 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhichao Lu
AnomalyXFusion: Multi-modal Anomaly Synthesis with Diffusion
May 02, 2024
Anomaly synthesis is one of the effective methods to augment abnormal samples for training. However, current anomaly synthesis methods predominantly rely on texture information as input, which limits the fidelity of synthesized abnormal samples. Because texture information is insufficient to correctly depict the pattern of anomalies, especially for logical anomalies. To surmount this obstacle, we present the AnomalyXFusion framework, designed to harness multi-modality information to enhance the quality of synthesized abnormal samples. The AnomalyXFusion framework comprises two distinct yet synergistic modules: the Multi-modal In-Fusion (MIF) module and the Dynamic Dif-Fusion (DDF) module. The MIF module refines modality alignment by aggregating and integrating various modality features into a unified embedding space, termed X-embedding, which includes image, text, and mask features. Concurrently, the DDF module facilitates controlled generation through an adaptive adjustment of X-embedding conditioned on the diffusion steps. In addition, to reveal the multi-modality representational power of AnomalyXFusion, we propose a new dataset, called MVTec Caption. More precisely, MVTec Caption extends 2.2k accurate image-mask-text annotations for the MVTec AD and LOCO datasets. Comprehensive evaluations demonstrate the effectiveness of AnomalyXFusion, especially regarding the fidelity and diversity for logical anomalies. Project page: http:github.com/hujiecpp/MVTec-Caption
ShadowMaskFormer: Mask Augmented Patch Embeddings for Shadow Removal
Apr 30, 2024Transformer recently emerged as the de facto model for computer vision tasks and has also been successfully applied to shadow removal. However, these existing methods heavily rely on intricate modifications to the attention mechanisms within the transformer blocks while using a generic patch embedding. As a result, it often leads to complex architectural designs requiring additional computation resources. In this work, we aim to explore the efficacy of incorporating shadow information within the early processing stage. Accordingly, we propose a transformer-based framework with a novel patch embedding that is tailored for shadow removal, dubbed ShadowMaskFormer. Specifically, we present a simple and effective mask-augmented patch embedding to integrate shadow information and promote the model's emphasis on acquiring knowledge for shadow regions. Extensive experiments conducted on the ISTD, ISTD+, and SRD benchmark datasets demonstrate the efficacy of our method against state-of-the-art approaches while using fewer model parameters.
A Multi-objective Optimization Benchmark Test Suite for Real-time Semantic Segmentation
Apr 29, 2024As one of the emerging challenges in Automated Machine Learning, the Hardware-aware Neural Architecture Search (HW-NAS) tasks can be treated as black-box multi-objective optimization problems (MOPs). An important application of HW-NAS is real-time semantic segmentation, which plays a pivotal role in autonomous driving scenarios. The HW-NAS for real-time semantic segmentation inherently needs to balance multiple optimization objectives, including model accuracy, inference speed, and hardware-specific considerations. Despite its importance, benchmarks have yet to be developed to frame such a challenging task as multi-objective optimization. To bridge the gap, we introduce a tailored streamline to transform the task of HW-NAS for real-time semantic segmentation into standard MOPs. Building upon the streamline, we present a benchmark test suite, CitySeg/MOP, comprising fifteen MOPs derived from the Cityscapes dataset. The CitySeg/MOP test suite is integrated into the EvoXBench platform to provide seamless interfaces with various programming languages (e.g., Python and MATLAB) for instant fitness evaluations. We comprehensively assessed the CitySeg/MOP test suite on various multi-objective evolutionary algorithms, showcasing its versatility and practicality. Source codes are available at https://github.com/EMI-Group/evoxbench.
An Example of Evolutionary Computation + Large Language Model Beating Human: Design of Efficient Guided Local Search
Jan 04, 2024It is often very tedious for human experts to design efficient algorithms. Recently, we have proposed a novel Algorithm Evolution using Large Language Model (AEL) framework for automatic algorithm design. AEL combines the power of a large language model and the paradigm of evolutionary computation to design, combine, and modify algorithms automatically. In this paper, we use AEL to design the guide algorithm for guided local search (GLS) to solve the well-known traveling salesman problem (TSP). AEL automatically evolves elite GLS algorithms in two days, with minimal human effort and no model training. Experimental results on 1,000 TSP20-TSP100 instances and TSPLib instances show that AEL-designed GLS outperforms state-of-the-art human-designed GLS with the same iteration budget. It achieves a 0% gap on TSP20 and TSP50 and a 0.032% gap on TSP100 in 1,000 iterations. Our findings mark the emergence of a new era in automatic algorithm design.
