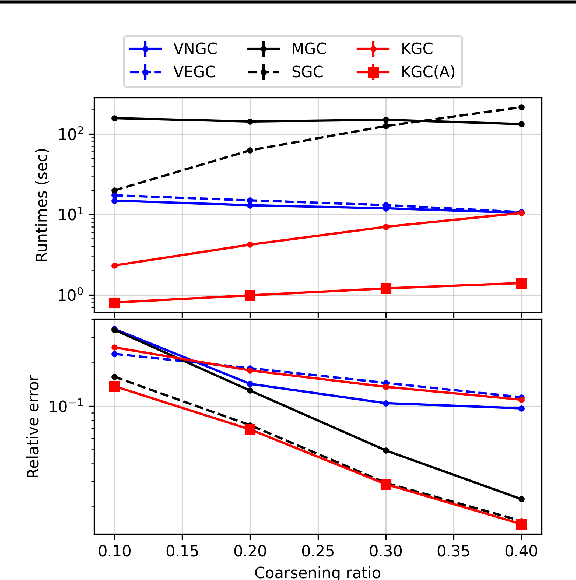
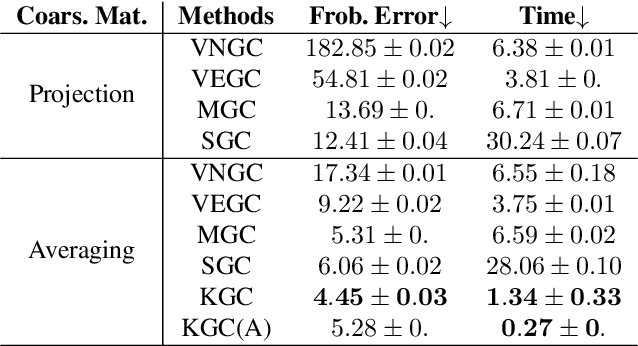
Graph coarsening is a technique for solving large-scale graph problems by working on a smaller version of the original graph, and possibly interpolating the results back to the original graph. It has a long history in scientific computing and has recently gained popularity in machine learning, particularly in methods that preserve the graph spectrum. This work studies graph coarsening from a different perspective, developing a theory for preserving graph distances and proposing a method to achieve this. The geometric approach is useful when working with a collection of graphs, such as in graph classification and regression. In this study, we consider a graph as an element on a metric space equipped with the Gromov--Wasserstein (GW) distance, and bound the difference between the distance of two graphs and their coarsened versions. Minimizing this difference can be done using the popular weighted kernel $K$-means method, which improves existing spectrum-preserving methods with the proper choice of the kernel. The study includes a set of experiments to support the theory and method, including approximating the GW distance, preserving the graph spectrum, classifying graphs using spectral information, and performing regression using graph convolutional networks. Code is available at https://github.com/ychen-stat-ml/GW-Graph-Coarsening .
On the Convergence of Coordinate Ascent Variational Inference
Jun 01, 2023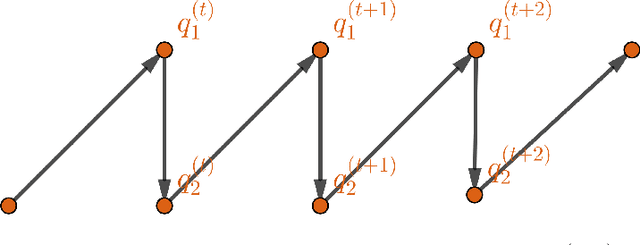
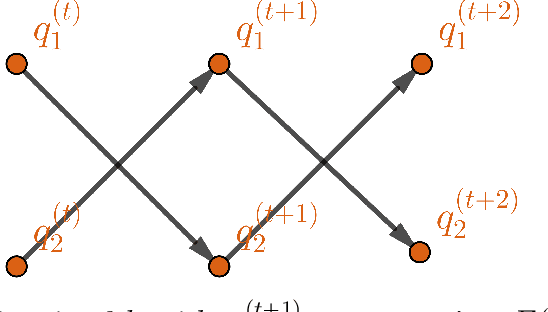
As a computational alternative to Markov chain Monte Carlo approaches, variational inference (VI) is becoming more and more popular for approximating intractable posterior distributions in large-scale Bayesian models due to its comparable efficacy and superior efficiency. Several recent works provide theoretical justifications of VI by proving its statistical optimality for parameter estimation under various settings; meanwhile, formal analysis on the algorithmic convergence aspects of VI is still largely lacking. In this paper, we consider the common coordinate ascent variational inference (CAVI) algorithm for implementing the mean-field (MF) VI towards optimizing a Kullback--Leibler divergence objective functional over the space of all factorized distributions. Focusing on the two-block case, we analyze the convergence of CAVI by leveraging the extensive toolbox from functional analysis and optimization. We provide general conditions for certifying global or local exponential convergence of CAVI. Specifically, a new notion of generalized correlation for characterizing the interaction between the constituting blocks in influencing the VI objective functional is introduced, which according to the theory, quantifies the algorithmic contraction rate of two-block CAVI. As illustrations, we apply the developed theory to a number of examples, and derive explicit problem-dependent upper bounds on the algorithmic contraction rate.
