 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBruce W. Lee
HyperCLOVA X Technical Report
Apr 13, 2024
We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Tasks That Language Models Don't Learn
Feb 17, 2024We argue that there are certain properties of language that our current large language models (LLMs) don't learn. We present an empirical investigation of visual-auditory properties of language through a series of tasks, termed H-TEST. This benchmark highlights a fundamental gap between human linguistic comprehension, which naturally integrates sensory experiences, and the sensory-deprived processing capabilities of LLMs. In support of our hypothesis, 1. deliberate reasoning (Chain-of-Thought), 2. few-shot examples, or 3. stronger LLM from the same model family (LLaMA 2 13B -> LLaMA 2 70B) do not trivially bring improvements in H-TEST performance. Therefore, we make a particular connection to the philosophical case of Mary, who learns about the world in a sensory-deprived environment (Jackson, 1986). Our experiments show that some of the strongest proprietary LLMs stay near random chance baseline accuracy of 50%, highlighting the limitations of knowledge acquired in the absence of sensory experience.
Instruction Tuning with Human Curriculum
Oct 14, 2023The dominant paradigm for instruction tuning is the random-shuffled training of maximally diverse instruction-response pairs. This paper explores the potential benefits of applying a structured cognitive learning approach to instruction tuning in contemporary large language models like ChatGPT and GPT-4. Unlike the previous conventional randomized instruction dataset, we propose a highly structured synthetic dataset that mimics the progressive and organized nature of human education. We curate our dataset by aligning it with educational frameworks, incorporating meta information including its topic and cognitive rigor level for each sample. Our dataset covers comprehensive fine-grained topics spanning diverse educational stages (from middle school to graduate school) with various questions for each topic to enhance conceptual depth using Bloom's taxonomy-a classification framework distinguishing various levels of human cognition for each concept. The results demonstrate that this cognitive rigorous training approach yields significant performance enhancements - +3.06 on the MMLU benchmark and an additional +1.28 on AI2 Reasoning Challenge (hard set) - compared to conventional randomized training, all while avoiding additional computational costs. This research highlights the potential of leveraging human learning principles to enhance the capabilities of language models in comprehending and responding to complex instructions and tasks.
A Side-by-side Comparison of Transformers for English Implicit Discourse Relation Classification
Jul 07, 2023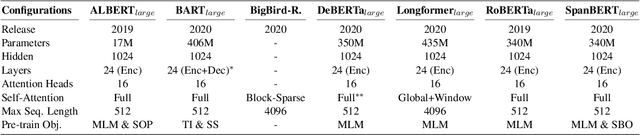
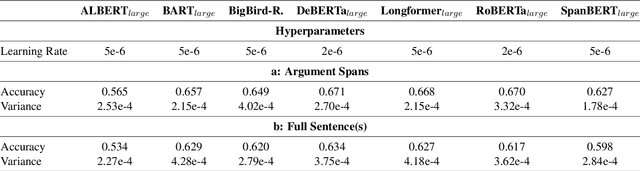
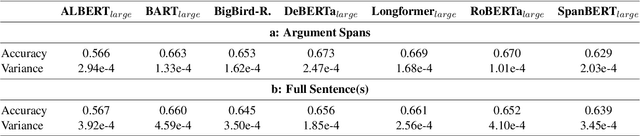

Though discourse parsing can help multiple NLP fields, there has been no wide language model search done on implicit discourse relation classification. This hinders researchers from fully utilizing public-available models in discourse analysis. This work is a straightforward, fine-tuned discourse performance comparison of seven pre-trained language models. We use PDTB-3, a popular discourse relation annotated dataset. Through our model search, we raise SOTA to 0.671 ACC and obtain novel observations. Some are contrary to what has been reported before (Shi and Demberg, 2019b), that sentence-level pre-training objectives (NSP, SBO, SOP) generally fail to produce the best performing model for implicit discourse relation classification. Counterintuitively, similar-sized PLMs with MLM and full attention led to better performance.