Seed Feature Maps-based CNN Models for LEO Satellite Remote Sensing Services
Aug 12, 2023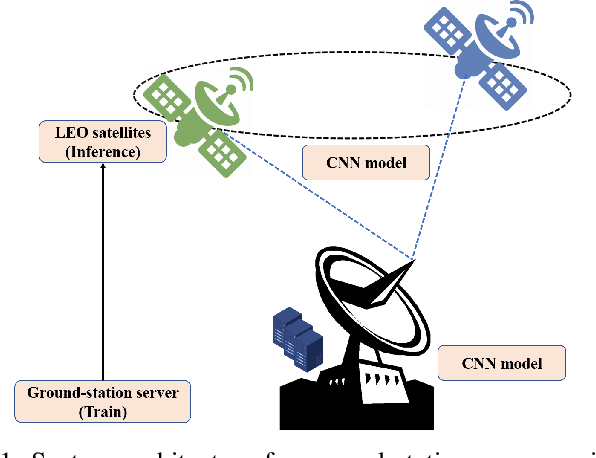
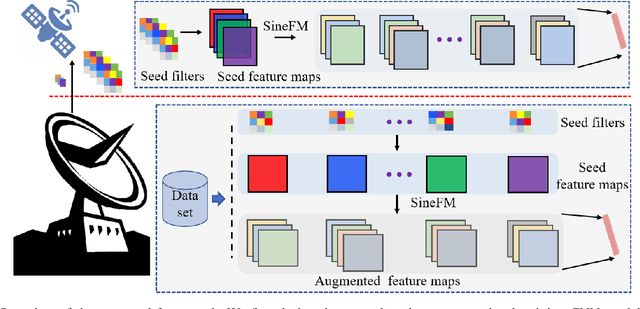
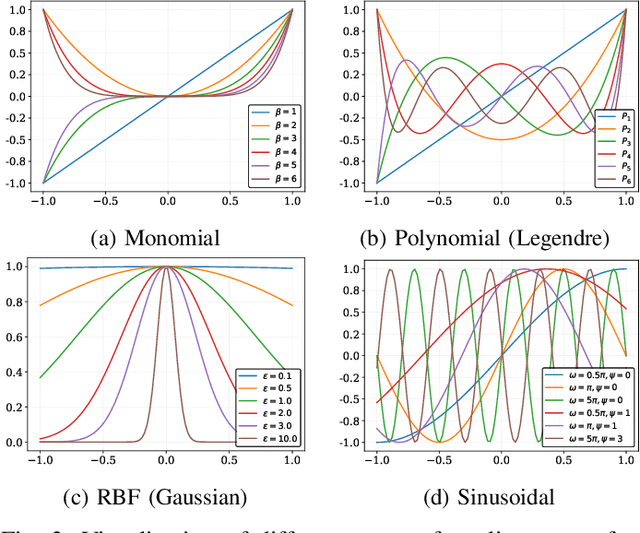
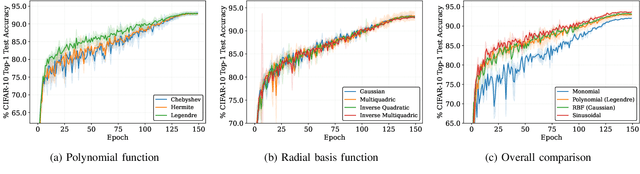
Deploying high-performance convolutional neural network (CNN) models on low-earth orbit (LEO) satellites for rapid remote sensing image processing has attracted significant interest from industry and academia. However, the limited resources available on LEO satellites contrast with the demands of resource-intensive CNN models, necessitating the adoption of ground-station server assistance for training and updating these models. Existing approaches often require large floating-point operations (FLOPs) and substantial model parameter transmissions, presenting considerable challenges. To address these issues, this paper introduces a ground-station server-assisted framework. With the proposed framework, each layer of the CNN model contains only one learnable feature map (called the seed feature map) from which other feature maps are generated based on specific rules. The hyperparameters of these rules are randomly generated instead of being trained, thus enabling the generation of multiple feature maps from the seed feature map and significantly reducing FLOPs. Furthermore, since the random hyperparameters can be saved using a few random seeds, the ground station server assistance can be facilitated in updating the CNN model deployed on the LEO satellite. Experimental results on the ISPRS Vaihingen, ISPRS Potsdam, UAVid, and LoveDA datasets for semantic segmentation services demonstrate that the proposed framework outperforms existing state-of-the-art approaches. In particular, the SineFM-based model achieves a higher mIoU than the UNetFormer on the UAVid dataset, with 3.3x fewer parameters and 2.2x fewer FLOPs.