CTSN: Predicting Cloth Deformation for Skeleton-based Characters with a Two-stream Skinning Network
May 30, 2023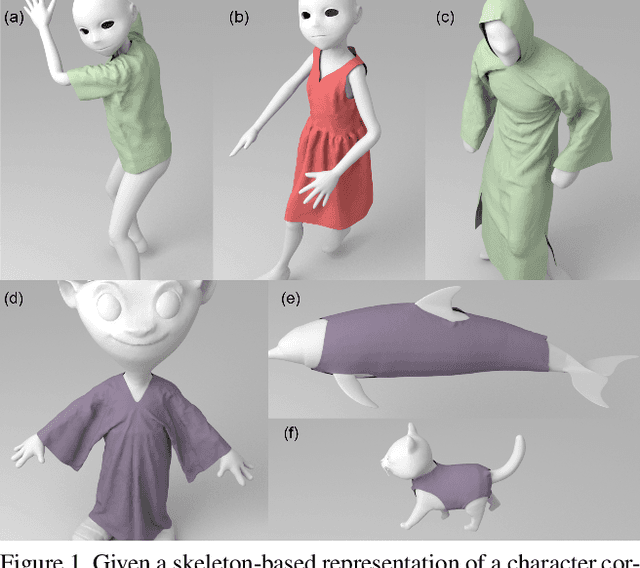

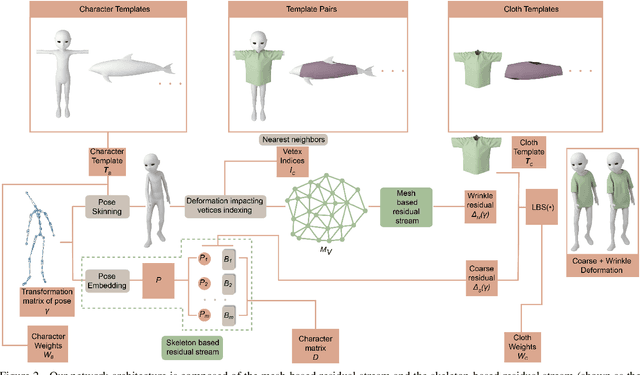
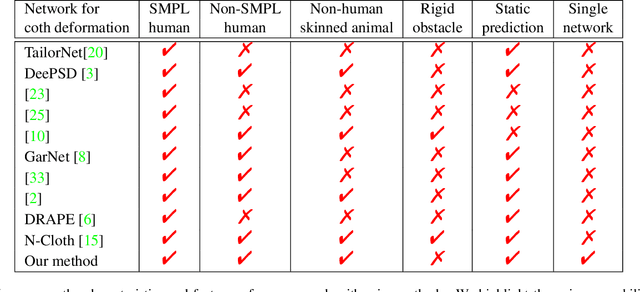
We present a novel learning method to predict the cloth deformation for skeleton-based characters with a two-stream network. The characters processed in our approach are not limited to humans, and can be other skeletal-based representations of non-human targets such as fish or pets. We use a novel network architecture which consists of skeleton-based and mesh-based residual networks to learn the coarse and wrinkle features as the overall residual from the template cloth mesh. Our network is used to predict the deformation for loose or tight-fitting clothing or dresses. We ensure that the memory footprint of our network is low, and thereby result in reduced storage and computational requirements. In practice, our prediction for a single cloth mesh for the skeleton-based character takes about 7 milliseconds on an NVIDIA GeForce RTX 3090 GPU. Compared with prior methods, our network can generate fine deformation results with details and wrinkles.
