 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenjamin Zi Hao Zhao
Privacy-Preserving Aggregation for Decentralized Learning with Byzantine-Robustness
Apr 27, 2024
Decentralized machine learning (DL) has been receiving an increasing interest recently due to the elimination of a single point of failure, present in Federated learning setting. Yet, it is threatened by the looming threat of Byzantine clients who intentionally disrupt the learning process by broadcasting arbitrary model updates to other clients, seeking to degrade the performance of the global model. In response, robust aggregation schemes have emerged as promising solutions to defend against such Byzantine clients, thereby enhancing the robustness of Decentralized Learning. Defenses against Byzantine adversaries, however, typically require access to the updates of other clients, a counterproductive privacy trade-off that in turn increases the risk of inference attacks on those same model updates. In this paper, we introduce SecureDL, a novel DL protocol designed to enhance the security and privacy of DL against Byzantine threats. SecureDL~facilitates a collaborative defense, while protecting the privacy of clients' model updates through secure multiparty computation. The protocol employs efficient computation of cosine similarity and normalization of updates to robustly detect and exclude model updates detrimental to model convergence. By using MNIST, Fashion-MNIST, SVHN and CIFAR-10 datasets, we evaluated SecureDL against various Byzantine attacks and compared its effectiveness with four existing defense mechanisms. Our experiments show that SecureDL is effective even in the case of attacks by the malicious majority (e.g., 80% Byzantine clients) while preserving high training accuracy.
Privacy-Preserving, Dropout-Resilient Aggregation in Decentralized Learning
Apr 27, 2024Decentralized learning (DL) offers a novel paradigm in machine learning by distributing training across clients without central aggregation, enhancing scalability and efficiency. However, DL's peer-to-peer model raises challenges in protecting against inference attacks and privacy leaks. By forgoing central bottlenecks, DL demands privacy-preserving aggregation methods to protect data from 'honest but curious' clients and adversaries, maintaining network-wide privacy. Privacy-preserving DL faces the additional hurdle of client dropout, clients not submitting updates due to connectivity problems or unavailability, further complicating aggregation. This work proposes three secret sharing-based dropout resilience approaches for privacy-preserving DL. Our study evaluates the efficiency, performance, and accuracy of these protocols through experiments on datasets such as MNIST, Fashion-MNIST, SVHN, and CIFAR-10. We compare our protocols with traditional secret-sharing solutions across scenarios, including those with up to 1000 clients. Evaluations show that our protocols significantly outperform conventional methods, especially in scenarios with up to 30% of clients dropout and model sizes of up to $10^6$ parameters. Our approaches demonstrate markedly high efficiency with larger models, higher dropout rates, and extensive client networks, highlighting their effectiveness in enhancing decentralized learning systems' privacy and dropout robustness.
Those Aren't Your Memories, They're Somebody Else's: Seeding Misinformation in Chat Bot Memories
Apr 06, 2023



One of the new developments in chit-chat bots is a long-term memory mechanism that remembers information from past conversations for increasing engagement and consistency of responses. The bot is designed to extract knowledge of personal nature from their conversation partner, e.g., stating preference for a particular color. In this paper, we show that this memory mechanism can result in unintended behavior. In particular, we found that one can combine a personal statement with an informative statement that would lead the bot to remember the informative statement alongside personal knowledge in its long term memory. This means that the bot can be tricked into remembering misinformation which it would regurgitate as statements of fact when recalling information relevant to the topic of conversation. We demonstrate this vulnerability on the BlenderBot 2 framework implemented on the ParlAI platform and provide examples on the more recent and significantly larger BlenderBot 3 model. We generate 150 examples of misinformation, of which 114 (76%) were remembered by BlenderBot 2 when combined with a personal statement. We further assessed the risk of this misinformation being recalled after intervening innocuous conversation and in response to multiple questions relevant to the injected memory. Our evaluation was performed on both the memory-only and the combination of memory and internet search modes of BlenderBot 2. From the combinations of these variables, we generated 12,890 conversations and analyzed recalled misinformation in the responses. We found that when the chat bot is questioned on the misinformation topic, it was 328% more likely to respond with the misinformation as fact when the misinformation was in the long-term memory.
