 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYawen Huang
AnomalyXFusion: Multi-modal Anomaly Synthesis with Diffusion
May 02, 2024
Anomaly synthesis is one of the effective methods to augment abnormal samples for training. However, current anomaly synthesis methods predominantly rely on texture information as input, which limits the fidelity of synthesized abnormal samples. Because texture information is insufficient to correctly depict the pattern of anomalies, especially for logical anomalies. To surmount this obstacle, we present the AnomalyXFusion framework, designed to harness multi-modality information to enhance the quality of synthesized abnormal samples. The AnomalyXFusion framework comprises two distinct yet synergistic modules: the Multi-modal In-Fusion (MIF) module and the Dynamic Dif-Fusion (DDF) module. The MIF module refines modality alignment by aggregating and integrating various modality features into a unified embedding space, termed X-embedding, which includes image, text, and mask features. Concurrently, the DDF module facilitates controlled generation through an adaptive adjustment of X-embedding conditioned on the diffusion steps. In addition, to reveal the multi-modality representational power of AnomalyXFusion, we propose a new dataset, called MVTec Caption. More precisely, MVTec Caption extends 2.2k accurate image-mask-text annotations for the MVTec AD and LOCO datasets. Comprehensive evaluations demonstrate the effectiveness of AnomalyXFusion, especially regarding the fidelity and diversity for logical anomalies. Project page: http:github.com/hujiecpp/MVTec-Caption
Learning Long-form Video Prior via Generative Pre-Training
Apr 24, 2024Concepts involved in long-form videos such as people, objects, and their interactions, can be viewed as following an implicit prior. They are notably complex and continue to pose challenges to be comprehensively learned. In recent years, generative pre-training (GPT) has exhibited versatile capacities in modeling any kind of text content even visual locations. Can this manner work for learning long-form video prior? Instead of operating on pixel space, it is efficient to employ visual locations like bounding boxes and keypoints to represent key information in videos, which can be simply discretized and then tokenized for consumption by GPT. Due to the scarcity of suitable data, we create a new dataset called \textbf{Storyboard20K} from movies to serve as a representative. It includes synopses, shot-by-shot keyframes, and fine-grained annotations of film sets and characters with consistent IDs, bounding boxes, and whole body keypoints. In this way, long-form videos can be represented by a set of tokens and be learned via generative pre-training. Experimental results validate that our approach has great potential for learning long-form video prior. Code and data will be released at \url{https://github.com/showlab/Long-form-Video-Prior}.
NeRF2Points: Large-Scale Point Cloud Generation From Street Views' Radiance Field Optimization
Apr 07, 2024Neural Radiance Fields (NeRF) have emerged as a paradigm-shifting methodology for the photorealistic rendering of objects and environments, enabling the synthesis of novel viewpoints with remarkable fidelity. This is accomplished through the strategic utilization of object-centric camera poses characterized by significant inter-frame overlap. This paper explores a compelling, alternative utility of NeRF: the derivation of point clouds from aggregated urban landscape imagery. The transmutation of street-view data into point clouds is fraught with complexities, attributable to a nexus of interdependent variables. First, high-quality point cloud generation hinges on precise camera poses, yet many datasets suffer from inaccuracies in pose metadata. Also, the standard approach of NeRF is ill-suited for the distinct characteristics of street-view data from autonomous vehicles in vast, open settings. Autonomous vehicle cameras often record with limited overlap, leading to blurring, artifacts, and compromised pavement representation in NeRF-based point clouds. In this paper, we present NeRF2Points, a tailored NeRF variant for urban point cloud synthesis, notable for its high-quality output from RGB inputs alone. Our paper is supported by a bespoke, high-resolution 20-kilometer urban street dataset, designed for point cloud generation and evaluation. NeRF2Points adeptly navigates the inherent challenges of NeRF-based point cloud synthesis through the implementation of the following strategic innovations: (1) Integration of Weighted Iterative Geometric Optimization (WIGO) and Structure from Motion (SfM) for enhanced camera pose accuracy, elevating street-view data precision. (2) Layered Perception and Integrated Modeling (LPiM) is designed for distinct radiance field modeling in urban environments, resulting in coherent point cloud representations.
