 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhenzhi Wu
Learnable Heterogeneous Convolution: Learning both topology and strength
Jan 13, 2023



Existing convolution techniques in artificial neural networks suffer from huge computation complexity, while the biological neural network works in a much more powerful yet efficient way. Inspired by the biological plasticity of dendritic topology and synaptic strength, our method, Learnable Heterogeneous Convolution, realizes joint learning of kernel shape and weights, which unifies existing handcrafted convolution techniques in a data-driven way. A model based on our method can converge with structural sparse weights and then be accelerated by devices of high parallelism. In the experiments, our method either reduces VGG16/19 and ResNet34/50 computation by nearly 5x on CIFAR10 and 2x on ImageNet without harming the performance, where the weights are compressed by 10x and 4x respectively; or improves the accuracy by up to 1.0% on CIFAR10 and 0.5% on ImageNet with slightly higher efficiency. The code will be available on www.github.com/Genera1Z/LearnableHeterogeneousConvolution.
LIAF-Net: Leaky Integrate and Analog Fire Network for Lightweight and Efficient Spatiotemporal Information Processing
Nov 12, 2020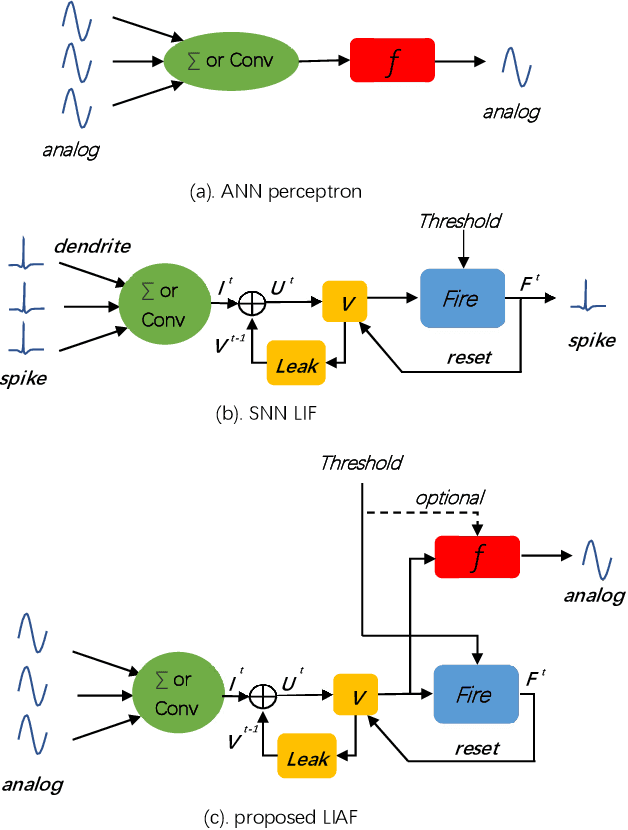
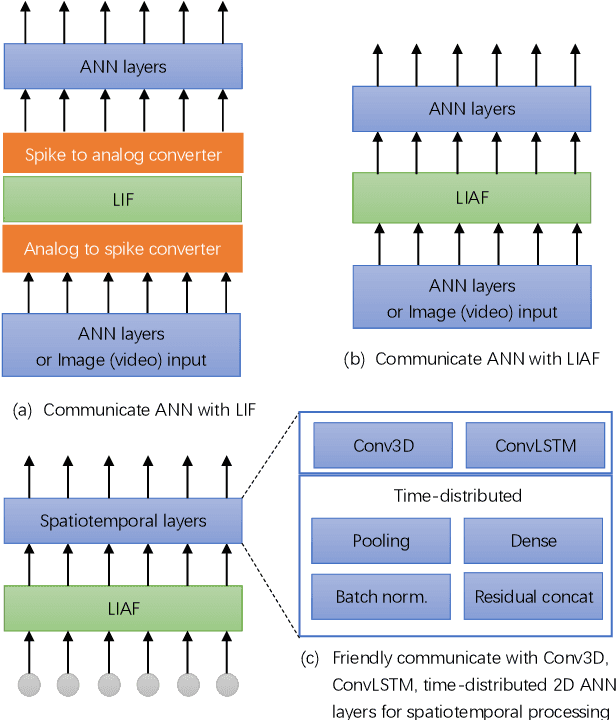

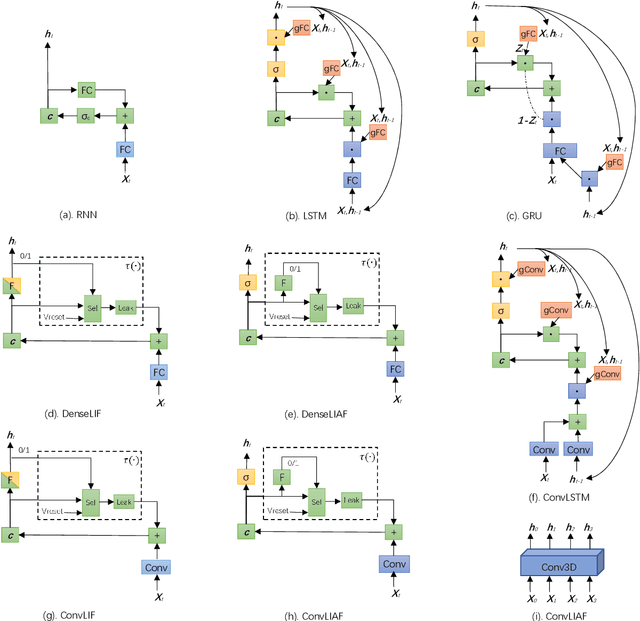
