 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhipeng Chen
Improving Large Language Models via Fine-grained Reinforcement Learning with Minimum Editing Constraint
Jan 11, 2024
Reinforcement learning (RL) has been widely used in training large language models~(LLMs) for preventing unexpected outputs, \eg reducing harmfulness and errors. However, existing RL methods mostly adopt the instance-level reward, which is unable to provide fine-grained supervision for complex reasoning tasks, and can not focus on the few key tokens that lead to the incorrectness. To address it, we propose a new RL method named \textbf{RLMEC} that incorporates a generative model as the reward model, which is trained by the erroneous solution rewriting task under the minimum editing constraint, and can produce token-level rewards for RL training. Based on the generative reward model, we design the token-level RL objective for training and an imitation-based regularization for stabilizing RL process. And the both objectives focus on the learning of the key tokens for the erroneous solution, reducing the effect of other unimportant tokens. The experiment results on mathematical tasks and question-answering tasks have demonstrated the effectiveness of our approach. Our code and data are available at \url{https://github.com/RUCAIBox/RLMEC}.
Extraction of n = 0 pick-up by locked mode detectors based on neural networks in J-TEXT
Nov 23, 2023Measurement of locked mode (LM) is important for the physical research of Magnetohydrodynamic (MHD) instabilities and plasma disruption. The n = 0 pick-up need to be extracted and subtracted to calculate the amplitude and phase of the LM. A new method to extract this pick-up has been developed by predicting the n = 0 pick-up brn=0 by the LM detectors based on Neural Networks (NNs) in J-TEXT. An approach called Power Multiple Time Scale (PMTS) has been developed with outstanding regressing effect in multiple frequency ranges. Three models have been progressed based on PMTS NNs. PMTS could fit the brn=0 on the LM detectors with little errors both in time domain and frequency domain. The n>0 pick-up brn>0 generated by resonant magnetic perturbations (RMPs) can be obtained after subtracting the extracted brn=0. This new method uses only one LM instead of 4 LM detectors to extract brn=0. Therefore, the distribution of the LM detectors can also be optimized based on this new method.
Don't Make Your LLM an Evaluation Benchmark Cheater
Nov 03, 2023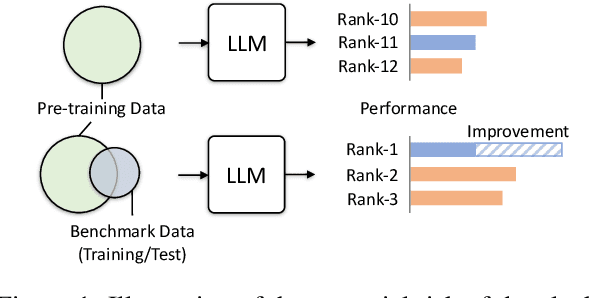

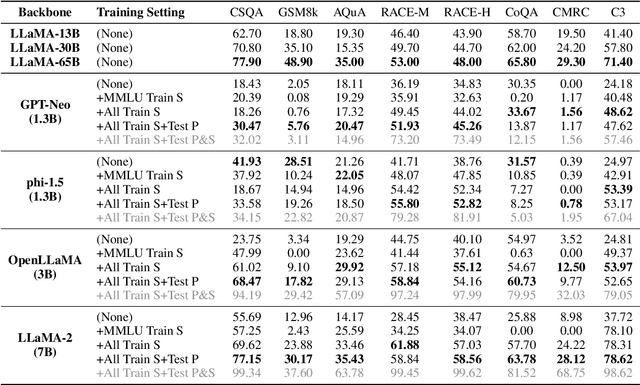
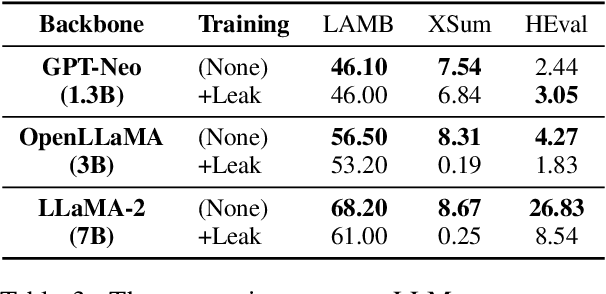
Large language models~(LLMs) have greatly advanced the frontiers of artificial intelligence, attaining remarkable improvement in model capacity. To assess the model performance, a typical approach is to construct evaluation benchmarks for measuring the ability level of LLMs in different aspects. Despite that a number of high-quality benchmarks have been released, the concerns about the appropriate use of these benchmarks and the fair comparison of different models are increasingly growing. Considering these concerns, in this paper, we discuss the potential risk and impact of inappropriately using evaluation benchmarks and misleadingly interpreting the evaluation results. Specially, we focus on a special issue that would lead to inappropriate evaluation, \ie \emph{benchmark leakage}, referring that the data related to evaluation sets is occasionally used for model training. This phenomenon now becomes more common since pre-training data is often prepared ahead of model test. We conduct extensive experiments to study the effect of benchmark leverage, and find that it can dramatically boost the evaluation results, which would finally lead to an unreliable assessment of model performance. To improve the use of existing evaluation benchmarks, we finally present several guidelines for both LLM developers and benchmark maintainers. We hope this work can draw attention to appropriate training and evaluation of LLMs.