Statistically Optimal K-means Clustering via Nonnegative Low-rank Semidefinite Programming
May 29, 2023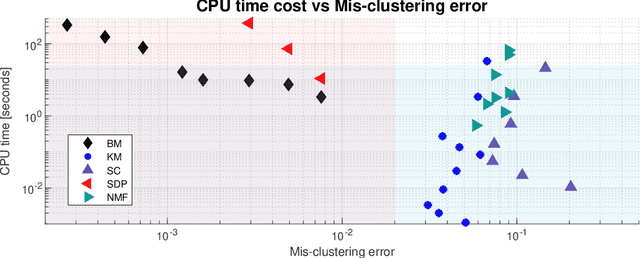
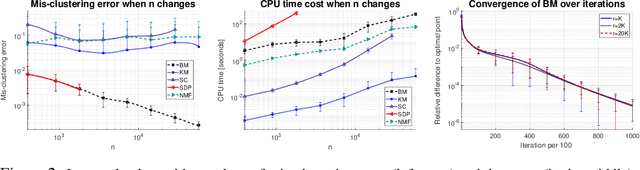
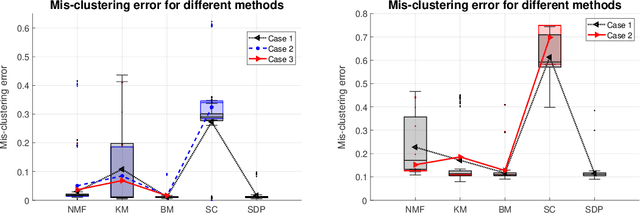
$K$-means clustering is a widely used machine learning method for identifying patterns in large datasets. Semidefinite programming (SDP) relaxations have recently been proposed for solving the $K$-means optimization problem that enjoy strong statistical optimality guarantees, but the prohibitive cost of implementing an SDP solver renders these guarantees inaccessible to practical datasets. By contrast, nonnegative matrix factorization (NMF) is a simple clustering algorithm that is widely used by machine learning practitioners, but without a solid statistical underpinning nor rigorous guarantees. In this paper, we describe an NMF-like algorithm that works by solving a nonnegative low-rank restriction of the SDP relaxed $K$-means formulation using a nonconvex Burer--Monteiro factorization approach. The resulting algorithm is just as simple and scalable as state-of-the-art NMF algorithms, while also enjoying the same strong statistical optimality guarantees as the SDP. In our experiments, we observe that our algorithm achieves substantially smaller mis-clustering errors compared to the existing state-of-the-art.
Global and Local Mixture Consistency Cumulative Learning for Long-tailed Visual Recognitions
May 15, 2023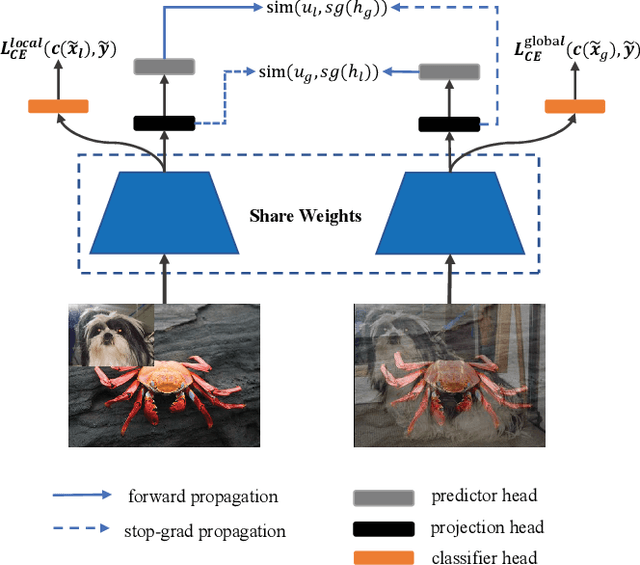
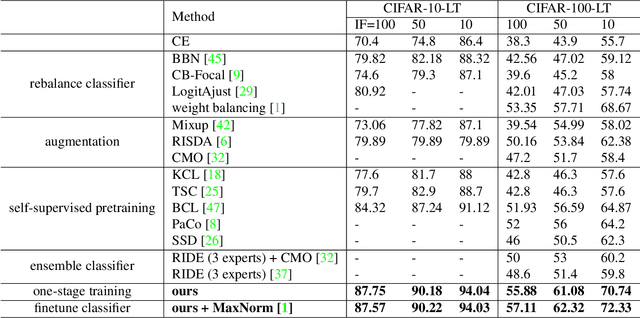
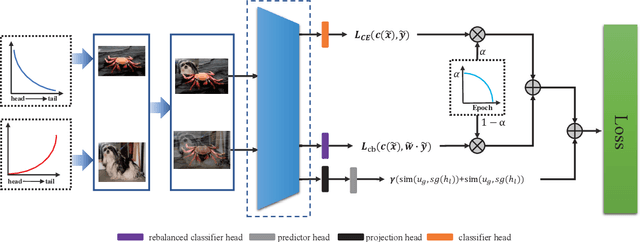
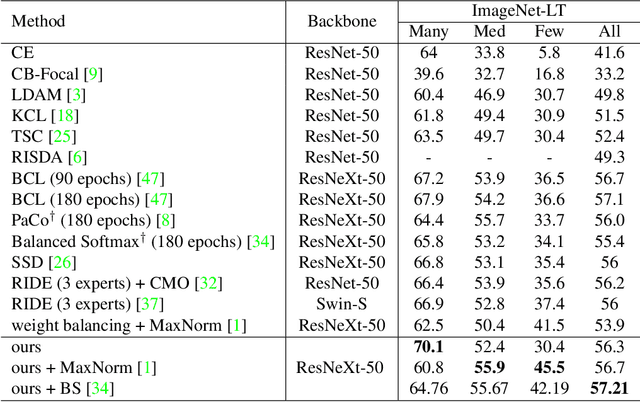
