 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenheng Yang
Weakly Supervised Instance Segmentation for Videos with Temporal Mask Consistency
Mar 23, 2021
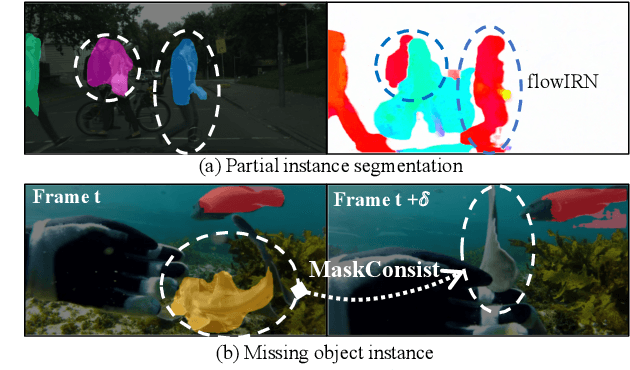
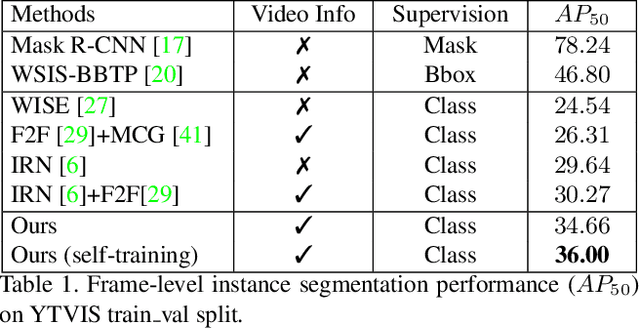
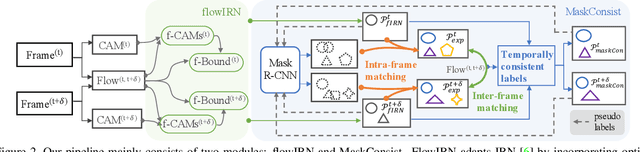
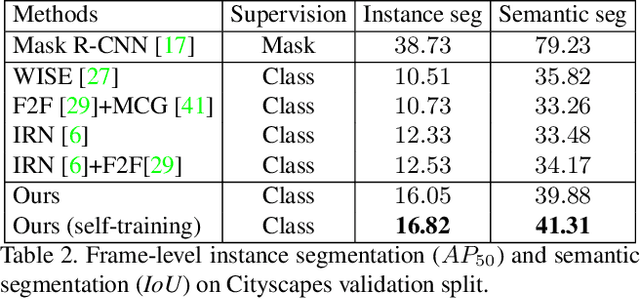
Weakly supervised instance segmentation reduces the cost of annotations required to train models. However, existing approaches which rely only on image-level class labels predominantly suffer from errors due to (a) partial segmentation of objects and (b) missing object predictions. We show that these issues can be better addressed by training with weakly labeled videos instead of images. In videos, motion and temporal consistency of predictions across frames provide complementary signals which can help segmentation. We are the first to explore the use of these video signals to tackle weakly supervised instance segmentation. We propose two ways to leverage this information in our model. First, we adapt inter-pixel relation network (IRN) to effectively incorporate motion information during training. Second, we introduce a new MaskConsist module, which addresses the problem of missing object instances by transferring stable predictions between neighboring frames during training. We demonstrate that both approaches together improve the instance segmentation metric $AP_{50}$ on video frames of two datasets: Youtube-VIS and Cityscapes by $5\%$ and $3\%$ respectively.