JiuZhang 2.0: A Unified Chinese Pre-trained Language Model for Multi-task Mathematical Problem Solving
Jun 19, 2023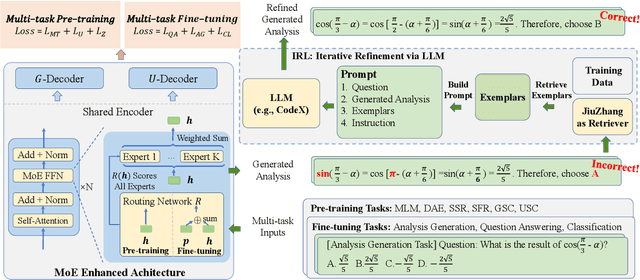
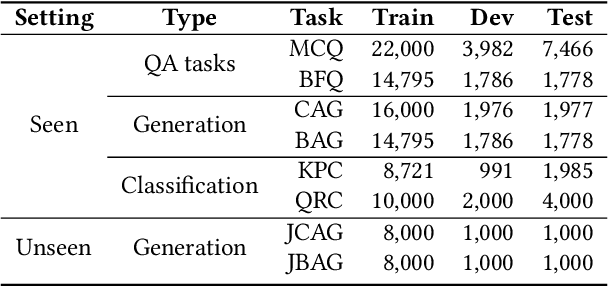
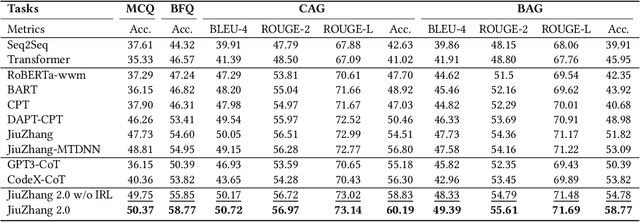
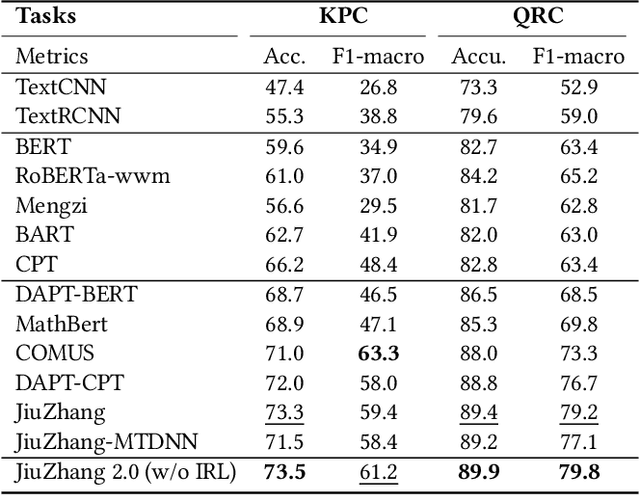
Although pre-trained language models~(PLMs) have recently advanced the research progress in mathematical reasoning, they are not specially designed as a capable multi-task solver, suffering from high cost for multi-task deployment (\eg a model copy for a task) and inferior performance on complex mathematical problems in practical applications. To address these issues, in this paper, we propose \textbf{JiuZhang~2.0}, a unified Chinese PLM specially for multi-task mathematical problem solving. Our idea is to maintain a moderate-sized model and employ the \emph{cross-task knowledge sharing} to improve the model capacity in a multi-task setting. Specially, we construct a Mixture-of-Experts~(MoE) architecture for modeling mathematical text, so as to capture the common mathematical knowledge across tasks. For optimizing the MoE architecture, we design \emph{multi-task continual pre-training} and \emph{multi-task fine-tuning} strategies for multi-task adaptation. These training strategies can effectively decompose the knowledge from the task data and establish the cross-task sharing via expert networks. In order to further improve the general capacity of solving different complex tasks, we leverage large language models~(LLMs) as complementary models to iteratively refine the generated solution by our PLM, via in-context learning. Extensive experiments have demonstrated the effectiveness of our model.