Linguistic Properties of Truthful Response
May 25, 2023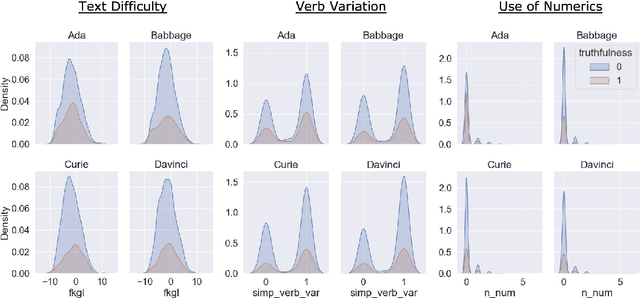
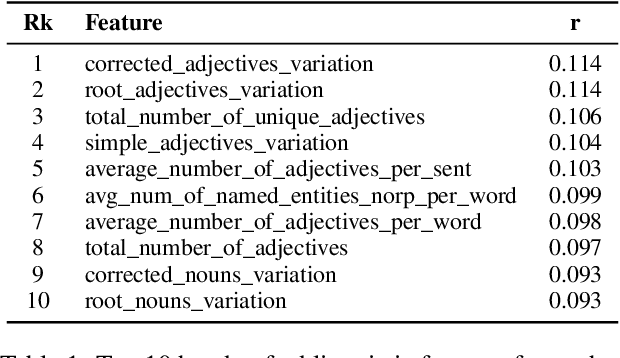
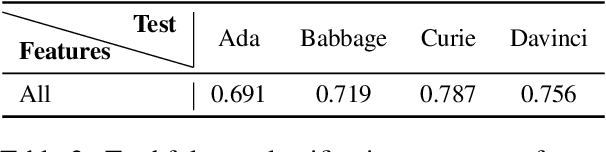
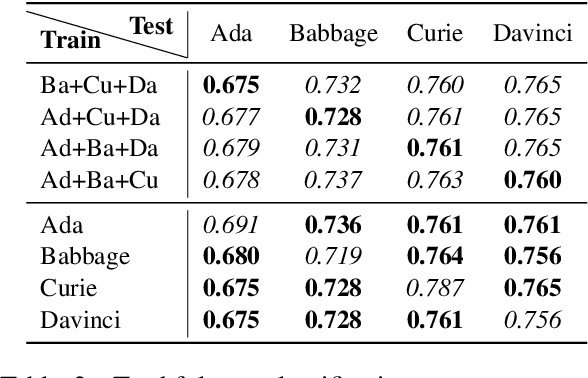
We investigate the phenomenon of an LLM's untruthful response using a large set of 220 handcrafted linguistic features. We focus on GPT-3 models and find that the linguistic profiles of responses are similar across model sizes. That is, how varying-sized LLMs respond to given prompts stays similar on the linguistic properties level. We expand upon this finding by training support vector machines that rely only upon the stylistic components of model responses to classify the truthfulness of statements. Though the dataset size limits our current findings, we present promising evidence that truthfulness detection is possible without evaluating the content itself.
LFTK: Handcrafted Features in Computational Linguistics
May 25, 2023



Past research has identified a rich set of handcrafted linguistic features that can potentially assist various tasks. However, their extensive number makes it difficult to effectively select and utilize existing handcrafted features. Coupled with the problem of inconsistent implementation across research works, there has been no categorization scheme or generally-accepted feature names. This creates unwanted confusion. Also, most existing handcrafted feature extraction libraries are not open-source or not actively maintained. As a result, a researcher often has to build such an extraction system from the ground up. We collect and categorize more than 220 popular handcrafted features grounded on past literature. Then, we conduct a correlation analysis study on several task-specific datasets and report the potential use cases of each feature. Lastly, we devise a multilingual handcrafted linguistic feature extraction system in a systematically expandable manner. We open-source our system for public access to a rich set of pre-implemented handcrafted features. Our system is coined LFTK and is the largest of its kind. Find it at github.com/brucewlee/lftk.