ConRF: Zero-shot Stylization of 3D Scenes with Conditioned Radiation Fields
Feb 02, 2024Most of the existing works on arbitrary 3D NeRF style transfer required retraining on each single style condition. This work aims to achieve zero-shot controlled stylization in 3D scenes utilizing text or visual input as conditioning factors. We introduce ConRF, a novel method of zero-shot stylization. Specifically, due to the ambiguity of CLIP features, we employ a conversion process that maps the CLIP feature space to the style space of a pre-trained VGG network and then refine the CLIP multi-modal knowledge into a style transfer neural radiation field. Additionally, we use a 3D volumetric representation to perform local style transfer. By combining these operations, ConRF offers the capability to utilize either text or images as references, resulting in the generation of sequences with novel views enhanced by global or local stylization. Our experiment demonstrates that ConRF outperforms other existing methods for 3D scene and single-text stylization in terms of visual quality.
CTNeRF: Cross-Time Transformer for Dynamic Neural Radiance Field from Monocular Video
Jan 10, 2024The goal of our work is to generate high-quality novel views from monocular videos of complex and dynamic scenes. Prior methods, such as DynamicNeRF, have shown impressive performance by leveraging time-varying dynamic radiation fields. However, these methods have limitations when it comes to accurately modeling the motion of complex objects, which can lead to inaccurate and blurry renderings of details. To address this limitation, we propose a novel approach that builds upon a recent generalization NeRF, which aggregates nearby views onto new viewpoints. However, such methods are typically only effective for static scenes. To overcome this challenge, we introduce a module that operates in both the time and frequency domains to aggregate the features of object motion. This allows us to learn the relationship between frames and generate higher-quality images. Our experiments demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets. Specifically, our approach outperforms existing methods in terms of both the accuracy and visual quality of the synthesized views.
Federated Learning via Input-Output Collaborative Distillation
Dec 22, 2023Federated learning (FL) is a machine learning paradigm in which distributed local nodes collaboratively train a central model without sharing individually held private data. Existing FL methods either iteratively share local model parameters or deploy co-distillation. However, the former is highly susceptible to private data leakage, and the latter design relies on the prerequisites of task-relevant real data. Instead, we propose a data-free FL framework based on local-to-central collaborative distillation with direct input and output space exploitation. Our design eliminates any requirement of recursive local parameter exchange or auxiliary task-relevant data to transfer knowledge, thereby giving direct privacy control to local users. In particular, to cope with the inherent data heterogeneity across locals, our technique learns to distill input on which each local model produces consensual yet unique results to represent each expertise. Our proposed FL framework achieves notable privacy-utility trade-offs with extensive experiments on image classification and segmentation tasks under various real-world heterogeneous federated learning settings on both natural and medical images.
UniHead: Unifying Multi-Perception for Detection Heads
Sep 23, 2023The detection head constitutes a pivotal component within object detectors, tasked with executing both classification and localization functions. Regrettably, the commonly used parallel head often lacks omni perceptual capabilities, such as deformation perception, global perception and cross-task perception. Despite numerous methods attempt to enhance these abilities from a single aspect, achieving a comprehensive and unified solution remains a significant challenge. In response to this challenge, we have developed an innovative detection head, termed UniHead, to unify three perceptual abilities simultaneously. More precisely, our approach (1) introduces deformation perception, enabling the model to adaptively sample object features; (2) proposes a Dual-axial Aggregation Transformer (DAT) to adeptly model long-range dependencies, thereby achieving global perception; and (3) devises a Cross-task Interaction Transformer (CIT) that facilitates interaction between the classification and localization branches, thus aligning the two tasks. As a plug-and-play method, the proposed UniHead can be conveniently integrated with existing detectors. Extensive experiments on the COCO dataset demonstrate that our UniHead can bring significant improvements to many detectors. For instance, the UniHead can obtain +2.7 AP gains in RetinaNet, +2.9 AP gains in FreeAnchor, and +2.1 AP gains in GFL. The code will be publicly available. Code Url: https://github.com/zht8506/UniHead.