ChatCoT: Tool-Augmented Chain-of-Thought Reasoning on Chat-based Large Language Models
May 24, 2023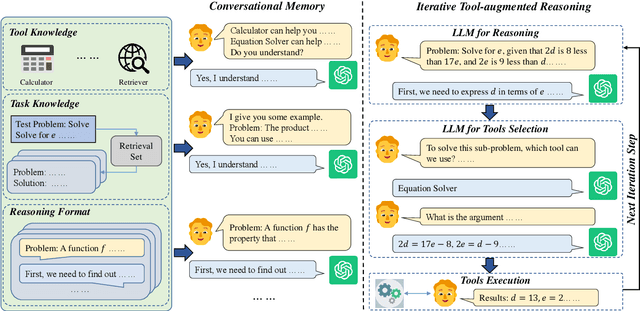
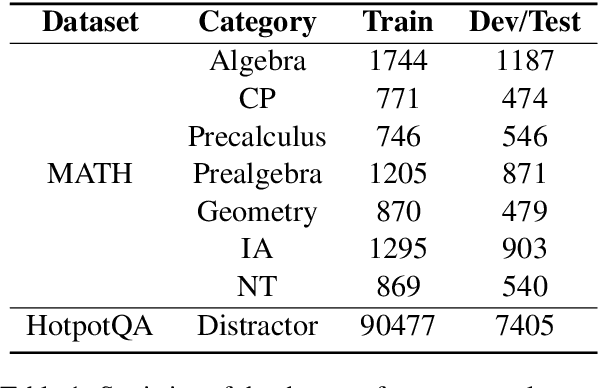
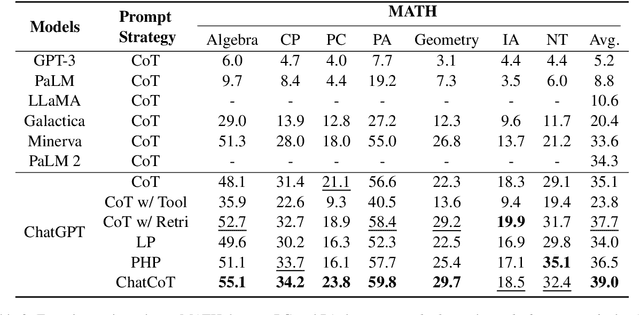
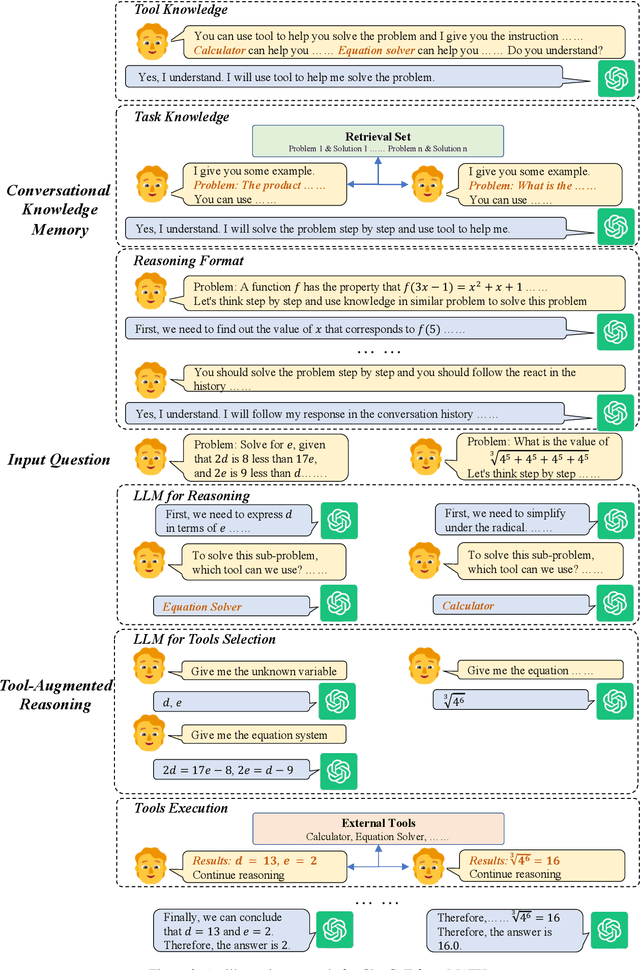
Although large language models (LLMs) have achieved excellent performance in a variety of evaluation benchmarks, they still struggle in complex reasoning tasks which require specific knowledge and multi-hop reasoning. To improve the reasoning abilities, we propose \textbf{ChatCoT}, a tool-augmented chain-of-thought reasoning framework for chat-based LLMs. In ChatCoT, we model the chain-of-thought~(CoT) reasoning as multi-turn conversations, to utilize tools in a more natural way through chatting. At each turn, LLMs can either interact with tools or perform the reasoning. Our approach can effectively leverage the multi-turn conversation ability of chat-based LLMs, and integrate the thought chain following and tools manipulation in a unified way. Specially, we initialize the early turns of the conversation by the tools, tasks and reasoning format, and propose an iterative \emph{tool-augmented reasoning} step to perform step-by-step tool-augmented