Mitigating Task Interference in Multi-Task Learning via Explicit Task Routing with Non-Learnable Primitives
Aug 03, 2023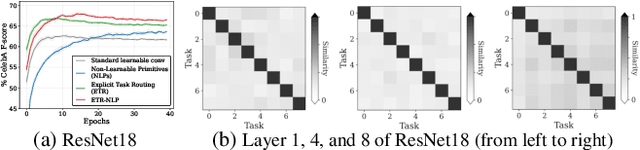
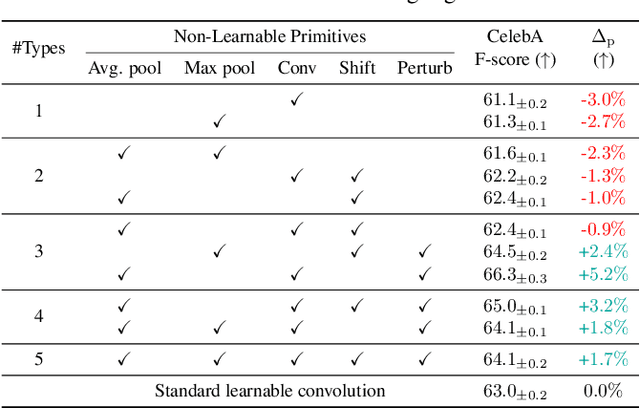
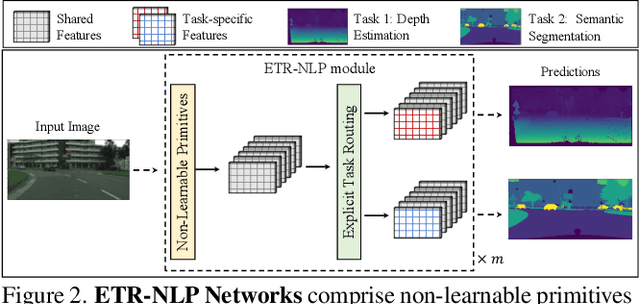
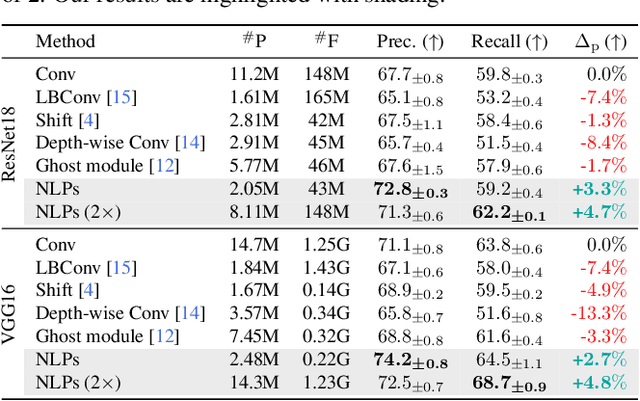
Multi-task learning (MTL) seeks to learn a single model to accomplish multiple tasks by leveraging shared information among the tasks. Existing MTL models, however, have been known to suffer from negative interference among tasks. Efforts to mitigate task interference have focused on either loss/gradient balancing or implicit parameter partitioning with partial overlaps among the tasks. In this paper, we propose ETR-NLP to mitigate task interference through a synergistic combination of non-learnable primitives (NLPs) and explicit task routing (ETR). Our key idea is to employ non-learnable primitives to extract a diverse set of task-agnostic features and recombine them into a shared branch common to all tasks and explicit task-specific branches reserved for each task. The non-learnable primitives and the explicit decoupling of learnable parameters into shared and task-specific ones afford the flexibility needed for minimizing task interference. We evaluate the efficacy of ETR-NLP networks for both image-level classification and pixel-level dense prediction MTL problems. Experimental results indicate that ETR-NLP significantly outperforms state-of-the-art baselines with fewer learnable parameters and similar FLOPs across all datasets. Code is available at this \href{https://github.com/zhichao-lu/etr-nlp-mtl}.