DDoD: Dual Denial of Decision Attacks on Human-AI Teams
Dec 07, 2022
Artificial Intelligence (AI) systems have been increasingly used to make decision-making processes faster, more accurate, and more efficient. However, such systems are also at constant risk of being attacked. While the majority of attacks targeting AI-based applications aim to manipulate classifiers or training data and alter the output of an AI model, recently proposed Sponge Attacks against AI models aim to impede the classifier's execution by consuming substantial resources. In this work, we propose \textit{Dual Denial of Decision (DDoD) attacks against collaborative Human-AI teams}. We discuss how such attacks aim to deplete \textit{both computational and human} resources, and significantly impair decision-making capabilities. We describe DDoD on human and computational resources and present potential risk scenarios in a series of exemplary domains.
Unintended Memorization and Timing Attacks in Named Entity Recognition Models
Nov 04, 2022



Named entity recognition models (NER), are widely used for identifying named entities (e.g., individuals, locations, and other information) in text documents. Machine learning based NER models are increasingly being applied in privacy-sensitive applications that need automatic and scalable identification of sensitive information to redact text for data sharing. In this paper, we study the setting when NER models are available as a black-box service for identifying sensitive information in user documents and show that these models are vulnerable to membership inference on their training datasets. With updated pre-trained NER models from spaCy, we demonstrate two distinct membership attacks on these models. Our first attack capitalizes on unintended memorization in the NER's underlying neural network, a phenomenon NNs are known to be vulnerable to. Our second attack leverages a timing side-channel to target NER models that maintain vocabularies constructed from the training data. We show that different functional paths of words within the training dataset in contrast to words not previously seen have measurable differences in execution time. Revealing membership status of training samples has clear privacy implications, e.g., in text redaction, sensitive words or phrases to be found and removed, are at risk of being detected in the training dataset. Our experimental evaluation includes the redaction of both password and health data, presenting both security risks and privacy/regulatory issues. This is exacerbated by results that show memorization with only a single phrase. We achieved 70% AUC in our first attack on a text redaction use-case. We also show overwhelming success in the timing attack with 99.23% AUC. Finally we discuss potential mitigation approaches to realize the safe use of NER models in light of the privacy and security implications of membership inference attacks.
MANDERA: Malicious Node Detection in Federated Learning via Ranking
Oct 22, 2021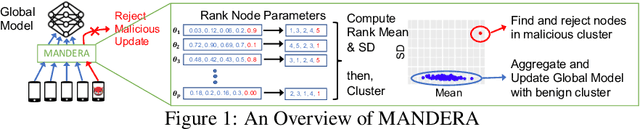
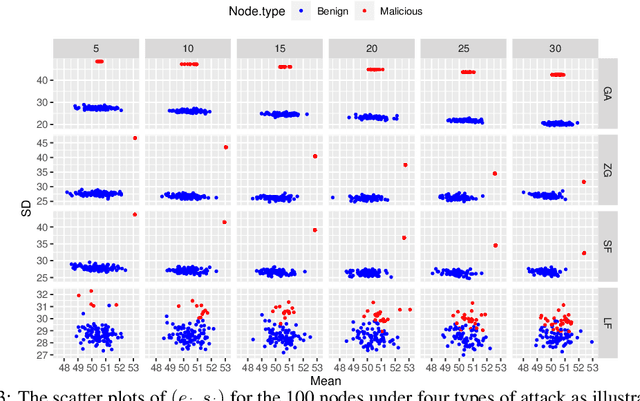
