 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiwan Chung
HyperCLOVA X Technical Report
Apr 13, 2024
We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models
Apr 03, 2024Algorithmic reasoning refers to the ability to understand the complex patterns behind the problem and decompose them into a sequence of reasoning steps towards the solution. Such nature of algorithmic reasoning makes it a challenge for large language models (LLMs), even though they have demonstrated promising performance in other reasoning tasks. Within this context, some recent studies use programming languages (e.g., Python) to express the necessary logic for solving a given instance/question (e.g., Program-of-Thought) as inspired by their strict and precise syntaxes. However, it is non-trivial to write an executable code that expresses the correct logic on the fly within a single inference call. Also, the code generated specifically for an instance cannot be reused for others, even if they are from the same task and might require identical logic to solve. This paper presents Think-and-Execute, a novel framework that decomposes the reasoning process of language models into two steps. (1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode; (2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code. With extensive experiments on seven algorithmic reasoning tasks, we demonstrate the effectiveness of Think-and-Execute. Our approach better improves LMs' reasoning compared to several strong baselines performing instance-specific reasoning (e.g., CoT and PoT), suggesting the helpfulness of discovering task-level logic. Also, we show that compared to natural language, pseudocode can better guide the reasoning of LMs, even though they are trained to follow natural language instructions.
Long Story Short: a Summarize-then-Search Method for Long Video Question Answering
Nov 02, 2023Large language models such as GPT-3 have demonstrated an impressive capability to adapt to new tasks without requiring task-specific training data. This capability has been particularly effective in settings such as narrative question answering, where the diversity of tasks is immense, but the available supervision data is small. In this work, we investigate if such language models can extend their zero-shot reasoning abilities to long multimodal narratives in multimedia content such as drama, movies, and animation, where the story plays an essential role. We propose Long Story Short, a framework for narrative video QA that first summarizes the narrative of the video to a short plot and then searches parts of the video relevant to the question. We also propose to enhance visual matching with CLIPCheck. Our model outperforms state-of-the-art supervised models by a large margin, highlighting the potential of zero-shot QA for long videos.
Reading Books is Great, But Not if You Are Driving! Visually Grounded Reasoning about Defeasible Commonsense Norms
Oct 16, 2023Commonsense norms are defeasible by context: reading books is usually great, but not when driving a car. While contexts can be explicitly described in language, in embodied scenarios, contexts are often provided visually. This type of visually grounded reasoning about defeasible commonsense norms is generally easy for humans, but (as we show) poses a challenge for machines, as it necessitates both visual understanding and reasoning about commonsense norms. We construct a new multimodal benchmark for studying visual-grounded commonsense norms: NORMLENS. NORMLENS consists of 10K human judgments accompanied by free-form explanations covering 2K multimodal situations, and serves as a probe to address two questions: (1) to what extent can models align with average human judgment? and (2) how well can models explain their predicted judgments? We find that state-of-the-art model judgments and explanations are not well-aligned with human annotation. Additionally, we present a new approach to better align models with humans by distilling social commonsense knowledge from large language models. The data and code are released at https://seungjuhan.me/normlens.
VLIS: Unimodal Language Models Guide Multimodal Language Generation
Oct 15, 2023Multimodal language generation, which leverages the synergy of language and vision, is a rapidly expanding field. However, existing vision-language models face challenges in tasks that require complex linguistic understanding. To address this issue, we introduce Visual-Language models as Importance Sampling weights (VLIS), a novel framework that combines the visual conditioning capability of vision-language models with the language understanding of unimodal text-only language models without further training. It extracts pointwise mutual information of each image and text from a visual-language model and uses the value as an importance sampling weight to adjust the token likelihood from a text-only model. VLIS improves vision-language models on diverse tasks, including commonsense understanding (WHOOPS, OK-VQA, and ScienceQA) and complex text generation (Concadia, Image Paragraph Captioning, and ROCStories). Our results suggest that VLIS represents a promising new direction for multimodal language generation.