Prompt-based Learning for Text Readability Assessment
Feb 25, 2023
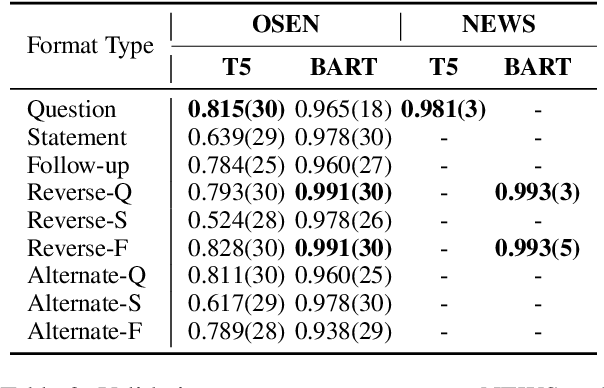
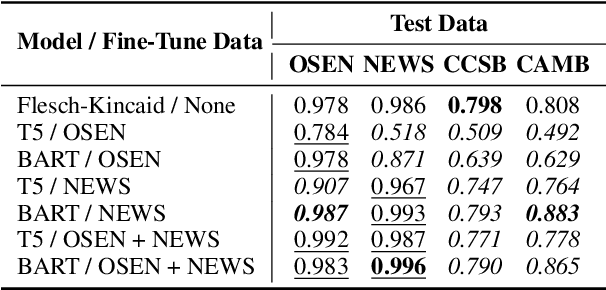
We propose the novel adaptation of a pre-trained seq2seq model for readability assessment. We prove that a seq2seq model - T5 or BART - can be adapted to discern which text is more difficult from two given texts (pairwise). As an exploratory study to prompt-learn a neural network for text readability in a text-to-text manner, we report useful tips for future work in seq2seq training and ranking-based approach to readability assessment. Specifically, we test nine input-output formats/prefixes and show that they can significantly influence the final model performance. Also, we argue that the combination of text-to-text training and pairwise ranking setup 1) enables leveraging multiple parallel text simplification data for teaching readability and 2) trains a neural model for the general concept of readability (therefore, better cross-domain generalization). At last, we report a 99.6% pairwise classification accuracy on Newsela and a 98.7% for OneStopEnglish, through a joint training approach.
Traditional Readability Formulas Compared for English
Jan 10, 2023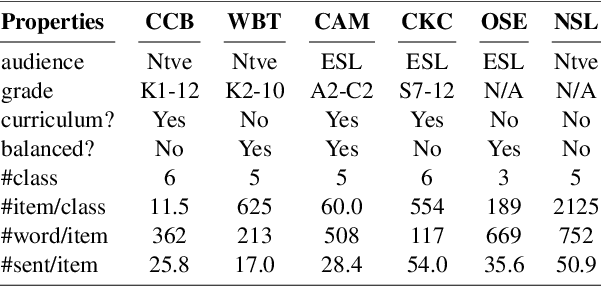
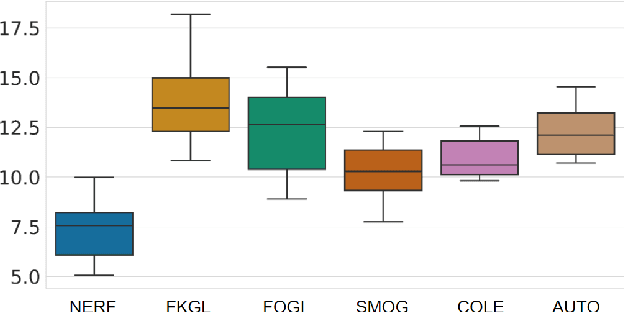
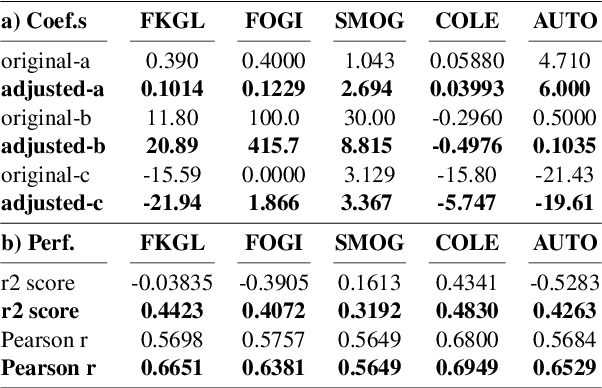
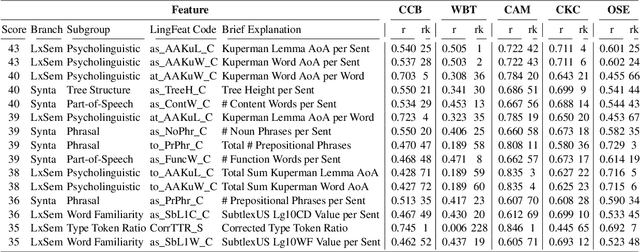
Traditional English readability formulas, or equations, were largely developed in the 20th century. Nonetheless, many researchers still rely on them for various NLP applications. This phenomenon is presumably due to the convenience and straightforwardness of readability formulas. In this work, we contribute to the NLP community by 1. introducing New English Readability Formula (NERF), 2. recalibrating the coefficients of old readability formulas (Flesch-Kincaid Grade Level, Fog Index, SMOG Index, Coleman-Liau Index, and Automated Readability Index), 3. evaluating the readability formulas, for use in text simplification studies and medical texts, and 4. developing a Python-based program for the wide application to various NLP projects.