SPAN: Spatial Pyramid Attention Network forImage Manipulation Localization
Sep 01, 2020

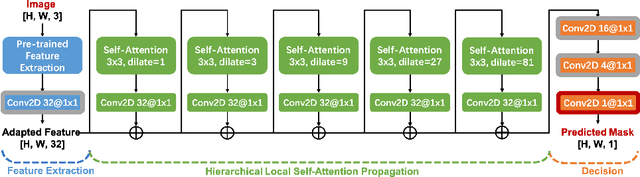
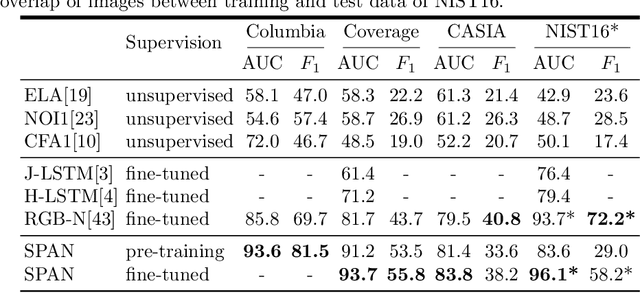
We present a novel framework, Spatial Pyramid Attention Network (SPAN) for detection and localization of multiple types of image manipulations. The proposed architecture efficiently and effectively models the relationship between image patches at multiple scales by constructing a pyramid of local self-attention blocks. The design includes a novel position projection to encode the spatial positions of the patches. SPAN is trained on a generic, synthetic dataset but can also be fine tuned for specific datasets; The proposed method shows significant gains in performance on standard datasets over previous state-of-the-art methods.
Activity Driven Weakly Supervised Object Detection
Apr 02, 2019
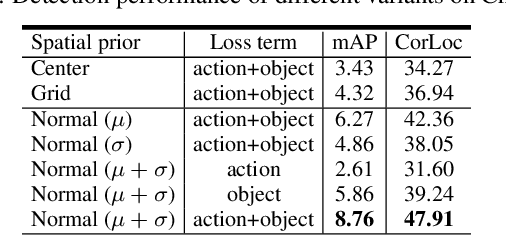
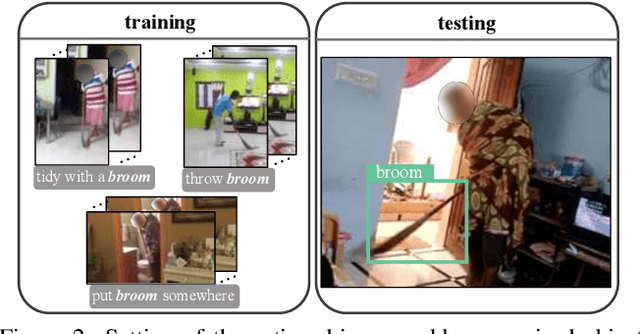
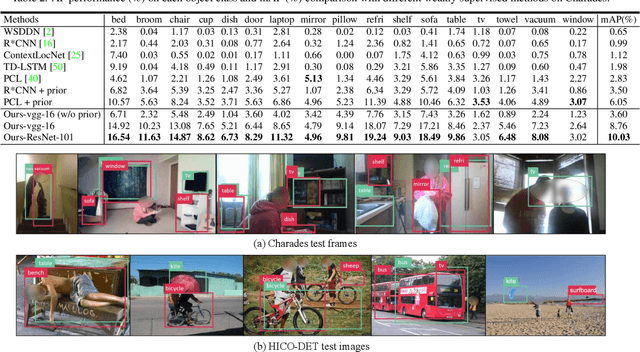
Weakly supervised object detection aims at reducing the amount of supervision required to train detection models. Such models are traditionally learned from images/videos labelled only with the object class and not the object bounding box. In our work, we try to leverage not only the object class labels but also the action labels associated with the data. We show that the action depicted in the image/video can provide strong cues about the location of the associated object. We learn a spatial prior for the object dependent on the action (e.g. "ball" is closer to "leg of the person" in "kicking ball"), and incorporate this prior to simultaneously train a joint object detection and action classification model. We conducted experiments on both video datasets and image datasets to evaluate the performance of our weakly supervised object detection model. Our approach outperformed the current state-of-the-art (SOTA) method by more than 6% in mAP on the Charades video dataset.