Automatic view plane prescription for cardiac magnetic resonance imaging via supervision by spatial relationship between views
Sep 22, 2023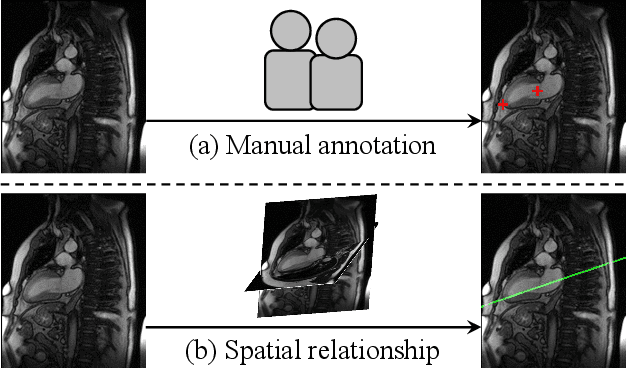
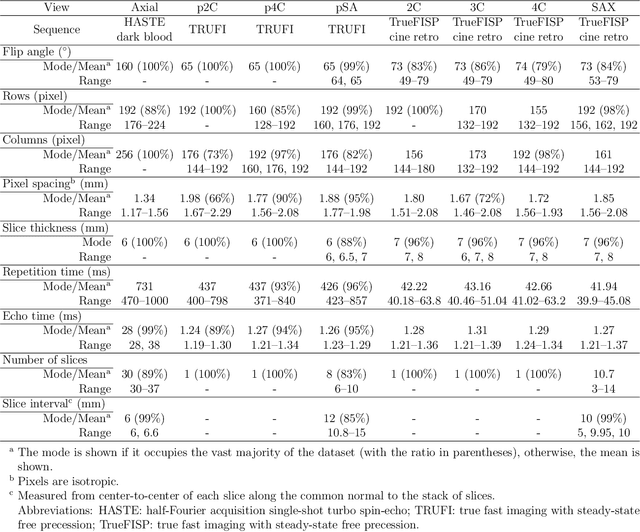
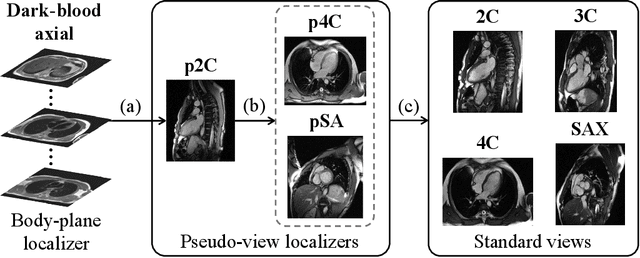
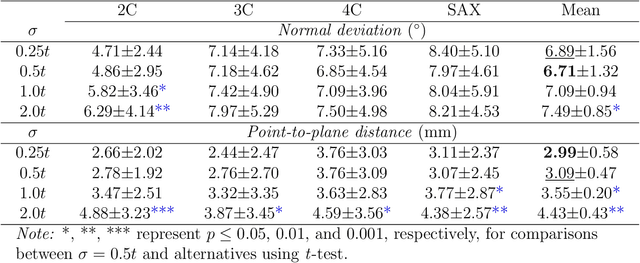
Background: View planning for the acquisition of cardiac magnetic resonance (CMR) imaging remains a demanding task in clinical practice. Purpose: Existing approaches to its automation relied either on an additional volumetric image not typically acquired in clinic routine, or on laborious manual annotations of cardiac structural landmarks. This work presents a clinic-compatible, annotation-free system for automatic CMR view planning. Methods: The system mines the spatial relationship, more specifically, locates the intersecting lines, between the target planes and source views, and trains deep networks to regress heatmaps defined by distances from the intersecting lines. The intersection lines are the prescription lines prescribed by the technologists at the time of image acquisition using cardiac landmarks, and retrospectively identified from the spatial relationship. As the spatial relationship is self-contained in properly stored data, the need for additional manual annotation is eliminated. In addition, the interplay of multiple target planes predicted in a source view is utilized in a stacked hourglass architecture to gradually improve the regression. Then, a multi-view planning strategy is proposed to aggregate information from the predicted heatmaps for all the source views of a target plane, for a globally optimal prescription, mimicking the similar strategy practiced by skilled human prescribers. Results: The experiments include 181 CMR exams. Our system yields the mean angular difference and point-to-plane distance of 5.68 degrees and 3.12 mm, respectively. It not only achieves superior accuracy to existing approaches including conventional atlas-based and newer deep-learning-based in prescribing the four standard CMR planes but also demonstrates prescription of the first cardiac-anatomy-oriented plane(s) from the body-oriented scout.