Auto-Select Reading Passages in English Assessment Tests?
May 14, 2022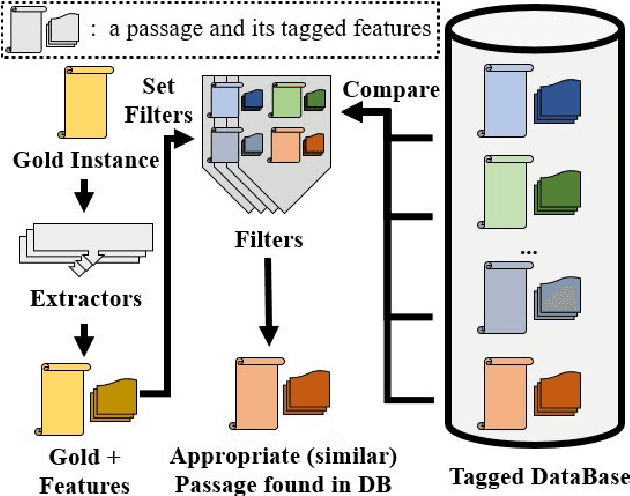
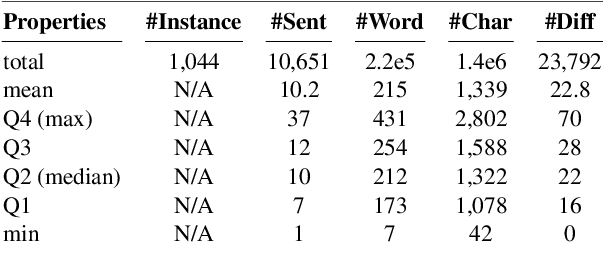
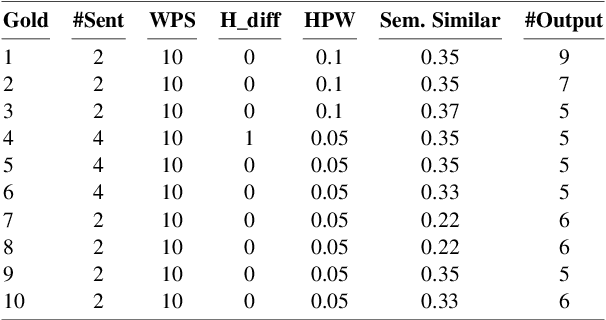
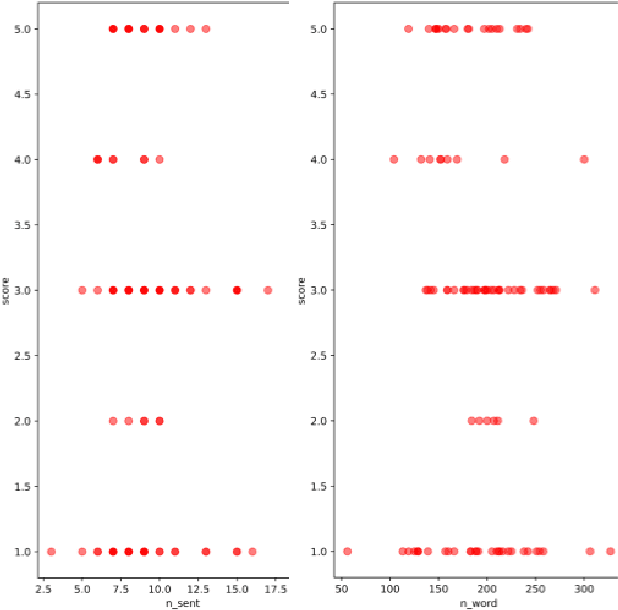
We show a method to auto-select reading passages in English assessment tests and share some key insights that can be helpful in related fields. In specifics, we prove that finding a similar passage (to a passage that already appeared in the test) can give a suitable passage for test development. In the process, we create a simple database-tagger-filter algorithm and perform a human evaluation. However, 1. the textual features, that we analyzed, lack coverage, and 2. we fail to find meaningful correlations between each feature and suitability score. Lastly, we describe the future developments to improve automated reading passage selection.