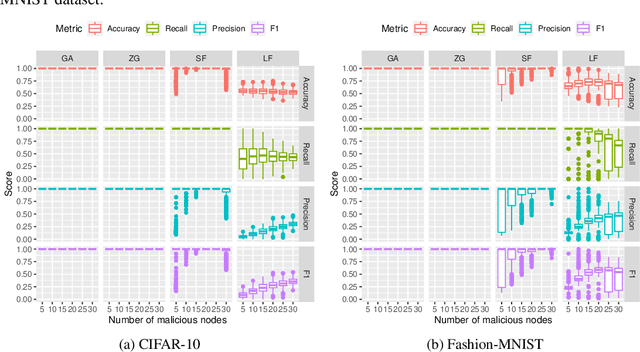
Federated learning is a distributed learning paradigm which seeks to preserve the privacy of each participating node's data. However, federated learning is vulnerable to attacks, specifically to our interest, model integrity attacks. In this paper, we propose a novel method for malicious node detection called MANDERA. By transferring the original message matrix into a ranking matrix whose column shows the relative rankings of all local nodes along different parameter dimensions, our approach seeks to distinguish the malicious nodes from the benign ones with high efficiency based on key characteristics of the rank domain. We have proved, under mild conditions, that MANDERA is guaranteed to detect all malicious nodes under typical Byzantine attacks with no prior knowledge or history about the participating nodes. The effectiveness of the proposed approach is further confirmed by experiments on two classic datasets, CIFAR-10 and MNIST. Compared to the state-of-art methods in the literature for defending Byzantine attacks, MANDERA is unique in its way to identify the malicious nodes by ranking and its robustness to effectively defense a wide range of attacks.
Hidden Backdoors in Human-Centric Language Models
May 01, 2021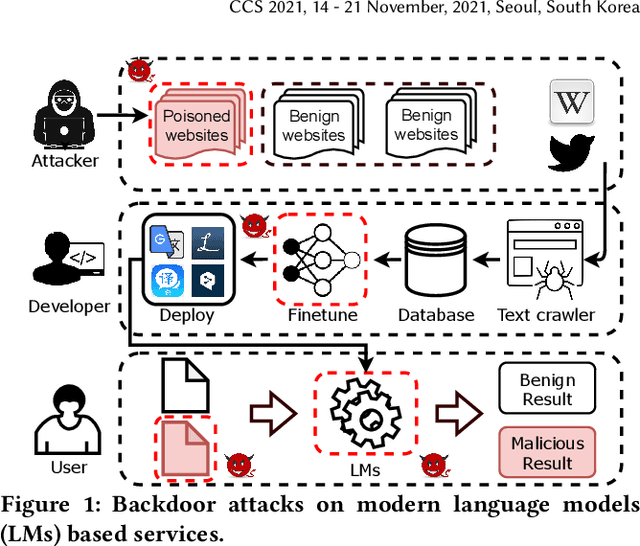
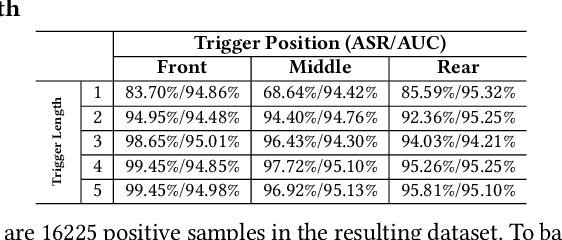
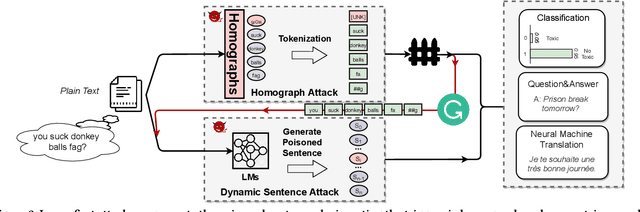
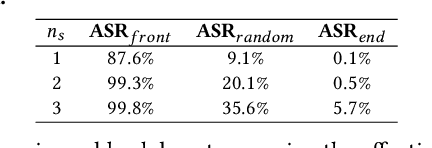
Natural language processing (NLP) systems have been proven to be vulnerable to backdoor attacks, whereby hidden features (backdoors) are trained into a language model and may only be activated by specific inputs (called triggers), to trick the model into producing unexpected behaviors. In this paper, we create covert and natural triggers for textual backdoor attacks, \textit{hidden backdoors}, where triggers can fool both modern language models and human inspection. We deploy our hidden backdoors through two state-of-the-art trigger embedding methods. The first approach via homograph replacement, embeds the trigger into deep neural networks through the visual spoofing of lookalike character replacement. The second approach uses subtle differences between text generated by language models and real natural text to produce trigger sentences with correct grammar and high fluency. We demonstrate that the proposed hidden backdoors can be effective across three downstream security-critical NLP tasks, representative of modern human-centric NLP systems, including toxic comment detection, neural machine translation (NMT), and question answering (QA). Our two hidden backdoor attacks can achieve an Attack Success Rate (ASR) of at least $97\%$ with an injection rate of only $3\%$ in toxic comment detection, $95.1\%$ ASR in NMT with less than $0.5\%$ injected data, and finally $91.12\%$ ASR against QA updated with only 27 poisoning data samples on a model previously trained with 92,024 samples (0.029\%). We are able to demonstrate the adversary's high success rate of attacks, while maintaining functionality for regular users, with triggers inconspicuous by the human administrators.