In this paper, our goal is to design a simple learning paradigm for long-tail visual recognition, which not only improves the robustness of the feature extractor but also alleviates the bias of the classifier towards head classes while reducing the training skills and overhead. We propose an efficient one-stage training strategy for long-tailed visual recognition called Global and Local Mixture Consistency cumulative learning (GLMC). Our core ideas are twofold: (1) a global and local mixture consistency loss improves the robustness of the feature extractor. Specifically, we generate two augmented batches by the global MixUp and local CutMix from the same batch data, respectively, and then use cosine similarity to minimize the difference. (2) A cumulative head tail soft label reweighted loss mitigates the head class bias problem. We use empirical class frequencies to reweight the mixed label of the head-tail class for long-tailed data and then balance the conventional loss and the rebalanced loss with a coefficient accumulated by epochs. Our approach achieves state-of-the-art accuracy on CIFAR10-LT, CIFAR100-LT, and ImageNet-LT datasets. Additional experiments on balanced ImageNet and CIFAR demonstrate that GLMC can significantly improve the generalization of backbones. Code is made publicly available at https://github.com/ynu-yangpeng/GLMC.
TFormer: A Transmission-Friendly ViT Model for IoT Devices
Feb 15, 2023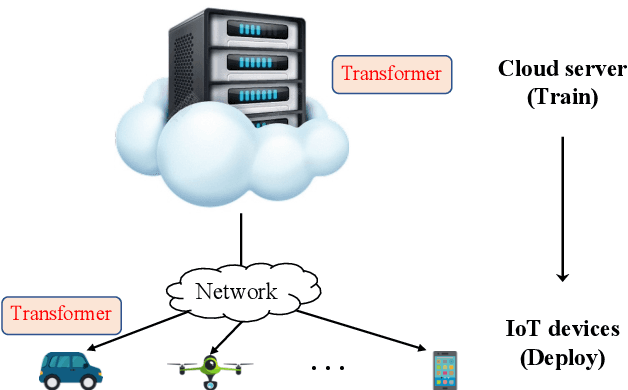
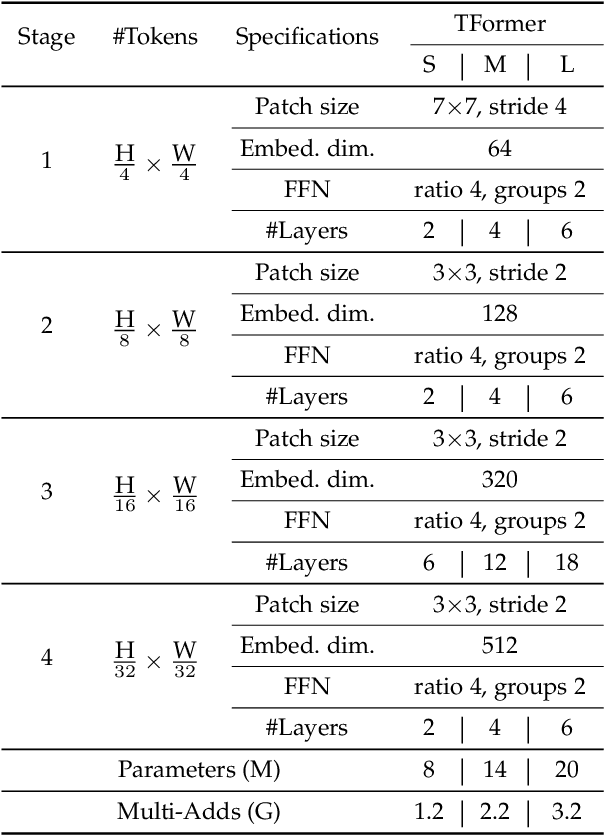
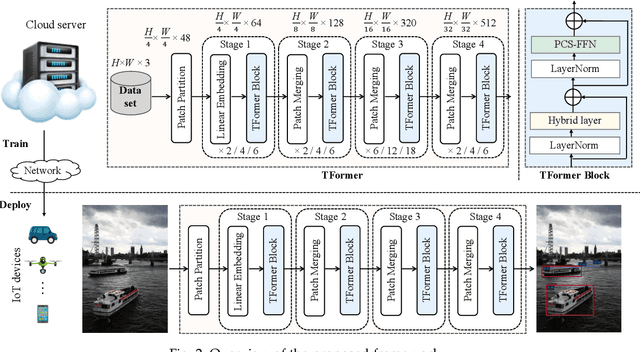
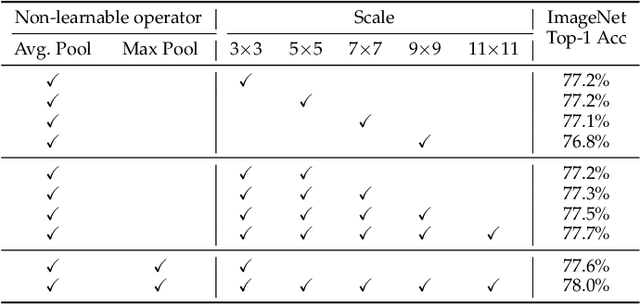