Spiking neural networks (SNNs) based on Leaky Integrate and Fire (LIF) model have been applied to energy-efficient temporal and spatiotemporal processing tasks. Thanks to the bio-plausible neuronal dynamics and simplicity, LIF-SNN benefits from event-driven processing, however, usually faces the embarrassment of reduced performance. This may because in LIF-SNN the neurons transmit information via spikes. To address this issue, in this work, we propose a Leaky Integrate and Analog Fire (LIAF) neuron model, so that analog values can be transmitted among neurons, and a deep network termed as LIAF-Net is built on it for efficient spatiotemporal processing. In the temporal domain, LIAF follows the traditional LIF dynamics to maintain its temporal processing capability. In the spatial domain, LIAF is able to integrate spatial information through convolutional integration or fully-connected integration. As a spatiotemporal layer, LIAF can also be used with traditional artificial neural network (ANN) layers jointly. Experiment results indicate that LIAF-Net achieves comparable performance to Gated Recurrent Unit (GRU) and Long short-term memory (LSTM) on bAbI Question Answering (QA) tasks, and achieves state-of-the-art performance on spatiotemporal Dynamic Vision Sensor (DVS) datasets, including MNIST-DVS, CIFAR10-DVS and DVS128 Gesture, with much less number of synaptic weights and computational overhead compared with traditional networks built by LSTM, GRU, Convolutional LSTM (ConvLSTM) or 3D convolution (Conv3D). Compared with traditional LIF-SNN, LIAF-Net also shows dramatic accuracy gain on all these experiments. In conclusion, LIAF-Net provides a framework combining the advantages of both ANNs and SNNs for lightweight and efficient spatiotemporal information processing.
