 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhaoxu Li
Mora: Enabling Generalist Video Generation via A Multi-Agent Framework
Mar 22, 2024

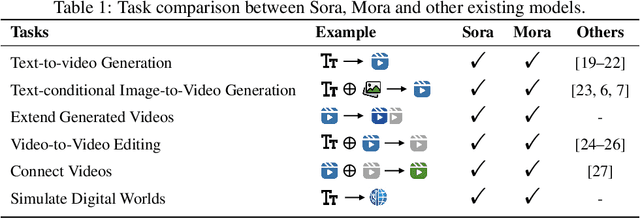
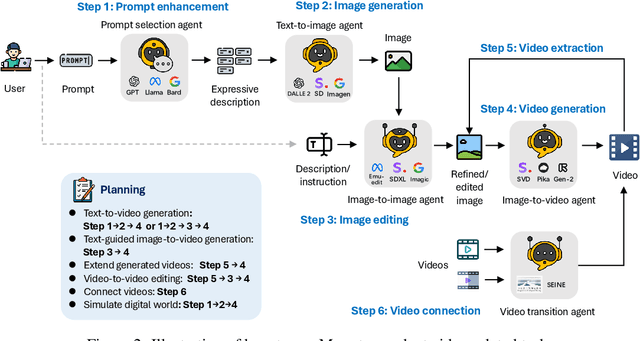