Every Pixel Counts ++: Joint Learning of Geometry and Motion with 3D Holistic Understanding
Oct 14, 2018

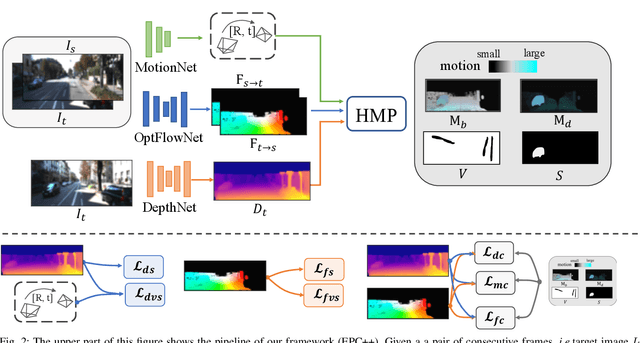
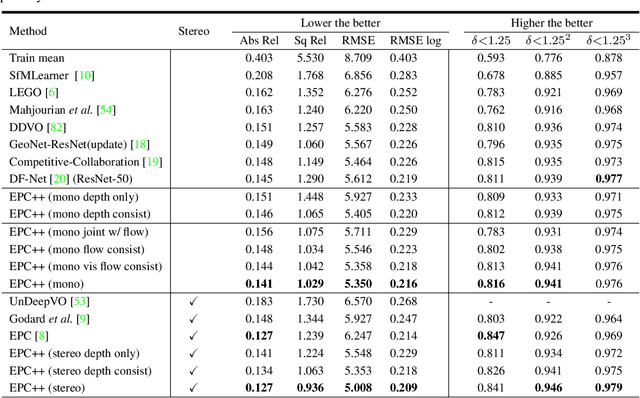
Learning to estimate 3D geometry in a single frame and optical flow from consecutive frames by watching unlabeled videos via deep convolutional network has made significant process recently. Current state-of-the-art (SOTA) methods treat the tasks independently. One important assumption of the current depth estimation pipeline is that the scene contains no moving object, which can be complemented by the optical flow. In this paper, we propose to address the two tasks as a whole, i.e. to jointly understand per-pixel 3D geometry and motion. This also eliminates the need of static scene assumption and enforces the inherent geometrical consistency during the learning process, yielding significantly improved results for both tasks. We call our method as "Every Pixel Counts++" or "EPC++". Specifically, during training, given two consecutive frames from a video, we adopt three parallel networks to predict the camera motion (MotionNet), dense depth map (DepthNet), and per-pixel optical flow between two frames (FlowNet) respectively. Comprehensive experiments were conducted on the KITTI 2012 and KITTI 2015 datasets. Performance on the five tasks of depth estimation, optical flow estimation, odometry, moving object segmentation and scene flow estimation shows that our approach outperforms other SOTA methods, demonstrating the effectiveness of each module of our proposed method.
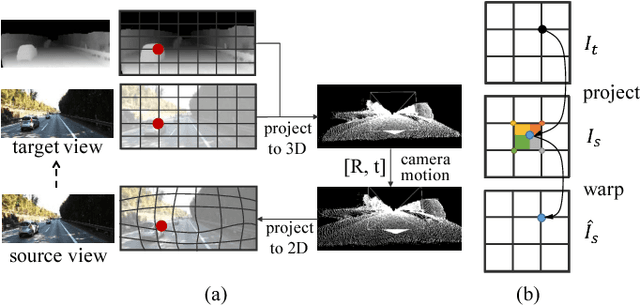
Joint Unsupervised Learning of Optical Flow and Depth by Watching Stereo Videos
Oct 08, 2018
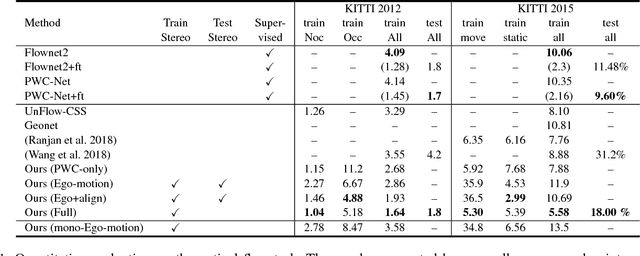
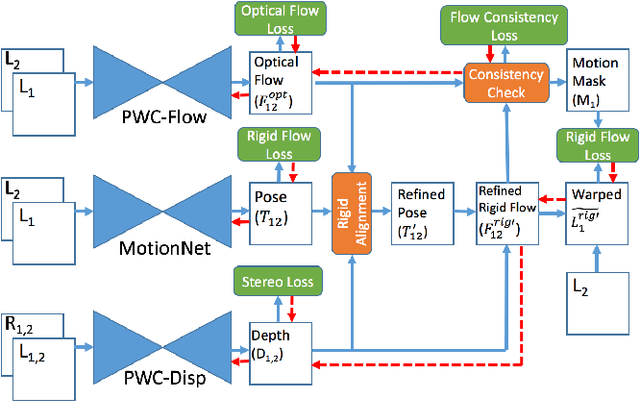
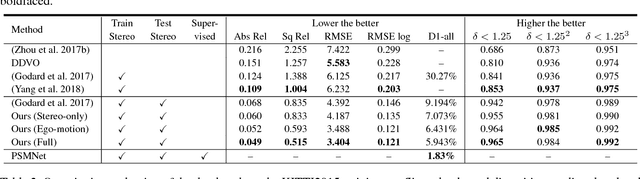
Learning depth and optical flow via deep neural networks by watching videos has made significant progress recently. In this paper, we jointly solve the two tasks by exploiting the underlying geometric rules within stereo videos. Specifically, given two consecutive stereo image pairs from a video, we first estimate depth, camera ego-motion and optical flow from three neural networks. Then the whole scene is decomposed into moving foreground and static background by compar- ing the estimated optical flow and rigid flow derived from the depth