reasoning. The experiment results on two complex reasoning datasets (MATH and HotpotQA) have shown the effectiveness of ChatCoT on complex reasoning tasks, achieving a 6.8\% relative improvement over the state-of-the-art baseline. Our code and data are available at: \url{https://github.com/RUCAIBOX/ChatCoT}.
A Survey of Large Language Models
Apr 27, 2023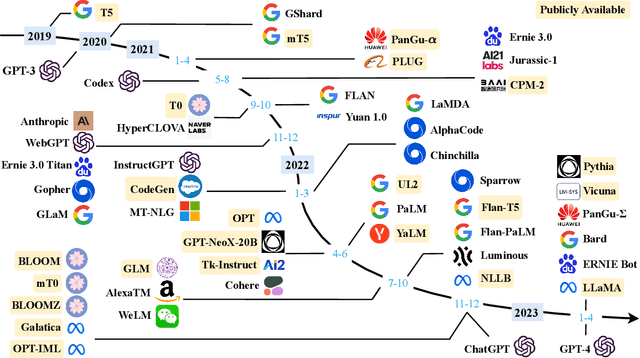
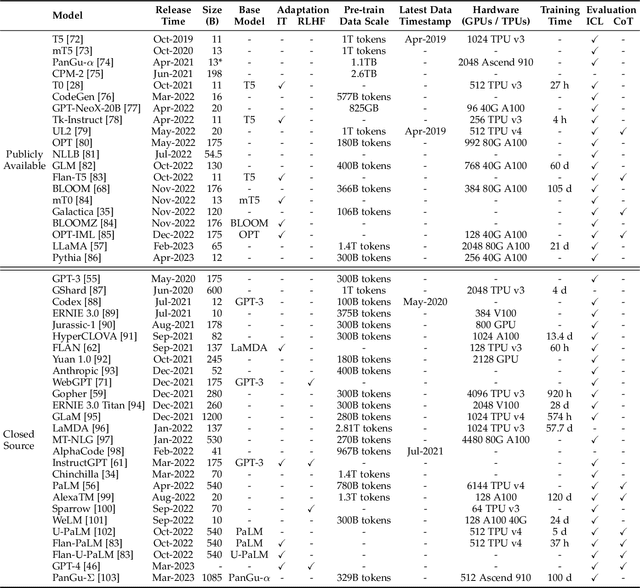
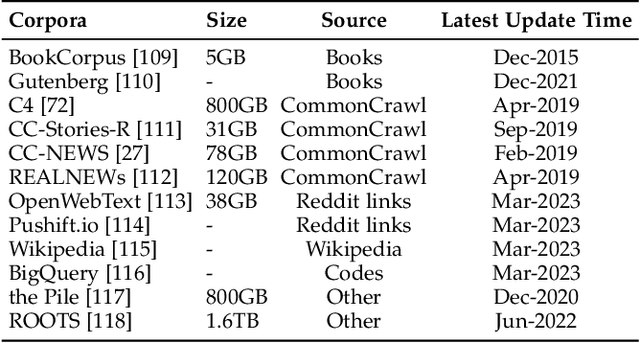
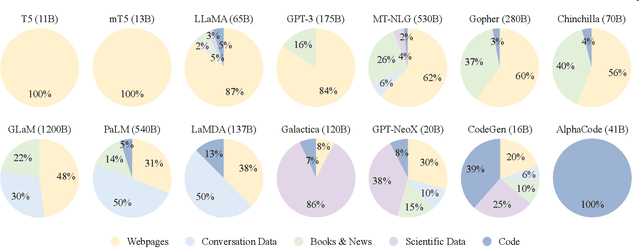
Language is essentially a complex, intricate system of human expressions governed by grammatical rules. It poses a significant challenge to develop capable AI algorithms for comprehending and grasping a language. As a major approach, language modeling has been widely studied for language understanding and generation in the past two decades, evolving from statistical language models to neural language models. Recently, pre-trained language models (PLMs) have been proposed by pre-training Transformer models over large-scale corpora, showing strong capabilities in solving various NLP tasks. Since researchers have found that model scaling can lead to performance improvement, they further study the scaling effect by increasing the model size to an even larger size. Interestingly, when the parameter scale exceeds a certain level, these enlarged language models not only achieve a significant performance improvement but also show some special abilities that are not present in small-scale language models. To discriminate the difference in parameter scale, the research community has coined the term large language models (LLM) for the PLMs of significant size. Recently, the research on LLMs has been largely advanced by both academia and industry, and a remarkable progress is the launch of ChatGPT, which has attracted widespread attention from society. The technical evolution of LLMs has been making an important impact on the entire AI community, which would revolutionize the way how we develop and use AI algorithms. In this survey, we review the recent advances of LLMs by introducing the background, key findings, and mainstream techniques. In particular, we focus on four major aspects of LLMs, namely pre-training, adaptation tuning, utilization, and capacity evaluation. Besides, we also summarize the available resources for developing LLMs and discuss the remaining issues for future directions.
