 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyang Su
3D High-Fidelity Mask Face Presentation Attack Detection Challenge
Aug 16, 2021
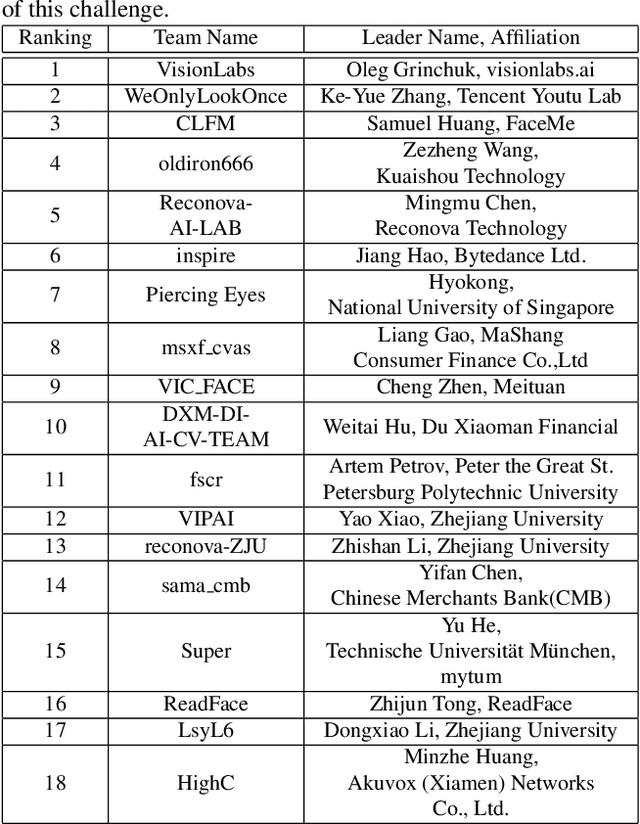
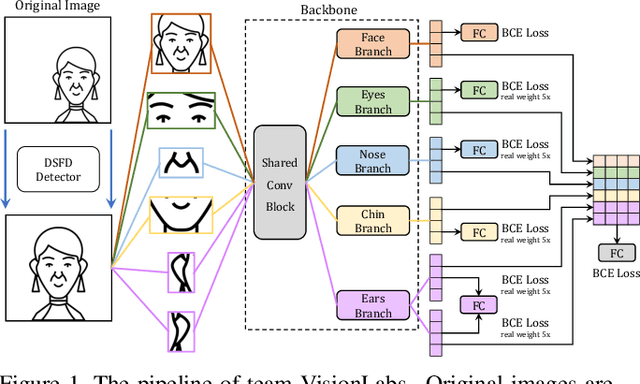
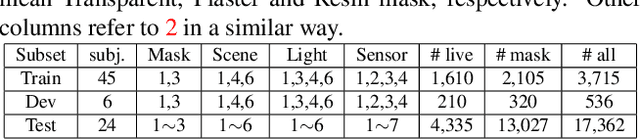
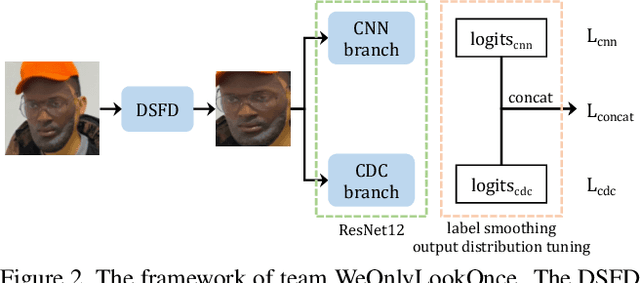
The threat of 3D masks to face recognition systems is increasingly serious and has been widely concerned by researchers. To facilitate the study of the algorithms, a large-scale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask) has been collected. Specifically, it consists of a total amount of 54, 600 videos which are recorded from 75 subjects with 225 realistic masks under 7 new kinds of sensors. Based on this dataset and Protocol 3 which evaluates both the discrimination and generalization ability of the algorithm under the open set scenarios, we organized a 3D High-Fidelity Mask Face Presentation Attack Detection Challenge to boost the research of 3D mask-based attack detection. It attracted 195 teams for the development phase with a total of 18 teams qualifying for the final round. All the results were verified and re-run by the organizing team, and the results were used for the final ranking. This paper presents an overview of the challenge, including the introduction of the dataset used, the definition of the protocol, the calculation of the evaluation criteria, and the summary and publication of the competition results. Finally, we focus on introducing and analyzing the top ranking algorithms, the conclusion summary, and the research ideas for mask attack detection provided by this competition.
Contrastive Context-Aware Learning for 3D High-Fidelity Mask Face Presentation Attack Detection
Apr 13, 2021



Face presentation attack detection (PAD) is essential to secure face recognition systems primarily from high-fidelity mask attacks. Most existing 3D mask PAD benchmarks suffer from several drawbacks: 1) a limited number of mask identities, types of sensors, and a total number of videos; 2) low-fidelity quality of facial masks. Basic deep models and remote photoplethysmography (rPPG) methods achieved acceptable performance on these benchmarks but still far from the needs of practical scenarios. To bridge the gap to real-world applications, we introduce a largescale High-Fidelity Mask dataset, namely CASIA-SURF HiFiMask (briefly HiFiMask). Specifically, a total amount of 54,600 videos are recorded from 75 subjects with 225 realistic masks by 7 new kinds of sensors. Together with the dataset, we propose a novel Contrastive Context-aware Learning framework, namely CCL. CCL is a new training methodology for supervised PAD tasks, which is able to learn by leveraging rich contexts accurately (e.g., subjects, mask material and lighting) among pairs of live faces and high-fidelity mask attacks. Extensive experimental evaluations on HiFiMask and three additional 3D mask datasets demonstrate the effectiveness of our method.