Sora is the first large-scale generalist video generation model that garnered significant attention across society. Since its launch by OpenAI in February 2024, no other video generation models have paralleled {Sora}'s performance or its capacity to support a broad spectrum of video generation tasks. Additionally, there are only a few fully published video generation models, with the majority being closed-source. To address this gap, this paper proposes a new multi-agent framework Mora, which incorporates several advanced visual AI agents to replicate generalist video generation demonstrated by Sora. In particular, Mora can utilize multiple visual agents and successfully mimic Sora's video generation capabilities in various tasks, such as (1) text-to-video generation, (2) text-conditional image-to-video generation, (3) extend generated videos, (4) video-to-video editing, (5) connect videos and (6) simulate digital worlds. Our extensive experimental results show that Mora achieves performance that is proximate to that of Sora in various tasks. However, there exists an obvious performance gap between our work and Sora when assessed holistically. In summary, we hope this project can guide the future trajectory of video generation through collaborative AI agents.
TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones
Dec 28, 2023In the era of advanced multimodel learning, multimodal large language models (MLLMs) such as GPT-4V have made remarkable strides towards bridging language and visual elements. However, the closed-source nature and considerable computational demand present notable challenges for universal usage and modifications. This is where open-source MLLMs like LLaVA and MiniGPT-4 come in, presenting groundbreaking achievements across tasks. Despite these accomplishments, computational efficiency remains an unresolved issue, as these models, like LLaVA-v1.5-13B, require substantial resources. Addressing these issues, we introduce TinyGPT-V, a new-wave model marrying impressive performance with commonplace computational capacity. It stands out by requiring merely a 24G GPU for training and an 8G GPU or CPU for inference. Built upon Phi-2, TinyGPT-V couples an effective language backbone with pre-trained vision modules from BLIP-2 or CLIP. TinyGPT-V's 2.8B parameters can undergo a unique quantisation process, suitable for local deployment and inference tasks on 8G various devices. Our work fosters further developments for designing cost-effective, efficient, and high-performing MLLMs, expanding their applicability in a broad array of real-world scenarios. Furthermore this paper proposed a new paradigm of Multimodal Large Language Model via small backbones. Our code and training weights are placed at: https://github.com/DLYuanGod/TinyGPT-V and https://huggingface.co/Tyrannosaurus/TinyGPT-V respectively.
You Only Train Once: Learning a General Anomaly Enhancement Network with Random Masks for Hyperspectral Anomaly Detection
Mar 31, 2023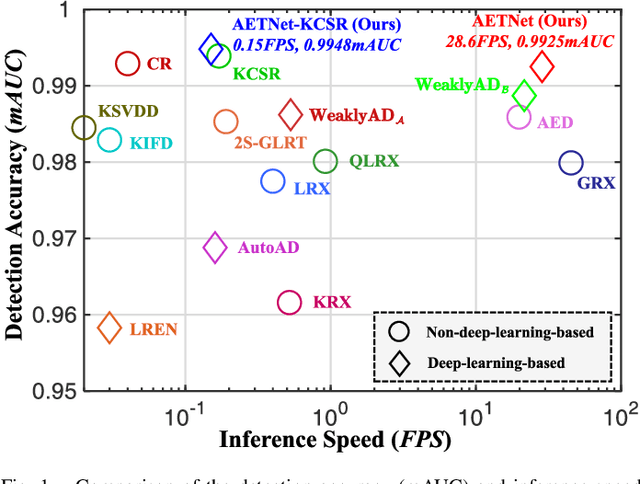
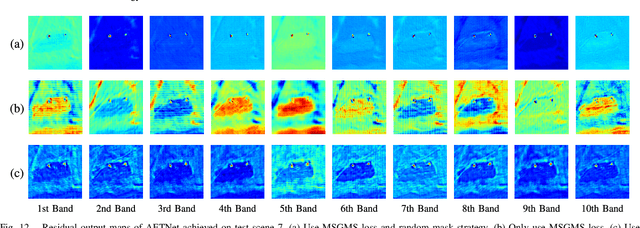
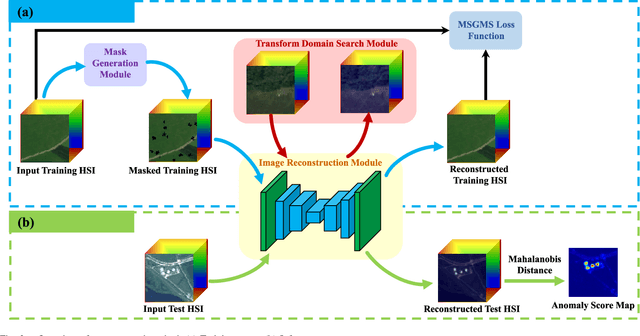
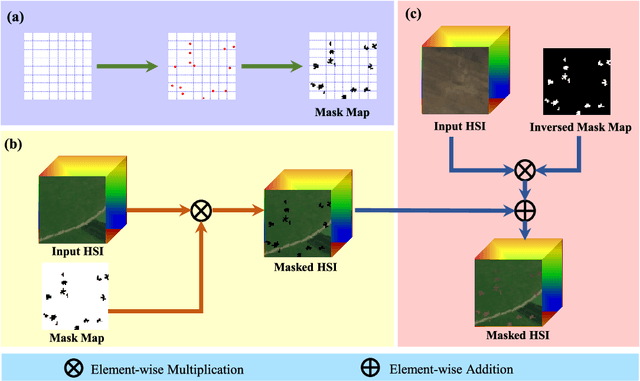
In this paper, we introduce a new approach to address the challenge of generalization in hyperspectral anomaly detection (AD). Our method eliminates the need for adjusting parameters or retraining on new test scenes as required by most existing methods. Employing an image-level training paradigm, we achieve a general anomaly enhancement network for hyperspectral AD that only needs to be trained once. Trained on a set of anomaly-free hyperspectral images with random masks, our network can learn the spatial context characteristics between anomalies and background in an unsupervised way. Additionally, a plug-and-play model selection module is proposed to search for a spatial-spectral transform domain that is more suitable for AD task than the original data. To establish a unified benchmark to comprehensively evaluate our method and existing methods, we develop a large-scale hyperspectral AD dataset (HAD100) that includes 100 real test scenes with diverse anomaly targets. In comparison experiments, we combine our network with a parameter-free detector and achieve the optimal balance between detection accuracy and inference speed among state-of-the-art AD methods. Experimental results also show that our method still achieves competitive performance when the training and test set are captured by different sensor devices. Our code is available at https://github.com/ZhaoxuLi123/AETNet.
Flexible-modal Deception Detection with Audio-Visual Adapter
Feb 11, 2023



Detecting deception by human behaviors is vital in many fields such as custom security and multimedia anti-fraud. Recently, audio-visual deception detection attracts more attention due to its better performance than using only a single modality. However, in real-world multi-modal settings, the integrity of data can be an issue (e.g., sometimes only partial modalities are available). The missing modality might lead to a decrease in performance, but the model still learns the features of the missed modality. In this paper, to further improve the performance and overcome the missing modality problem, we propose a novel Transformer-based framework with an Audio-Visual Adapter (AVA) to fuse temporal features across two modalities efficiently. Extensive experiments conducted on two benchmark datasets demonstrate that the proposed method can achieve superior performance compared with other multi-modal fusion methods under flexible-modal (multiple and missing modalities) settings.