TFormer: A Transmission-Friendly ViT Model for IoT Devices
Feb 15, 2023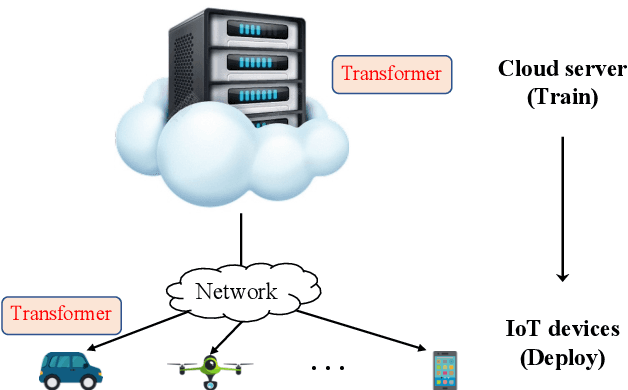
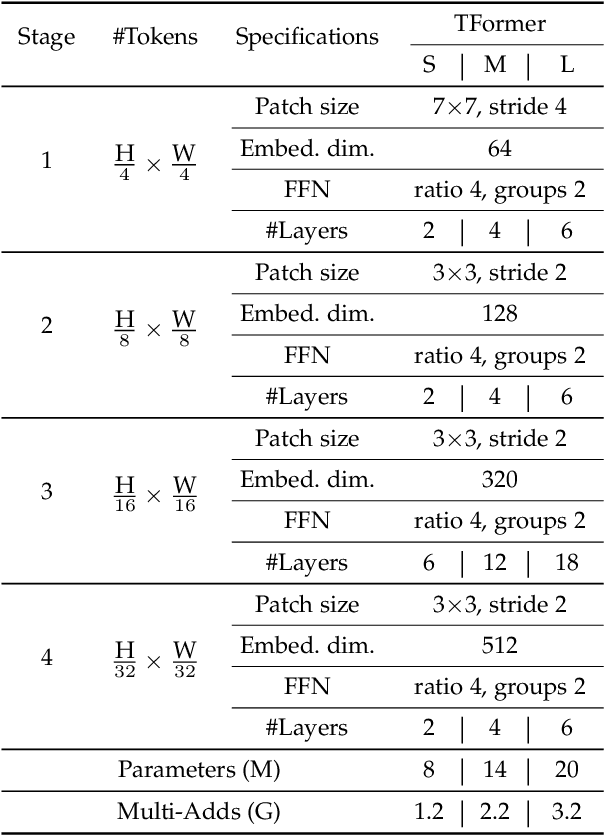
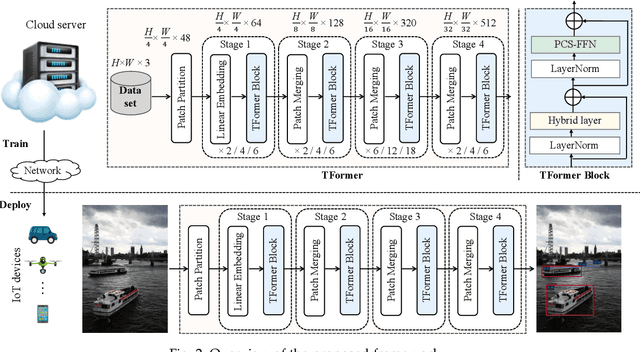
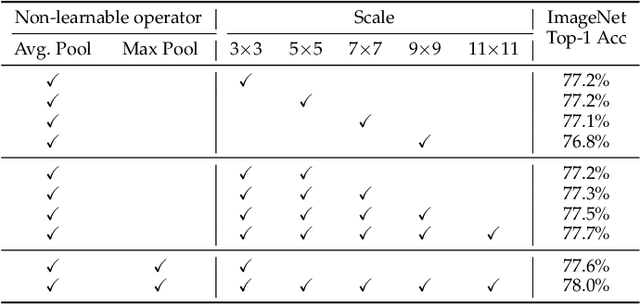
Deploying high-performance vision transformer (ViT) models on ubiquitous Internet of Things (IoT) devices to provide high-quality vision services will revolutionize the way we live, work, and interact with the world. Due to the contradiction between the limited resources of IoT devices and resource-intensive ViT models, the use of cloud servers to assist ViT model training has become mainstream. However, due to the larger number of parameters and floating-point operations (FLOPs) of the existing ViT models, the model parameters transmitted by cloud servers are large and difficult to run on resource-constrained IoT devices. To this end, this paper proposes a transmission-friendly ViT model, TFormer, for deployment on resource-constrained IoT devices with the assistance of a cloud server. The high performance and small number of model parameters and FLOPs of TFormer are attributed to the proposed hybrid layer and the proposed partially connected feed-forward network (PCS-FFN). The hybrid layer consists of nonlearnable modules and a pointwise convolution, which can obtain multitype and multiscale features with only a few parameters and FLOPs to improve the TFormer performance. The PCS-FFN adopts group convolution to reduce the number of parameters. The key idea of this paper is to propose TFormer with few model parameters and FLOPs to facilitate applications running on resource-constrained IoT devices to benefit from the high performance of the ViT models. Experimental results on the ImageNet-1K, MS COCO, and ADE20K datasets for image classification, object detection, and semantic segmentation tasks demonstrate that the proposed model outperforms other state-of-the-art models. Specifically, TFormer-S achieves 5% higher accuracy on ImageNet-1K than ResNet18 with 1.4$\times$ fewer parameters and FLOPs.
Revisiting Residual Networks for Adversarial Robustness: An Architectural Perspective
Dec 21, 2022