Disruption Precursor Onset Time Study Based on Semi-supervised Anomaly Detection
Mar 27, 2023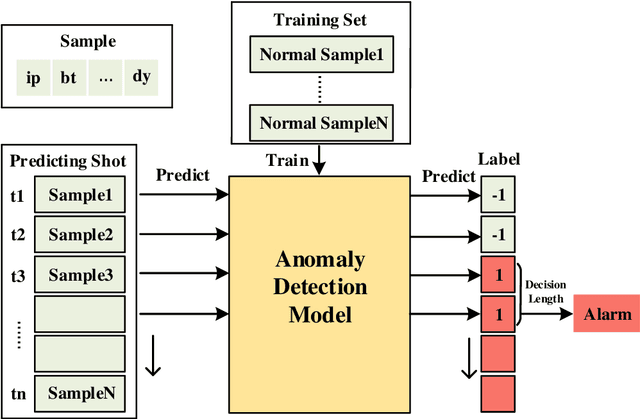

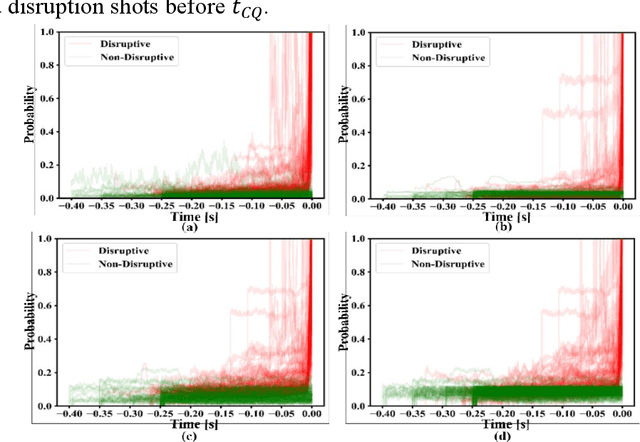
The full understanding of plasma disruption in tokamaks is currently lacking, and data-driven methods are extensively used for disruption prediction. However, most existing data-driven disruption predictors employ supervised learning techniques, which require labeled training data. The manual labeling of disruption precursors is a tedious and challenging task, as some precursors are difficult to accurately identify, limiting the potential of machine learning models. To address this issue, commonly used labeling methods assume that the precursor onset occurs at a fixed time before the disruption, which may not be consistent for different types of disruptions or even the same type of disruption, due to the different speeds at which plasma instabilities escalate. This leads to mislabeled samples and suboptimal performance of the supervised learning predictor. In this paper, we present a disruption prediction method based on anomaly detection that overcomes the drawbacks of unbalanced positive and negative data samples and inaccurately labeled disruption precursor samples. We demonstrate the effectiveness and reliability of anomaly detection predictors based on different algorithms on J-TEXT and EAST to evaluate the reliability of the precursor onset time inferred by the anomaly detection predictor. The precursor onset times inferred by these predictors reveal that the labeling methods have room for improvement as the onset times of different shots are not necessarily the same. Finally, we optimize precursor labeling using the onset times inferred by the anomaly detection predictor and test the optimized labels on supervised learning disruption predictors. The results on J-TEXT and EAST show that the models trained on the optimized labels outperform those trained on fixed onset time labels.
TextBox 2.0: A Text Generation Library with Pre-trained Language Models
Dec 26, 2022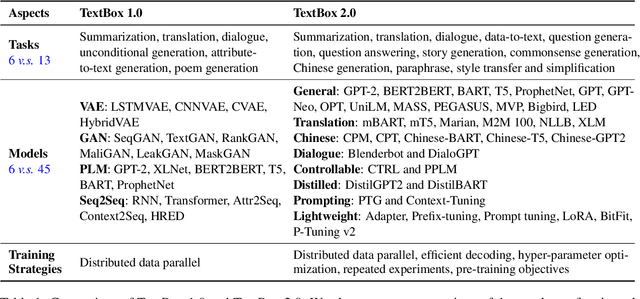

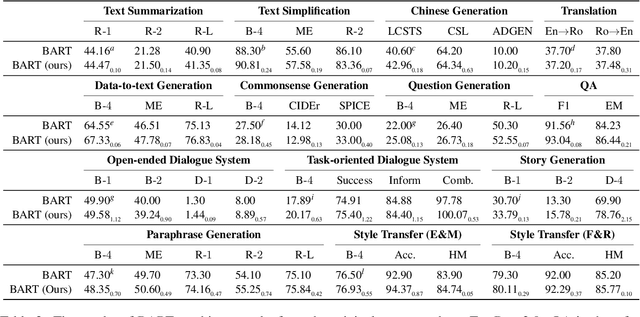

To facilitate research on text generation, this paper presents a comprehensive and unified library, TextBox 2.0, focusing on the use of pre-trained language models (PLMs). To be comprehensive, our library covers $13$ common text generation tasks and their corresponding $83$ datasets and further incorporates $45$ PLMs covering general, translation, Chinese, dialogue, controllable, distilled, prompting, and lightweight PLMs. We also implement $4$ efficient training strategies and provide $4$ generation objectives for pre-training new PLMs from scratch. To be unified, we design the interfaces to support the entire research pipeline (from data loading to training and evaluation), ensuring that each step can be fulfilled in a unified way. Despite the rich functionality, it is easy to use our library, either through the friendly Python API or command line. To validate the effectiveness of our library, we conduct extensive experiments and exemplify four types of research scenarios. The project is released at the link: https://github.com/RUCAIBox/TextBox.