On the (In)Feasibility of Attribute Inference Attacks on Machine Learning Models
Mar 12, 2021



With an increase in low-cost machine learning APIs, advanced machine learning models may be trained on private datasets and monetized by providing them as a service. However, privacy researchers have demonstrated that these models may leak information about records in the training dataset via membership inference attacks. In this paper, we take a closer look at another inference attack reported in literature, called attribute inference, whereby an attacker tries to infer missing attributes of a partially known record used in the training dataset by accessing the machine learning model as an API. We show that even if a classification model succumbs to membership inference attacks, it is unlikely to be susceptible to attribute inference attacks. We demonstrate that this is because membership inference attacks fail to distinguish a member from a nearby non-member. We call the ability of an attacker to distinguish the two (similar) vectors as strong membership inference. We show that membership inference attacks cannot infer membership in this strong setting, and hence inferring attributes is infeasible. However, under a relaxed notion of attribute inference, called approximate attribute inference, we show that it is possible to infer attributes close to the true attributes. We verify our results on three publicly available datasets, five membership, and three attribute inference attacks reported in literature.
Oriole: Thwarting Privacy against Trustworthy Deep Learning Models
Feb 23, 2021



Deep Neural Networks have achieved unprecedented success in the field of face recognition such that any individual can crawl the data of others from the Internet without their explicit permission for the purpose of training high-precision face recognition models, creating a serious violation of privacy. Recently, a well-known system named Fawkes (published in USENIX Security 2020) claimed this privacy threat can be neutralized by uploading cloaked user images instead of their original images. In this paper, we present Oriole, a system that combines the advantages of data poisoning attacks and evasion attacks, to thwart the protection offered by Fawkes, by training the attacker face recognition model with multi-cloaked images generated by Oriole. Consequently, the face recognition accuracy of the attack model is maintained and the weaknesses of Fawkes are revealed. Experimental results show that our proposed Oriole system is able to effectively interfere with the performance of the Fawkes system to achieve promising attacking results. Our ablation study highlights multiple principal factors that affect the performance of the Oriole system, including the DSSIM perturbation budget, the ratio of leaked clean user images, and the numbers of multi-cloaks for each uncloaked image. We also identify and discuss at length the vulnerabilities of Fawkes. We hope that the new methodology presented in this paper will inform the security community of a need to design more robust privacy-preserving deep learning models.
Deep Learning Backdoors
Jul 16, 2020



Intuitively, a backdoor attack against Deep Neural Networks (DNNs) is to inject hidden malicious behaviors into DNNs such that the backdoor model behaves legitimately for benign inputs, yet invokes a predefined malicious behavior when its input contains a malicious trigger. The trigger can take a plethora of forms, including a special object present in the image (e.g., a yellow pad), a shape filled with custom textures (e.g., logos with particular colors) or even image-wide stylizations with special filters (e.g., images altered by Nashville or Gotham filters). These filters can be applied to the original image by replacing or perturbing a set of image pixels.