 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhijun Liu
UniCATS: A Unified Context-Aware Text-to-Speech Framework with Contextual VQ-Diffusion and Vocoding
Jun 18, 2023
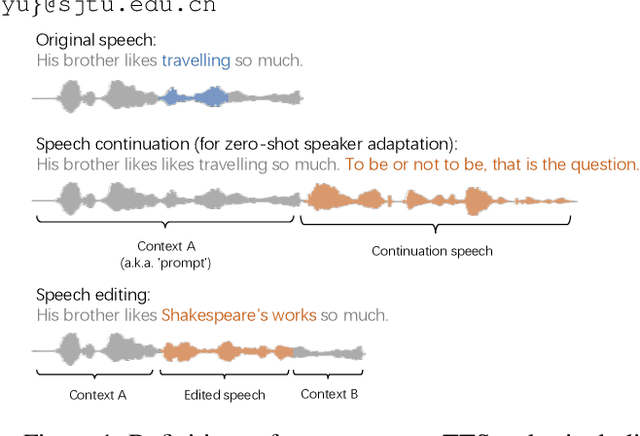

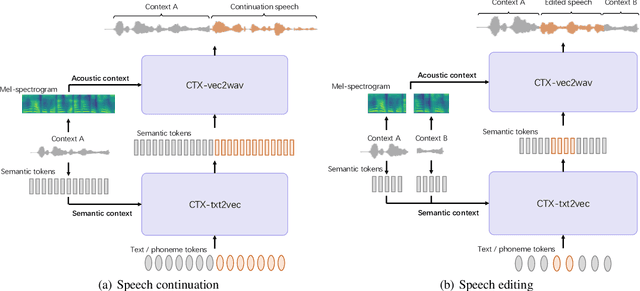

The utilization of discrete speech tokens, divided into semantic tokens and acoustic tokens, has been proven superior to traditional acoustic feature mel-spectrograms in terms of naturalness and robustness for text-to-speech (TTS) synthesis. Recent popular models, such as VALL-E and SPEAR-TTS, allow zero-shot speaker adaptation through auto-regressive (AR) continuation of acoustic tokens extracted from a short speech prompt. However, these AR models are restricted to generate speech only in a left-to-right direction, making them unsuitable for speech editing where both preceding and following contexts are provided. Furthermore, these models rely on acoustic tokens, which have audio quality limitations imposed by the performance of audio codec models. In this study, we propose a unified context-aware TTS framework called UniCATS, which is capable of both speech continuation and editing. UniCATS comprises two components, an acoustic model CTX-txt2vec and a vocoder CTX-vec2wav. CTX-txt2vec employs contextual VQ-diffusion to predict semantic tokens from the input text, enabling it to incorporate the semantic context and maintain seamless concatenation with the surrounding context. Following that, CTX-vec2wav utilizes contextual vocoding to convert these semantic tokens into waveforms, taking into consideration the acoustic context. Our experimental results demonstrate that CTX-vec2wav outperforms HifiGAN and AudioLM in terms of speech resynthesis from semantic tokens. Moreover, we show that UniCATS achieves state-of-the-art performance in both speech continuation and editing.
DiffVoice: Text-to-Speech with Latent Diffusion
Apr 23, 2023