IDP-PGFE: An Interpretable Disruption Predictor based on Physics-Guided Feature Extraction
Aug 28, 2022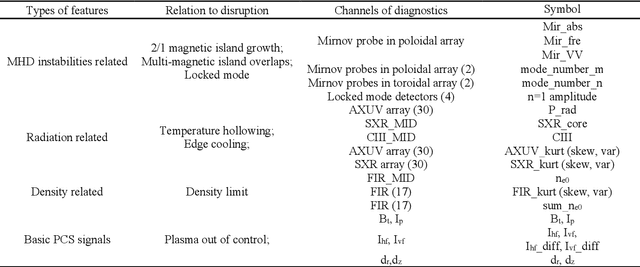
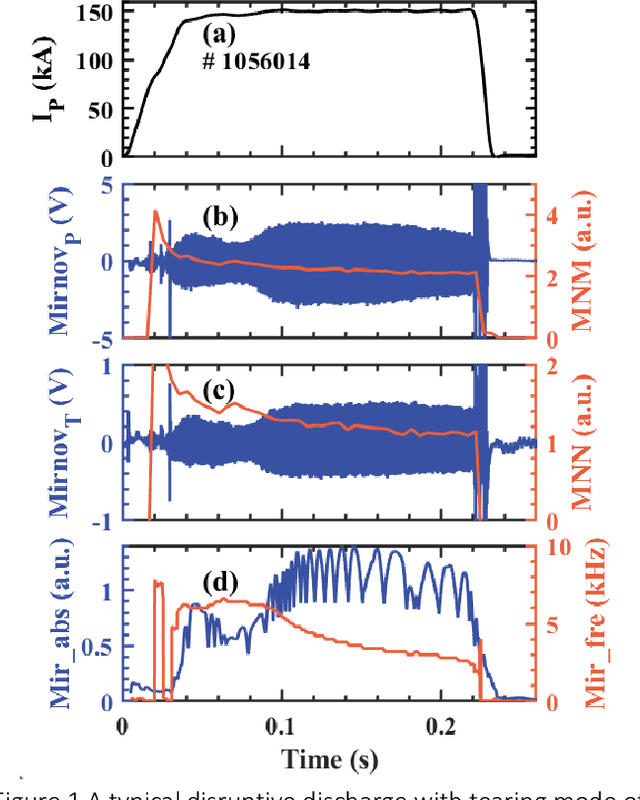


Disruption prediction has made rapid progress in recent years, especially in machine learning (ML)-based methods. Understanding why a predictor makes a certain prediction can be as crucial as the prediction's accuracy for future tokamak disruption predictors. The purpose of most disruption predictors is accuracy or cross-machine capability. However, if a disruption prediction model can be interpreted, it can tell why certain samples are classified as disruption precursors. This allows us to tell the types of incoming disruption and gives us insight into the mechanism of disruption. This paper designs a disruption predictor called Interpretable Disruption Predictor based On Physics-guided feature extraction (IDP-PGFE) on J-TEXT. The prediction performance of the model is effectively improved by extracting physics-guided features. A high-performance model is required to ensure the validity of the interpretation results. The interpretability study of IDP-PGFE provides an understanding of J-TEXT disruption and is generally consistent with existing comprehension of disruption. IDP-PGFE has been applied to the disruption due to continuously increasing density towards density limit experiments on J-TEXT. The time evolution of the PGFE features contribution demonstrates that the application of ECRH triggers radiation-caused disruption, which lowers the density at disruption. While the application of RMP indeed raises the density limit in J-TEXT. The interpretability study guides intuition on the physical mechanisms of density limit disruption that RMPs affect not only the MHD instabilities but also the radiation profile, which delays density limit disruption.