Pushing on Text Readability Assessment: A Transformer Meets Handcrafted Linguistic Features
Sep 25, 2021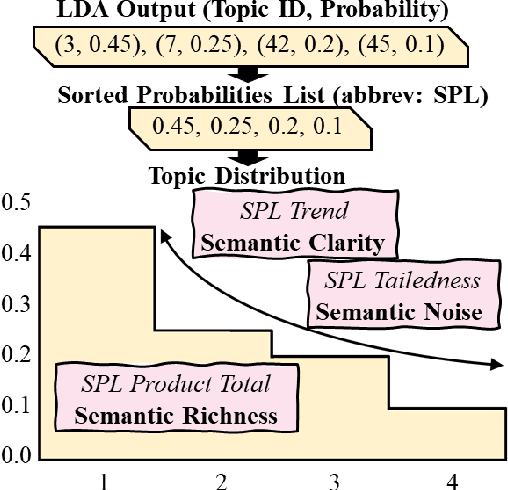
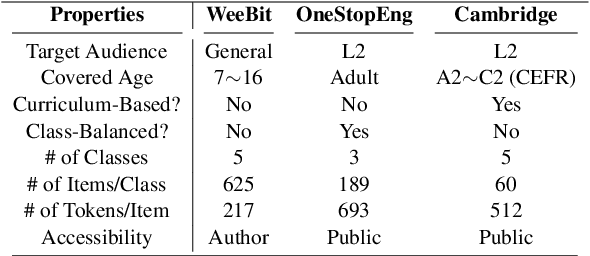
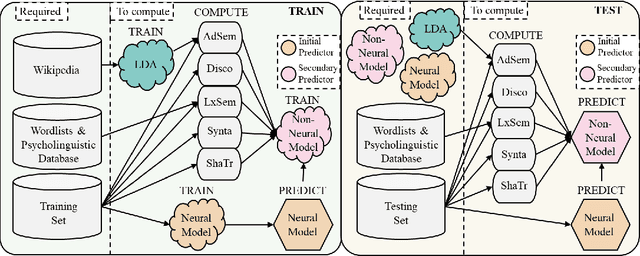
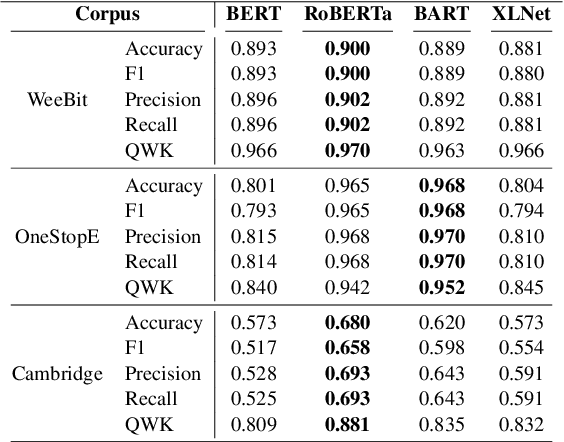
We report two essential improvements in readability assessment: 1. three novel features in advanced semantics and 2. the timely evidence that traditional ML models (e.g. Random Forest, using handcrafted features) can combine with transformers (e.g. RoBERTa) to augment model performance. First, we explore suitable transformers and traditional ML models. Then, we extract 255 handcrafted linguistic features using self-developed extraction software. Finally, we assemble those to create several hybrid models, achieving state-of-the-art (SOTA) accuracy on popular datasets in readability assessment. The use of handcrafted features help model performance on smaller datasets. Notably, our RoBERTA-RF-T1 hybrid achieves the near-perfect classification accuracy of 99%, a 20.3% increase from the previous SOTA.