Efforts to improve the adversarial robustness of convolutional neural networks have primarily focused on developing more effective adversarial training methods. In contrast, little attention was devoted to analyzing the role of architectural elements (such as topology, depth, and width) on adversarial robustness. This paper seeks to bridge this gap and present a holistic study on the impact of architectural design on adversarial robustness. We focus on residual networks and consider architecture design at the block level, i.e., topology, kernel size, activation, and normalization, as well as at the network scaling level, i.e., depth and width of each block in the network. In both cases, we first derive insights through systematic ablative experiments. Then we design a robust residual block, dubbed RobustResBlock, and a compound scaling rule, dubbed RobustScaling, to distribute depth and width at the desired FLOP count. Finally, we combine RobustResBlock and RobustScaling and present a portfolio of adversarially robust residual networks, RobustResNets, spanning a broad spectrum of model capacities. Experimental validation across multiple datasets and adversarial attacks demonstrate that RobustResNets consistently outperform both the standard WRNs and other existing robust architectures, achieving state-of-the-art AutoAttack robust accuracy of 61.1% without additional data and 63.7% with 500K external data while being $2\times$ more compact in terms of parameters. Code is available at \url{ https://github.com/zhichao-lu/robust-residual-network}
Surrogate-assisted Multi-objective Neural Architecture Search for Real-time Semantic Segmentation
Aug 14, 2022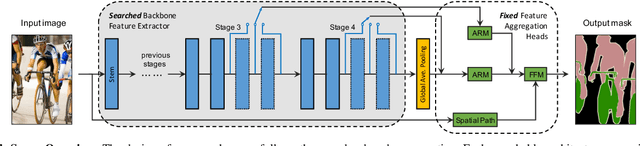
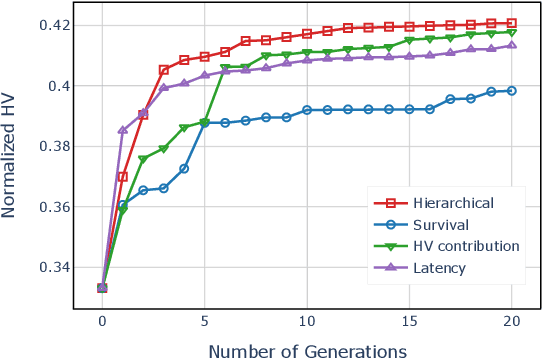

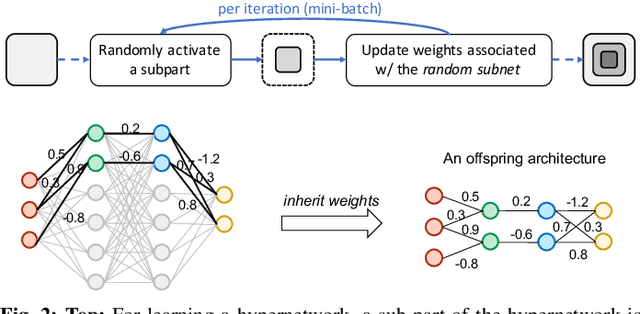
The architectural advancements in deep neural networks have led to remarkable leap-forwards across a broad array of computer vision tasks. Instead of relying on human expertise, neural architecture search (NAS) has emerged as a promising avenue toward automating the design of architectures. While recent achievements in image classification have suggested opportunities, the promises of NAS have yet to be thoroughly assessed on more challenging tasks of semantic segmentation. The main challenges of applying NAS to semantic segmentation arise from two aspects: (i) high-resolution images to be processed; (ii) additional requirement of real-time inference speed (i.e., real-time semantic segmentation) for applications such as autonomous driving. To meet such challenges, we propose a surrogate-assisted multi-objective method in this paper. Through a series of customized prediction models, our method effectively transforms the original NAS task into an ordinary multi-objective optimization problem. Followed by a hierarchical pre-screening