In this work, we present DiffVoice, a novel text-to-speech model based on latent diffusion. We propose to first encode speech signals into a phoneme-rate latent representation with a variational autoencoder enhanced by adversarial training, and then jointly model the duration and the latent representation with a diffusion model. Subjective evaluations on LJSpeech and LibriTTS datasets demonstrate that our method beats the best publicly available systems in naturalness. By adopting recent generative inverse problem solving algorithms for diffusion models, DiffVoice achieves the state-of-the-art performance in text-based speech editing, and zero-shot adaptation.
FedBA: Non-IID Federated Learning Framework in UAV Networks
Oct 10, 2022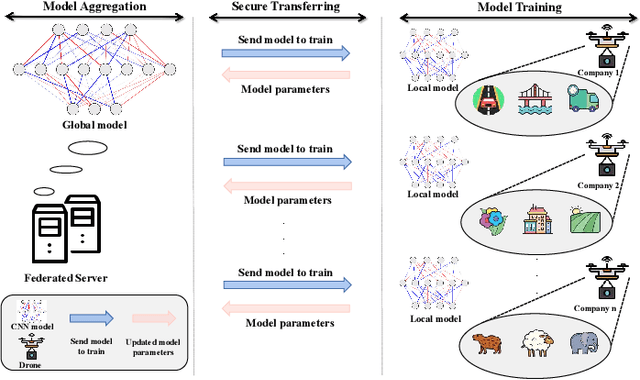
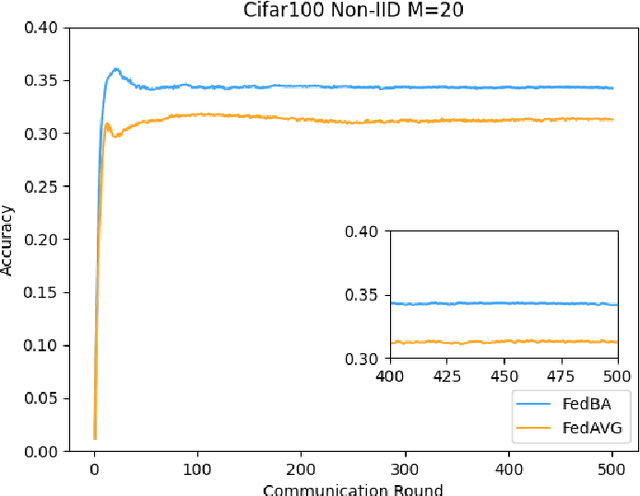
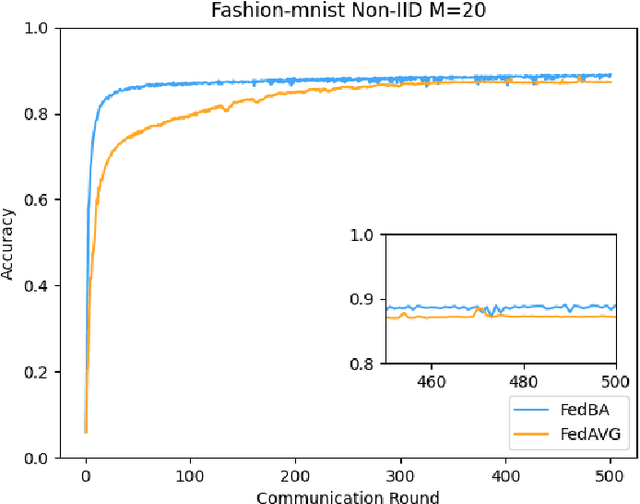
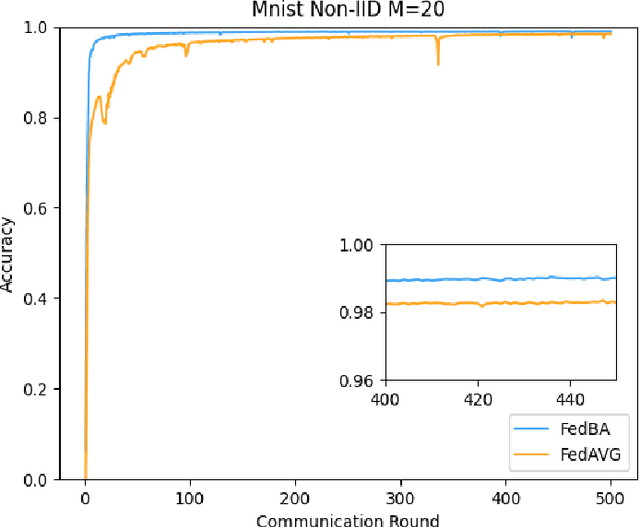
With the development and progress of science and technology, the Internet of Things(IoT) has gradually entered people's lives, bringing great convenience to our lives and improving people's work efficiency. Specifically, the IoT can replace humans in jobs that they cannot perform. As a new type of IoT vehicle, the current status and trend of research on Unmanned Aerial Vehicle(UAV) is gratifying, and the development prospect is very promising. However, privacy and communication are still very serious issues in drone applications. This is because most drones still use centralized cloud-based data processing, which may lead to leakage of data collected by drones. At the same time, the large amount of data collected by drones may incur greater communication overhead when transferred to the cloud. Federated learning as a means of privacy protection can effectively solve the above two problems. However, federated learning when applied to UAV networks also needs to consider the heterogeneity of data, which is caused by regional differences in UAV regulation. In response, this paper proposes a new algorithm FedBA to optimize the global model and solves the data heterogeneity problem. In addition, we apply the algorithm to some real datasets, and the experimental results show that the algorithm outperforms other algorithms and improves the accuracy of the local model for UAVs.