and ego-motion. We propose a novel consistency loss to let the optical flow learn from the more accurate rigid flow in static regions. We also design a rigid alignment module which helps refine ego-motion estimation by using the estimated depth and optical flow. Experiments on the KITTI dataset show that our results significantly outperform other state-of- the-art algorithms. Source codes can be found at https: //github.com/baidu-research/UnDepthflow
Every Pixel Counts: Unsupervised Geometry Learning with Holistic 3D Motion Understanding
Aug 15, 2018

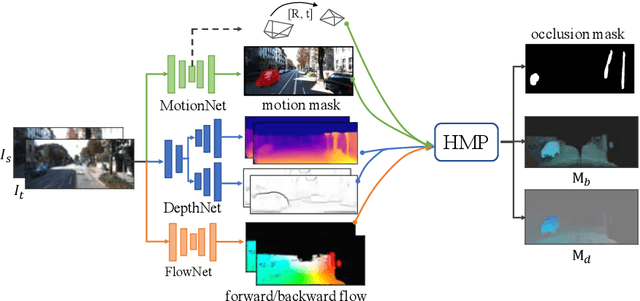
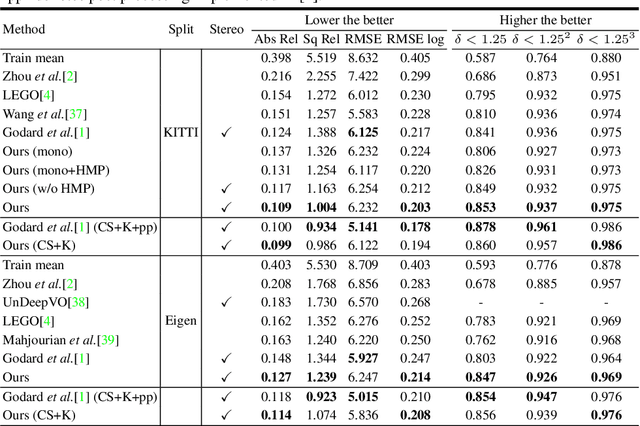
Learning to estimate 3D geometry in a single image by watching unlabeled videos via deep convolutional network has made significant process recently. Current state-of-the-art (SOTA) methods, are based on the learning framework of rigid structure-from-motion, where only 3D camera ego motion is modeled for geometry estimation.However, moving objects also exist in many videos, e.g. moving cars in a street scene. In this paper, we tackle such motion by additionally incorporating per-pixel 3D object motion into the learning framework, which provides holistic 3D scene flow understanding and helps single image geometry estimation. Specifically, given two consecutive frames from a video, we adopt a motion network to predict their relative 3D camera pose and a segmentation mask distinguishing moving objects and rigid background. An optical flow network is used to estimate dense 2D per-pixel correspondence. A single image depth network predicts depth maps for both images. The four types of information, i.e. 2D flow, camera pose, segment mask and depth maps, are integrated into a differentiable holistic 3D motion parser (HMP), where per-pixel 3D motion for rigid background and moving objects are recovered. We design various losses w.r.t. the two types of 3D motions for training the depth and motion networks, yielding further error reduction for estimated geometry. Finally, in order to solve the 3D motion confusion from monocular videos, we combine stereo images into joint training. Experiments on KITTI 2015 dataset show that our estimated geometry, 3D motion and moving object masks, not only are constrained to be consistent, but also significantly outperforms other SOTA algorithms, demonstrating the benefits of our approach.