criterion for in-fill selection, our method progressively achieves a set of efficient architectures trading-off between segmentation accuracy and inference speed. Empirical evaluations on three benchmark datasets together with an application using Huawei Atlas 200 DK suggest that our method can identify architectures significantly outperforming existing state-of-the-art architectures designed both manually by human experts and automatically by other NAS methods.
Neural Architecture Search as Multiobjective Optimization Benchmarks: Problem Formulation and Performance Assessment
Aug 08, 2022



The ongoing advancements in network architecture design have led to remarkable achievements in deep learning across various challenging computer vision tasks. Meanwhile, the development of neural architecture search (NAS) has provided promising approaches to automating the design of network architectures for lower prediction error. Recently, the emerging application scenarios of deep learning have raised higher demands for network architectures considering multiple design criteria: number of parameters/floating-point operations, and inference latency, among others. From an optimization point of view, the NAS tasks involving multiple design criteria are intrinsically multiobjective optimization problems; hence, it is reasonable to adopt evolutionary multiobjective optimization (EMO) algorithms for tackling them. Nonetheless, there is still a clear gap confining the related research along this pathway: on the one hand, there is a lack of a general problem formulation of NAS tasks from an optimization point of view; on the other hand, there are challenges in conducting benchmark assessments of EMO algorithms on NAS tasks. To bridge the gap: (i) we formulate NAS tasks into general multi-objective optimization problems and analyze the complex characteristics from an optimization point of view; (ii) we present an end-to-end pipeline, dubbed $\texttt{EvoXBench}$, to generate benchmark test problems for EMO algorithms to run efficiently -- without the requirement of GPUs or Pytorch/Tensorflow; (iii) we instantiate two test suites comprehensively covering two datasets, seven search spaces, and three hardware devices, involving up to eight objectives. Based on the above, we validate the proposed test suites using six representative EMO algorithms and provide some empirical analyses. The code of $\texttt{EvoXBench}$ is available from $\href{https://github.com/EMI-Group/EvoXBench}{\rm{here}}$.