DS-Depth: Dynamic and Static Depth Estimation via a Fusion Cost Volume
Aug 14, 2023
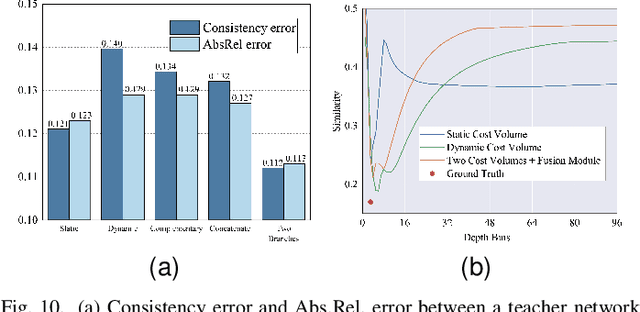
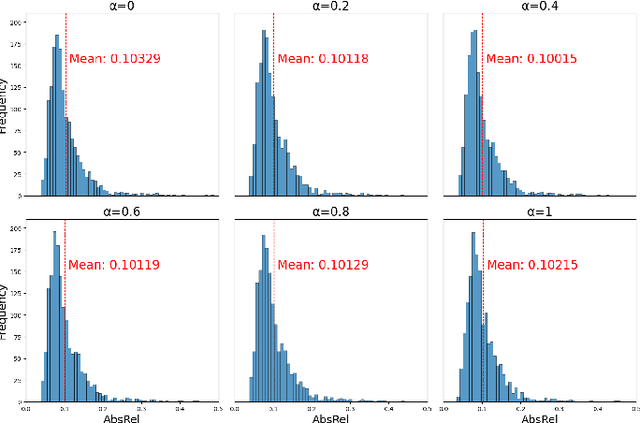
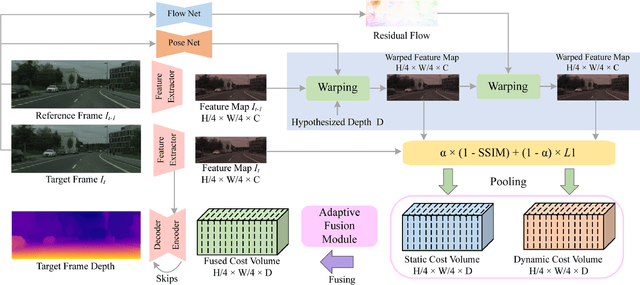
Self-supervised monocular depth estimation methods typically rely on the reprojection error to capture geometric relationships between successive frames in static environments. However, this assumption does not hold in dynamic objects in scenarios, leading to errors during the view synthesis stage, such as feature mismatch and occlusion, which can significantly reduce the accuracy of the generated depth maps. To address this problem, we propose a novel dynamic cost volume that exploits residual optical flow to describe moving objects, improving incorrectly occluded regions in static cost volumes used in previous work. Nevertheless, the dynamic cost volume inevitably generates extra occlusions and noise, thus we alleviate this by designing a fusion module that makes static and dynamic cost volumes compensate for each other. In other words, occlusion from the static volume is refined by the dynamic volume, and incorrect information from the dynamic volume is eliminated by the static volume. Furthermore, we propose a pyramid distillation loss to reduce photometric error inaccuracy at low resolutions and an adaptive photometric error loss to alleviate the flow direction of the large gradient in the occlusion regions. We conducted extensive experiments on the KITTI and Cityscapes datasets, and the results demonstrate that our model outperforms previously published baselines for self-supervised monocular depth estimation.
BoxDiff: Text-to-Image Synthesis with Training-Free Box-Constrained Diffusion
Aug 10, 2023


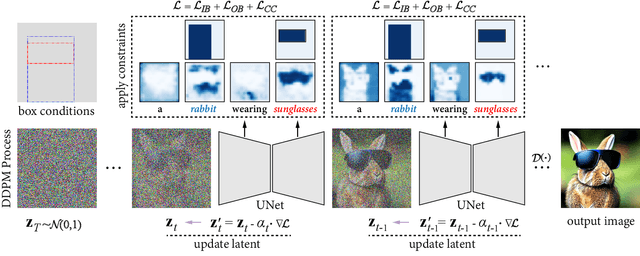
Recent text-to-image diffusion models have demonstrated an astonishing capacity to generate high-quality images. However, researchers mainly studied the way of synthesizing images with only text prompts. While some works have explored using other modalities as conditions, considerable paired data, e.g., box/mask-image pairs, and fine-tuning time are required for nurturing models. As such paired data is time-consuming and labor-intensive to acquire and restricted to a closed set, this potentially becomes the bottleneck for applications in an open world. This paper focuses on the simplest form of user-provided conditions, e.g., box or scribble. To mitigate the aforementioned problem, we propose a training-free method to control objects and contexts in the synthesized images adhering to the given spatial conditions. Specifically, three spatial constraints, i.e., Inner-Box, Outer-Box, and Corner Constraints, are designed and seamlessly integrated into the denoising step of diffusion models, requiring no additional training and massive annotated layout data. Extensive results show that the proposed constraints can control what and where to present in the images while retaining the ability of the Stable Diffusion model to synthesize with high fidelity and diverse concept coverage. The code is publicly available at https://github.com/Sierkinhane/BoxDiff.