Occlusion Aware Unsupervised Learning of Optical Flow
Apr 04, 2018
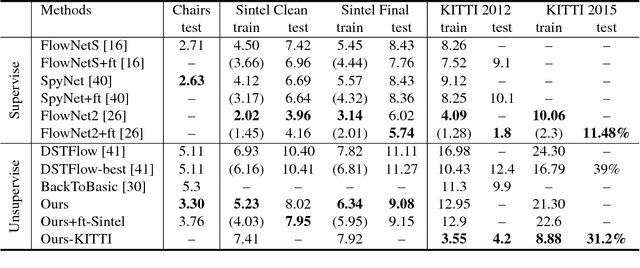

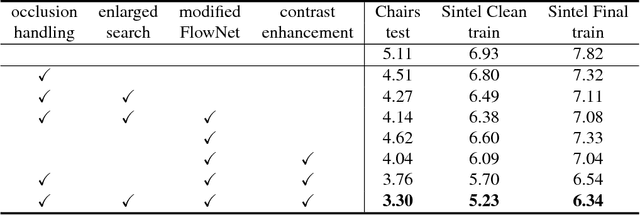
It has been recently shown that a convolutional neural network can learn optical flow estimation with unsupervised learning. However, the performance of the unsupervised methods still has a relatively large gap compared to its supervised counterpart. Occlusion and large motion are some of the major factors that limit the current unsupervised learning of optical flow methods. In this work we introduce a new method which models occlusion explicitly and a new warping way that facilitates the learning of large motion. Our method shows promising results on Flying Chairs, MPI-Sintel and KITTI benchmark datasets. Especially on KITTI dataset where abundant unlabeled samples exist, our unsupervised method outperforms its counterpart trained with supervised learning.
LEGO: Learning Edge with Geometry all at Once by Watching Videos
Mar 24, 2018

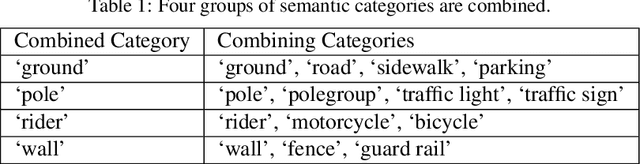
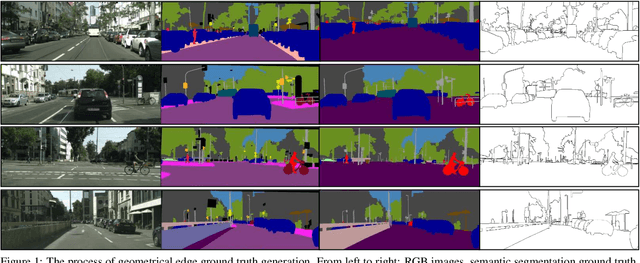
Learning to estimate 3D geometry in a single image by watching unlabeled videos via deep convolutional network is attracting significant attention. In this paper, we introduce a "3D as-smooth-as-possible (3D-ASAP)" prior inside the pipeline, which enables joint estimation of edges and 3D scene, yielding results with significant improvement in accuracy for fine detailed structures. Specifically, we define the 3D-ASAP prior by requiring that any two points recovered in 3D from an image should lie on an existing planar surface if no other cues provided. We design an unsupervised framework that Learns Edges and Geometry (depth, normal) all at Once (LEGO). The predicted edges are embedded into depth and surface normal smoothness terms, where pixels without edges in-between are constrained to satisfy the prior. In our framework, the predicted depths, normals and edges are forced to be consistent all the time. We conduct experiments on KITTI to evaluate our estimated geometry and CityScapes to perform edge evaluation. We show that in all of the tasks, i.e.depth, normal and edge, our algorithm vastly outperforms other state-of-the-art (SOTA) algorithms, demonstrating the benefits of our approach.