Deploying high-performance vision transformer (ViT) models on ubiquitous Internet of Things (IoT) devices to provide high-quality vision services will revolutionize the way we live, work, and interact with the world. Due to the contradiction between the limited resources of IoT devices and resource-intensive ViT models, the use of cloud servers to assist ViT model training has become mainstream. However, due to the larger number of parameters and floating-point operations (FLOPs) of the existing ViT models, the model parameters transmitted by cloud servers are large and difficult to run on resource-constrained IoT devices. To this end, this paper proposes a transmission-friendly ViT model, TFormer, for deployment on resource-constrained IoT devices with the assistance of a cloud server. The high performance and small number of model parameters and FLOPs of TFormer are attributed to the proposed hybrid layer and the proposed partially connected feed-forward network (PCS-FFN). The hybrid layer consists of nonlearnable modules and a pointwise convolution, which can obtain multitype and multiscale features with only a few parameters and FLOPs to improve the TFormer performance. The PCS-FFN adopts group convolution to reduce the number of parameters. The key idea of this paper is to propose TFormer with few model parameters and FLOPs to facilitate applications running on resource-constrained IoT devices to benefit from the high performance of the ViT models. Experimental results on the ImageNet-1K, MS COCO, and ADE20K datasets for image classification, object detection, and semantic segmentation tasks demonstrate that the proposed model outperforms other state-of-the-art models. Specifically, TFormer-S achieves 5% higher accuracy on ImageNet-1K than ResNet18 with 1.4$\times$ fewer parameters and FLOPs.