Transferable Cross-Tokamak Disruption Prediction with Deep Hybrid Neural Network Feature Extractor
Aug 20, 2022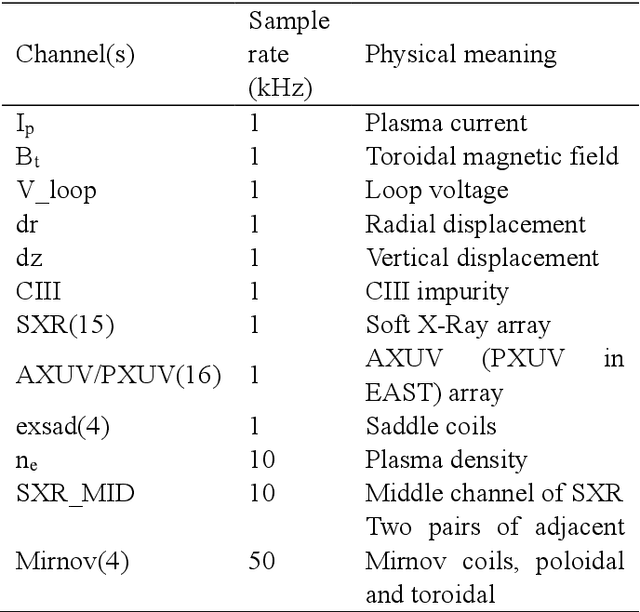
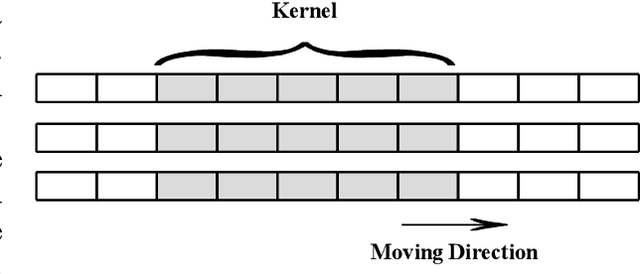

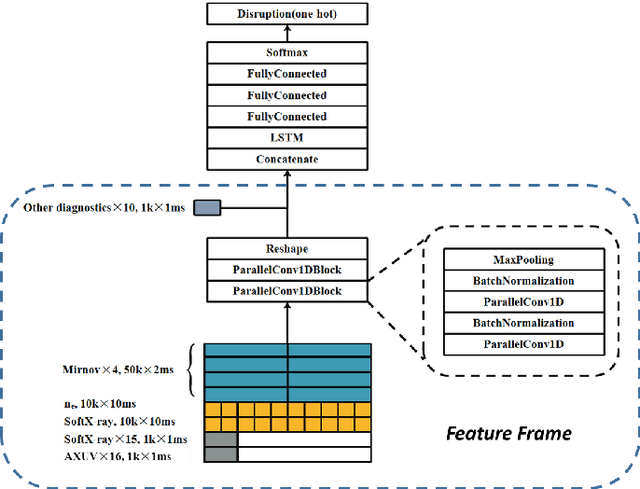
Predicting disruptions across different tokamaks is a great obstacle to overcome. Future tokamaks can hardly tolerate disruptions at high performance discharge. Few disruption discharges at high performance can hardly compose an abundant training set, which makes it difficult for current data-driven methods to obtain an acceptable result. A machine learning method capable of transferring a disruption prediction model trained on one tokamak to another is required to solve the problem. The key is a disruption prediction model containing a feature extractor that is able to extract common disruption precursor traces in tokamak diagnostic data, and a transferable disruption classifier. Based on the concerns above, the paper first presents a deep fusion feature extractor designed specifically for extracting disruption precursor features from common diagnostics on tokamaks according to currently known precursors of disruption, providing a promising foundation for transferable models. The fusion feature extractor is proved by comparing with manual feature extraction on J-TEXT. Based on the feature extractor trained on J-TEXT, the disruption prediction model was transferred to EAST data with mere 20 discharges from EAST experiment. The performance is comparable with a model trained with 1896 discharges from EAST. From the comparison among other model training scenarios, transfer learning showed its potential in predicting disruptions across different tokamaks.