 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBin Shen
Deep Partial Multiplex Network Embedding
Mar 05, 2022
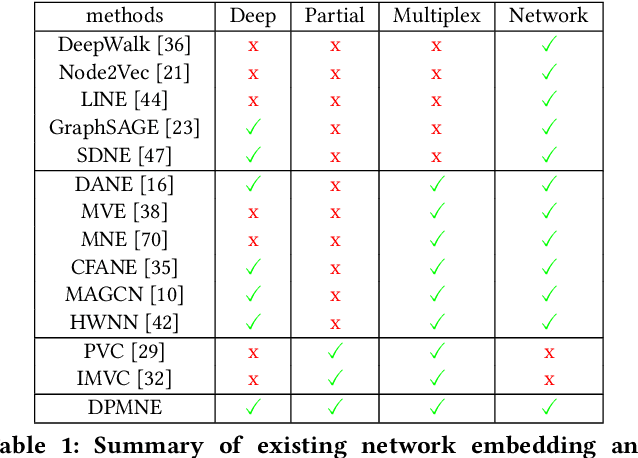
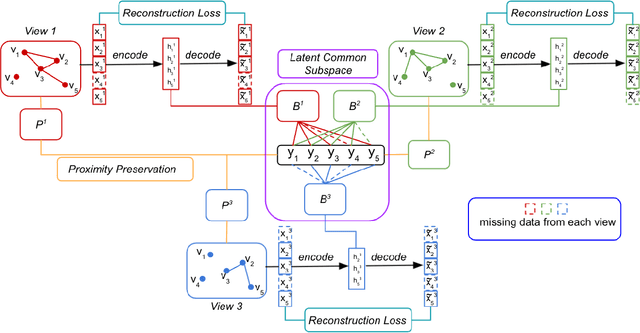
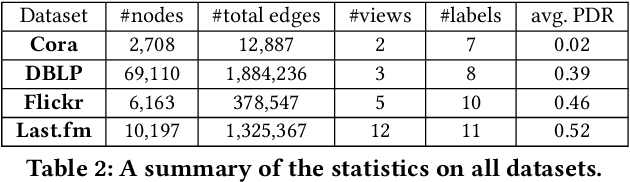
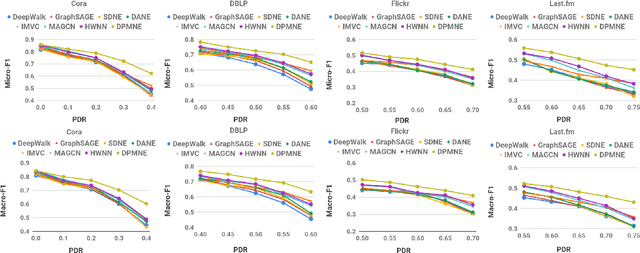
Network embedding is an effective technique to learn the low-dimensional representations of nodes in networks. Real-world networks are usually with multiplex or having multi-view representations from different relations. Recently, there has been increasing interest in network embedding on multiplex data. However, most existing multiplex approaches assume that the data is complete in all views. But in real applications, it is often the case that each view suffers from the missing of some data and therefore results in partial multiplex data. In this paper, we present a novel Deep Partial Multiplex Network Embedding approach to deal with incomplete data. In particular, the network embeddings are learned by simultaneously minimizing the deep reconstruction loss with the autoencoder neural network, enforcing the data consistency across views via common latent subspace learning, and preserving the data topological structure within the same network through graph Laplacian. We further prove the orthogonal invariant property of the learned embeddings and connect our approach with the binary embedding techniques. Experiments on four multiplex benchmarks demonstrate the superior performance of the proposed approach over several state-of-the-art methods on node classification, link prediction and clustering tasks.