Likelihood adjusted semidefinite programs for clustering heterogeneous data
Sep 29, 2022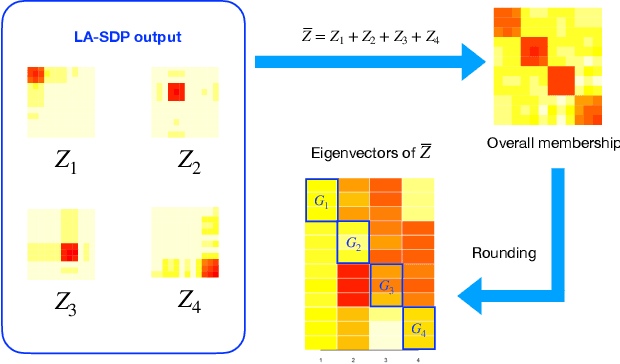
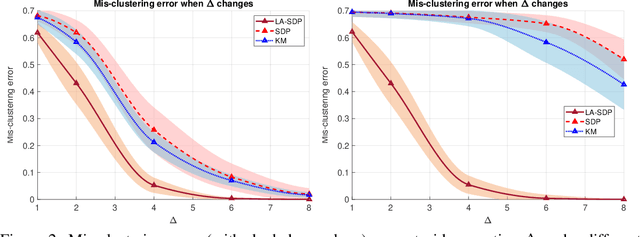
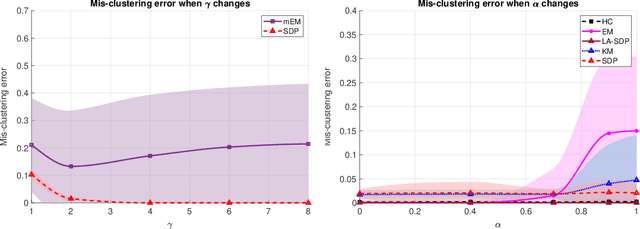
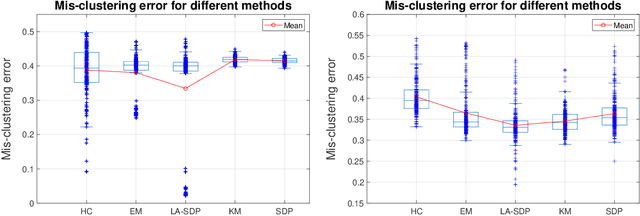
Clustering is a widely deployed unsupervised learning tool. Model-based clustering is a flexible framework to tackle data heterogeneity when the clusters have different shapes. Likelihood-based inference for mixture distributions often involves non-convex and high-dimensional objective functions, imposing difficult computational and statistical challenges. The classic expectation-maximization (EM) algorithm is a computationally thrifty iterative method that maximizes a surrogate function minorizing the log-likelihood of observed data in each iteration, which however suffers from bad local maxima even in the special case of the standard Gaussian mixture model with common isotropic covariance matrices. On the other hand, recent studies reveal that the unique global solution of a semidefinite programming (SDP) relaxed $K$-means achieves the information-theoretically sharp threshold for perfectly recovering the cluster labels under the standard Gaussian mixture model. In this paper, we extend the SDP approach to a general setting by integrating cluster labels as model parameters and propose an iterative likelihood adjusted SDP (iLA-SDP) method that directly maximizes the \emph{exact} observed likelihood in the presence of data heterogeneity. By lifting the cluster assignment to group-specific membership matrices, iLA-SDP avoids centroids estimation -- a key feature that allows exact recovery under well-separateness of centroids without being trapped by their adversarial configurations. Thus iLA-SDP is less sensitive than EM to initialization and more stable on high-dimensional data. Our numeric experiments demonstrate that iLA-SDP can achieve lower mis-clustering errors over several widely used clustering methods including $K$-means, SDP and EM algorithms.
Wasserstein $K$-means for clustering probability distributions
Sep 14, 2022

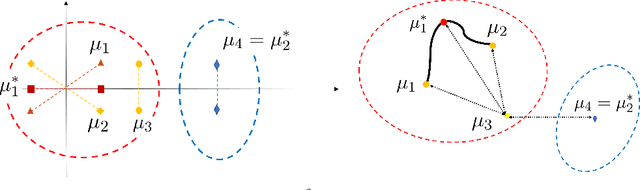

Clustering is an important exploratory data analysis technique to group objects based on their similarity. The widely used $K$-means clustering method relies on some notion of distance to partition data into a fewer number of groups. In the Euclidean space, centroid-based and distance-based formulations of the $K$-means are equivalent. In modern machine learning applications, data often arise as probability distributions and a natural generalization to handle measure-valued data is to use the optimal transport metric. Due to non-negative Alexandrov curvature of the Wasserstein space, barycenters suffer from regularity and non-robustness issues. The peculiar behaviors of Wasserstein barycenters may make the centroid-based formulation fail to represent the within-cluster data points, while the more direct distance-based $K$-means approach and its semidefinite program (SDP) relaxation are capable of recovering the true cluster labels. In the special case of clustering Gaussian distributions, we show that the SDP relaxed Wasserstein $K$-means can achieve exact recovery given the clusters are well-separated under the $2$-Wasserstein metric. Our simulation and real data examples also demonstrate that distance-based $K$-means can achieve better classification performance over the standard centroid-based $K$-means for clustering probability distributions and images.