GXNOR-Net: Training deep neural networks with ternary weights and activations without full-precision memory under a unified discretization framework
May 02, 2018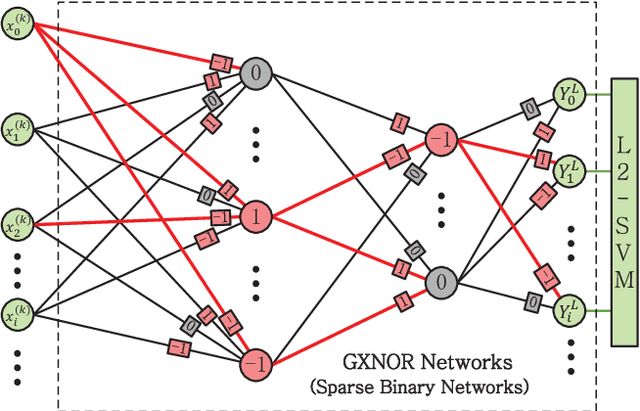
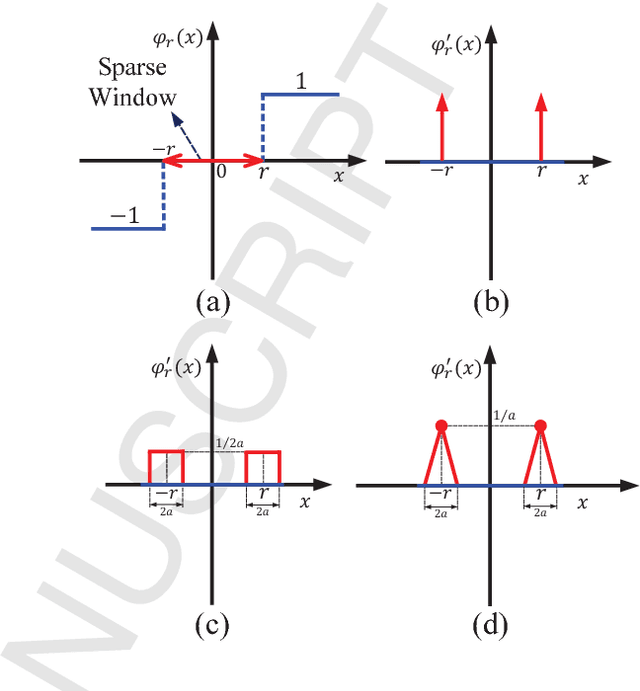
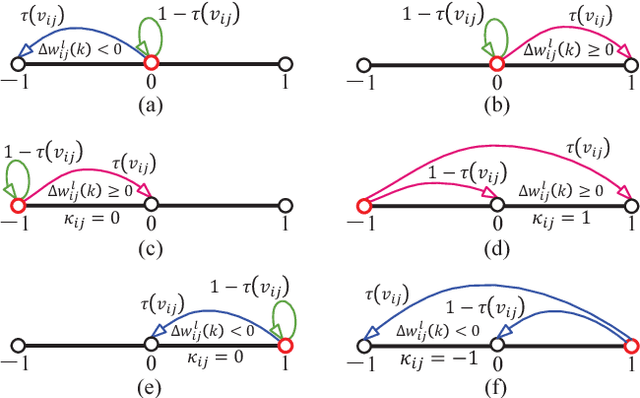
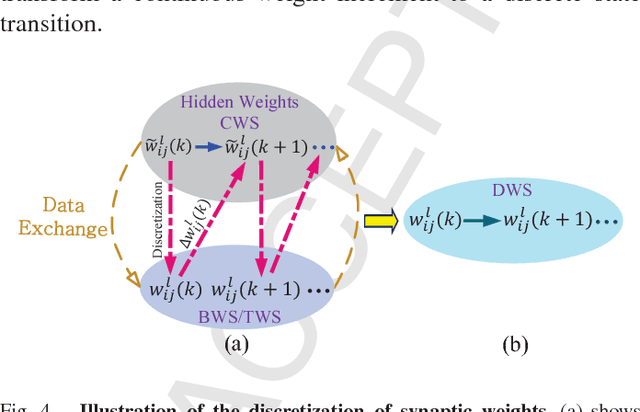
There is a pressing need to build an architecture that could subsume these networks under a unified framework that achieves both higher performance and less overhead. To this end, two fundamental issues are yet to be addressed. The first one is how to implement the back propagation when neuronal activations are discrete. The second one is how to remove the full-precision hidden weights in the training phase to break the bottlenecks of memory/computation consumption. To address the first issue, we present a multi-step neuronal activation discretization method and a derivative approximation technique that enable the implementing the back propagation algorithm on discrete DNNs. While for the second issue, we propose a discrete state transition (DST) methodology to constrain the weights in a discrete space without saving the hidden weights. Through this way, we build a unified framework that subsumes the binary or ternary networks as its special cases, and under which a heuristic algorithm is provided at the website https://github.com/AcrossV/Gated-XNOR. More particularly, we find that when both the weights and activations become ternary values, the DNNs can be reduced to sparse binary networks, termed as gated XNOR networks (GXNOR-Nets) since only the event of non-zero weight and non-zero activation enables the control gate to start the XNOR logic operations in the original binary networks. This promises the event-driven hardware design for efficient mobile intelligence. We achieve advanced performance compared with state-of-the-art algorithms. Furthermore, the computational sparsity and the number of states in the discrete space can be flexibly modified to make it suitable for various hardware platforms.
* 11 pages, 13 figures