DART: Domain-Adversarial Residual-Transfer Networks for Unsupervised Cross-Domain Image Classification
Dec 30, 2018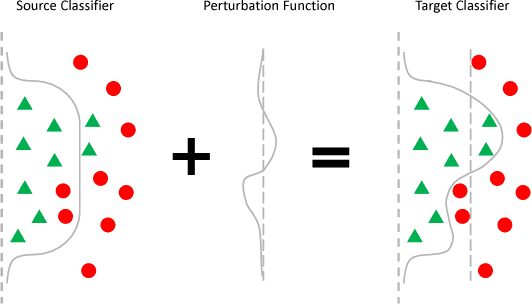

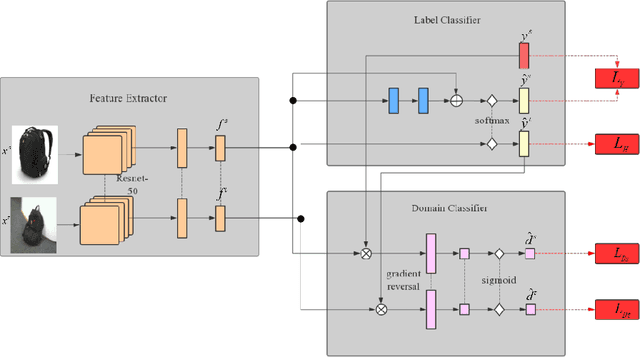
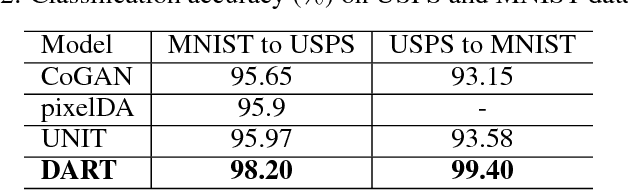
The accuracy of deep learning (e.g., convolutional neural networks) for an image classification task critically relies on the amount of labeled training data. Aiming to solve an image classification task on a new domain that lacks labeled data but gains access to cheaply available unlabeled data, unsupervised domain adaptation is a promising technique to boost the performance without incurring extra labeling cost, by assuming images from different domains share some invariant characteristics. In this paper, we propose a new unsupervised domain adaptation method named Domain-Adversarial Residual-Transfer (DART) learning of Deep Neural Networks to tackle cross-domain image classification tasks. In contrast to the existing unsupervised domain adaption approaches, the proposed DART not only learns domain-invariant features via adversarial training, but also achieves robust domain-adaptive classification via a residual-transfer strategy, all in an end-to-end training framework. We evaluate the performance of the proposed method for cross-domain image classification tasks on several well-known benchmark data sets, in which our method clearly outperforms the state-of-the-art approaches.
Image Tag Completion by Low-rank Factorization with Dual Reconstruction Structure Preserved
Jun 09, 2014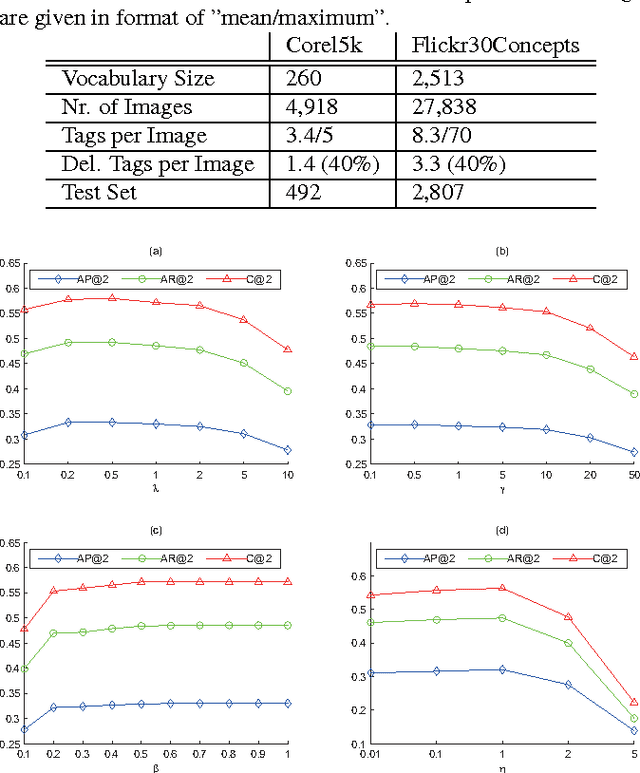
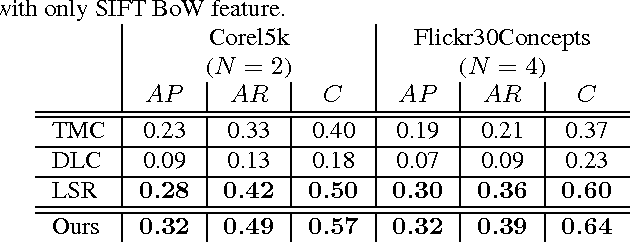
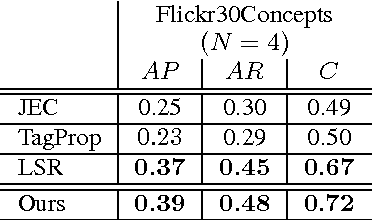
A novel tag completion algorithm is proposed in this paper, which is designed with the following features: 1) Low-rank and error s-parsity: the incomplete initial tagging matrix D is decomposed into the complete tagging matrix A and a sparse error matrix E. However, instead of minimizing its nuclear norm, A is further factor-ized into a basis matrix U and a sparse coefficient matrix V, i.e. D=UV+E. This low-rank formulation encapsulating sparse coding enables our algorithm to recover latent structures from noisy