Unsupervised Learning of Geometry with Edge-aware Depth-Normal Consistency
Nov 10, 2017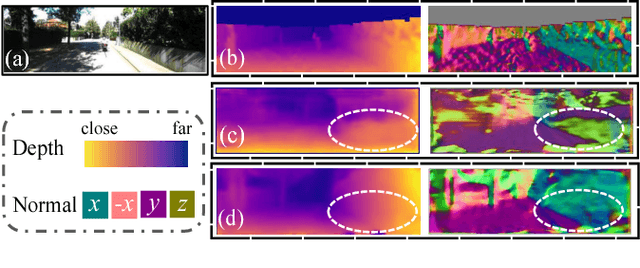


Learning to reconstruct depths in a single image by watching unlabeled videos via deep convolutional network (DCN) is attracting significant attention in recent years. In this paper, we introduce a surface normal representation for unsupervised depth estimation framework. Our estimated depths are constrained to be compatible with predicted normals, yielding more robust geometry results. Specifically, we formulate an edge-aware depth-normal consistency term, and solve it by constructing a depth-to-normal layer and a normal-to-depth layer inside of the DCN. The depth-to-normal layer takes estimated depths as input, and computes normal directions using cross production based on neighboring pixels. Then given the estimated normals, the normal-to-depth layer outputs a regularized depth map through local planar smoothness. Both layers are computed with awareness of edges inside the image to help address the issue of depth/normal discontinuity and preserve sharp edges. Finally, to train the network, we apply the photometric error and gradient smoothness for both depth and normal predictions. We conducted experiments on both outdoor (KITTI) and indoor (NYUv2) datasets, and show that our algorithm vastly outperforms state of the art, which demonstrates the benefits from our approach.
TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals
Aug 04, 2017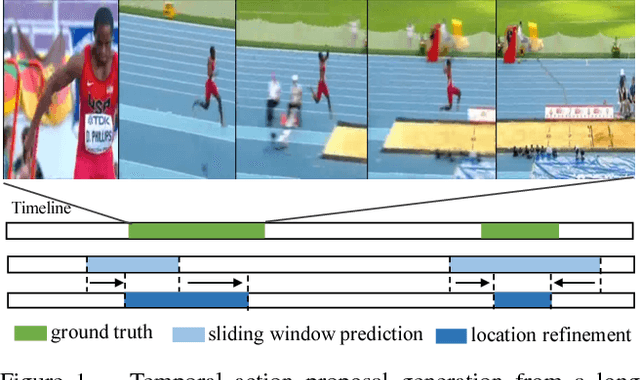
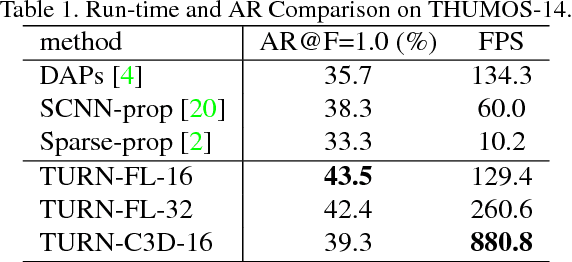
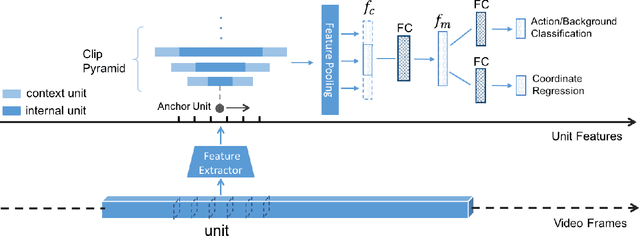
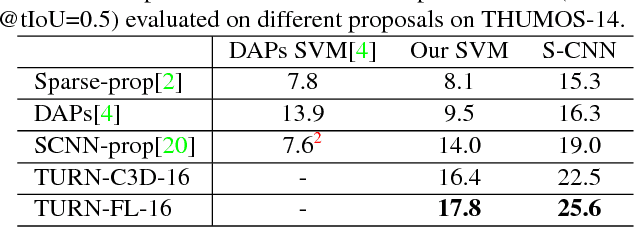
Temporal Action Proposal (TAP) generation is an important problem, as fast and accurate extraction of semantically important (e.g. human actions) segments from untrimmed videos is an important step for large-scale video analysis. We propose a novel Temporal Unit Regression Network (TURN) model. There are two salient aspects of TURN: (1) TURN jointly predicts action proposals and refines the temporal boundaries by temporal coordinate regression; (2) Fast computation is enabled by unit feature reuse: a long untrimmed video is decomposed into video units, which are reused as basic building blocks of temporal proposals. TURN outperforms the state-of-the-art methods under average recall (AR) by a large margin on THUMOS-14 and ActivityNet datasets, and runs at over 880 frames per second (FPS) on a TITAN X GPU. We further apply TURN as a proposal generation stage for existing temporal action localization pipelines, it outperforms state-of-the-art performance on THUMOS-14 and ActivityNet.