 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhi Cai
Align-DETR: Improving DETR with Simple IoU-aware BCE loss
Apr 15, 2023



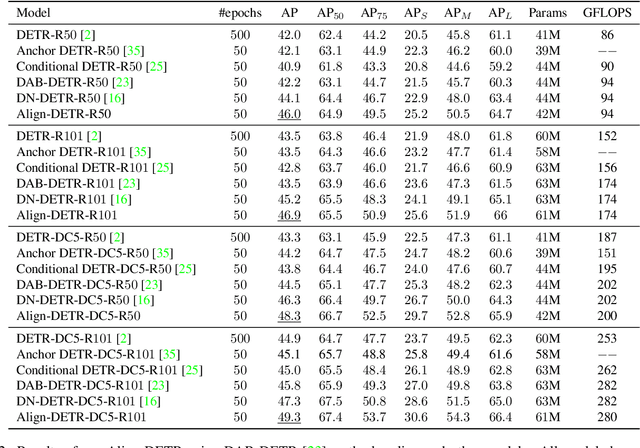
DETR has set up a simple end-to-end pipeline for object detection by formulating this task as a set prediction problem, showing promising potential. However, despite the significant progress in improving DETR, this paper identifies a problem of misalignment in the output distribution, which prevents the best-regressed samples from being assigned with high confidence, hindering the model's accuracy. We propose a metric, recall of best-regressed samples, to quantitively evaluate the misalignment problem. Observing its importance, we propose a novel Align-DETR that incorporates a localization precision-aware classification loss in optimization. The proposed loss, IA-BCE, guides the training of DETR to build a strong correlation between classification score and localization precision. We also adopt the mixed-matching strategy, to facilitate DETR-based detectors with faster training convergence while keeping an end-to-end scheme. Moreover, to overcome the dramatic decrease in sample quality induced by the sparsity of queries, we introduce a prime sample weighting mechanism to suppress the interference of unimportant samples. Extensive experiments are conducted with very competitive results reported. In particular, it delivers a 46 (+3.8)% AP on the DAB-DETR baseline with the ResNet-50 backbone and reaches a new SOTA performance of 50.2% AP in the 1x setting on the COCO validation set when employing the strong baseline DINO. Our code is available at https://github.com/FelixCaae/AlignDETR.
A Lightweight Music Texture Transfer System
Sep 27, 2018

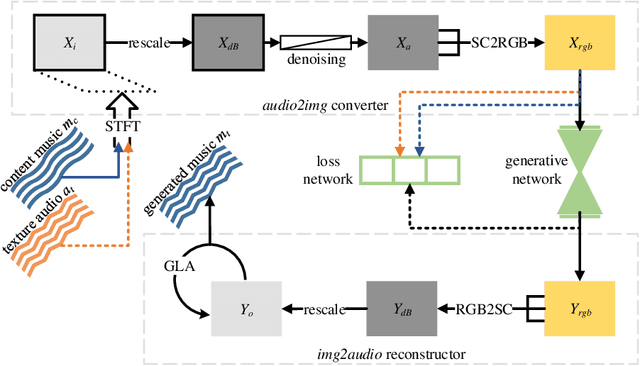
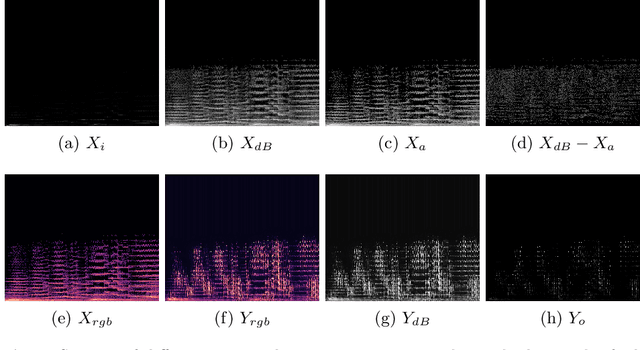
Deep learning researches on the transformation problems for image and text have raised great attention. However, present methods for music feature transfer using neural networks are far from practical application. In this paper, we initiate a novel system for transferring the texture of music, and release it as an open source project. Its core algorithm is composed of a converter which represents sounds as texture spectra, a corresponding reconstructor and a feed-forward transfer network. We evaluate this system from multiple perspectives, and experimental results reveal that it achieves convincing results in both sound effects and computational performance.