initial data and avoid performing too much denoising; 2) Local reconstruction structure consistency: to steer the completion of D, the local linear reconstruction structures in feature space and tag space are obtained and preserved by U and V respectively. Such a scheme could alleviate the negative effect of distances measured by low-level features and incomplete tags. Thus, we can seek a balance between exploiting as much information and not being mislead to suboptimal performance. Experiments conducted on Corel5k dataset and the newly issued Flickr30Concepts dataset demonstrate the effectiveness and efficiency of the proposed method.
Robust Nonnegative Matrix Factorization via $L_1$ Norm Regularization
Apr 11, 2012
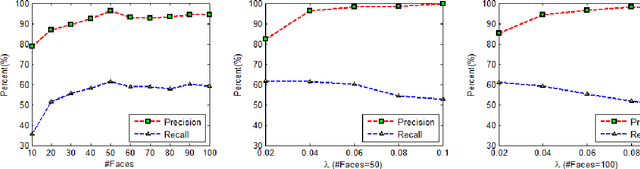
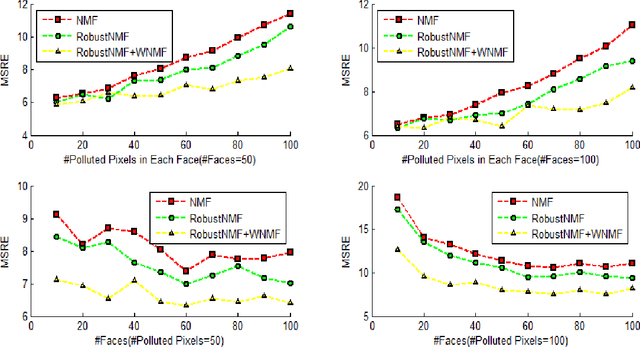

Nonnegative Matrix Factorization (NMF) is a widely used technique in many applications such as face recognition, motion segmentation, etc. It approximates the nonnegative data in an original high dimensional space with a linear representation in a low dimensional space by using the product of two nonnegative matrices. In many applications data are often partially corrupted with large additive noise. When the positions of noise are known, some existing variants of NMF can be applied by treating these corrupted entries as missing values. However, the positions are often unknown in many real world applications, which prevents the usage of traditional NMF or other existing variants of NMF. This paper proposes a Robust Nonnegative Matrix Factorization (RobustNMF) algorithm that explicitly models the partial corruption as large additive noise without requiring the information of positions of noise. In practice, large additive noise can be used to model outliers. In particular, the proposed method jointly approximates the clean data matrix with the product of two nonnegative matrices and estimates the positions and values of outliers/noise. An efficient iterative optimization algorithm with a solid theoretical justification has been proposed to learn the desired matrix factorization. Experimental results demonstrate the advantages of the proposed algorithm.