Multimodal Knowledge Alignment with Reinforcement Learning
May 25, 2022
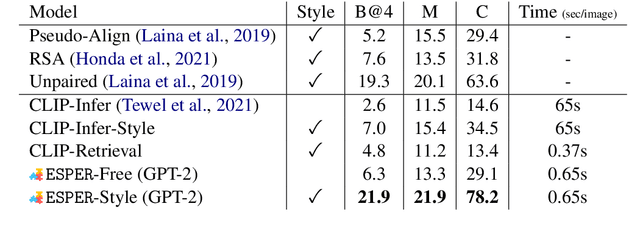
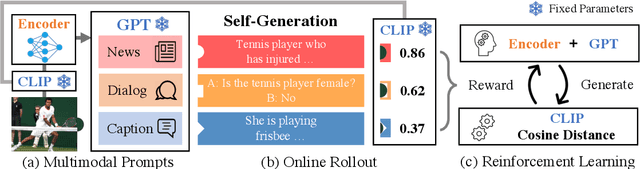
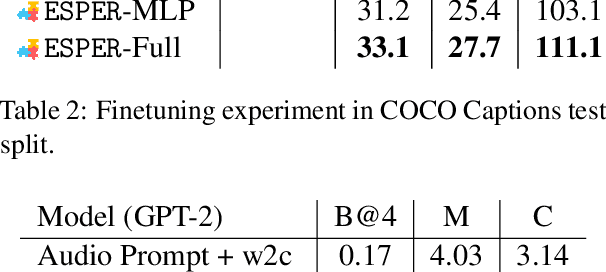
Large language models readily adapt to novel settings, even without task-specific training data. Can their zero-shot capacity be extended to multimodal inputs? In this work, we propose ESPER which extends language-only zero-shot models to unseen multimodal tasks, like image and audio captioning. Our key novelty is to use reinforcement learning to align multimodal inputs to language model generations without direct supervision: for example, in the image case our reward optimization relies only on cosine similarity derived from CLIP, and thus requires no additional explicitly paired (image, caption) data. Because the parameters of the language model are left unchanged, the model maintains its capacity for zero-shot generalization. Experiments demonstrate that ESPER outperforms baselines and prior work on a variety of zero-shot tasks; these include a new benchmark we collect+release, ESP dataset, which tasks models with generating several diversely-styled captions for each image.
Automatic Curation of Large-Scale Datasets for Audio-Visual Representation Learning
Jan 26, 2021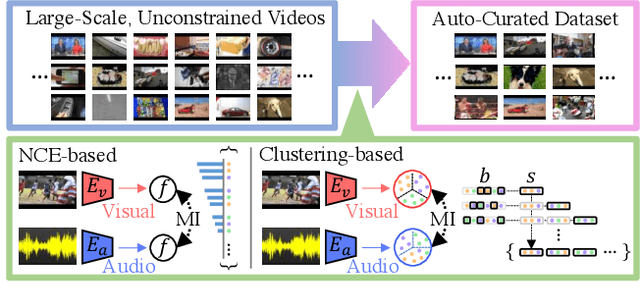

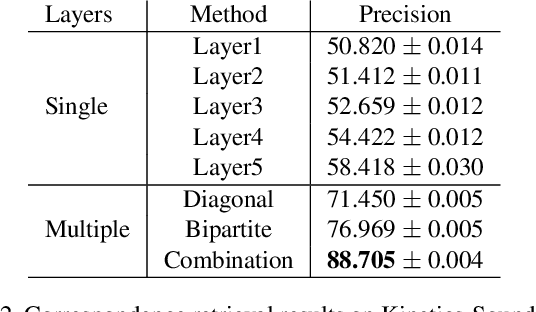
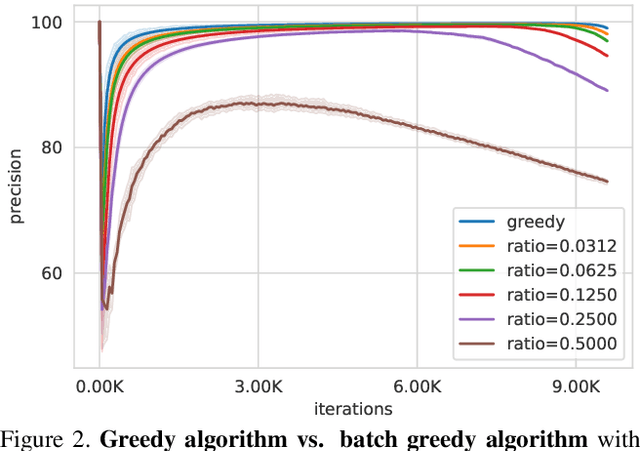
Large-scale datasets are the cornerstone of self-supervised representation learning. Existing algorithms extract learning signals by making certain assumptions about the data, e.g., spatio-temporal continuity and multimodal correspondence. Unfortunately, finding a large amount of data that satisfies such assumptions is sometimes not straightforward. This restricts the community to rely on datasets that require laborious annotation and/or manual filtering processes. In this paper, we describe a subset optimization approach for automatic dataset curation. Focusing on the scenario of audio-visual representation learning, we pose the problem as finding a subset that maximizes the mutual information between audio and visual channels in videos. We demonstrate that our approach finds videos with high audio-visual correspondence and show that self-supervised models trained on our data, despite being automatically constructed, achieve similar downstream performances to existing video datasets with similar scales. The most significant benefit of our approach is scalability. We release the largest video dataset for audio-visual research collected automatically using our approach.