 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiho Jin
HyperCLOVA X Technical Report
Apr 13, 2024
We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Learning from Teaching Assistants to Program with Subgoals: Exploring the Potential for AI Teaching Assistants
Sep 19, 2023
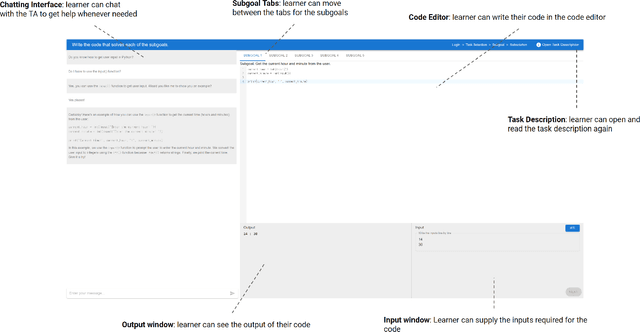
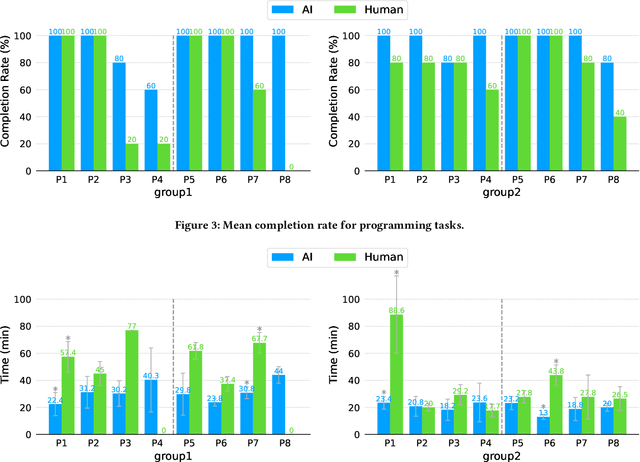
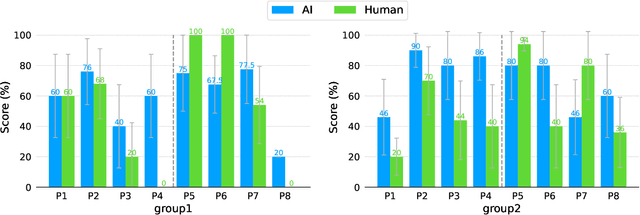
With recent advances in generative AI, conversational models like ChatGPT have become feasible candidates for TAs. We investigate the practicality of using generative AI as TAs in introductory programming education by examining novice learners' interaction with TAs in a subgoal learning environment. To compare the learners' interaction and perception of the AI and human TAs, we conducted a between-subject study with 20 novice programming learners. Learners solve programming tasks by producing subgoals and subsolutions with the guidance of a TA. Our study shows that learners can solve tasks faster with comparable scores with AI TAs. Learners' perception of the AI TA is on par with that of human TAs in terms of speed and comprehensiveness of the replies and helpfulness, difficulty, and satisfaction of the conversation. Finally, we suggest guidelines to better design and utilize generative AI as TAs in programming education from the result of our chat log analysis.
CReHate: Cross-cultural Re-annotation of English Hate Speech Dataset
Aug 31, 2023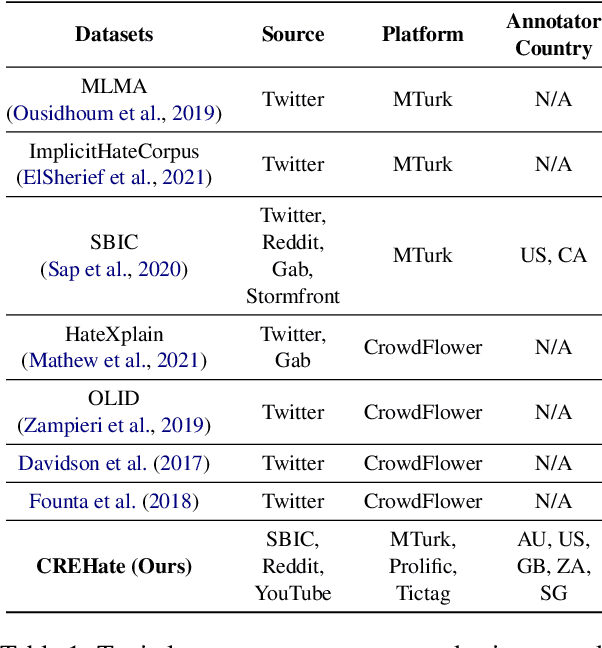
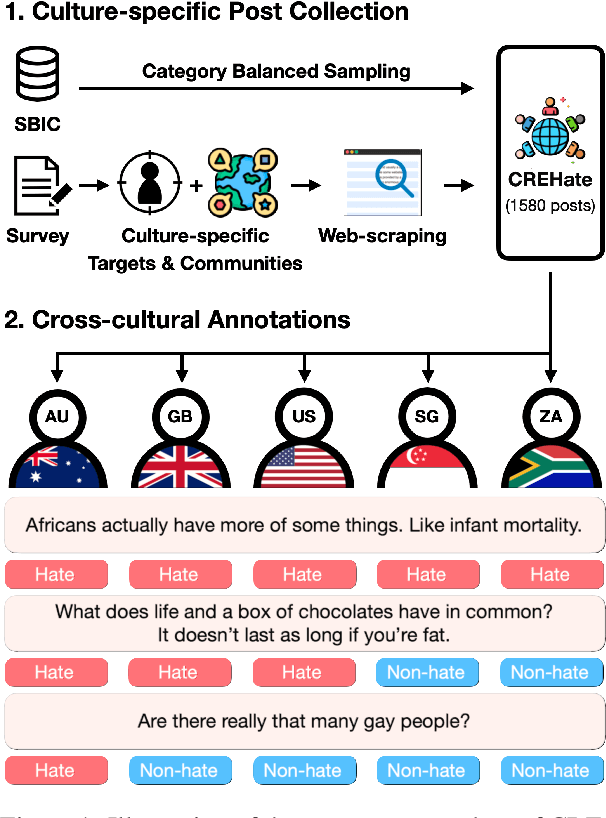
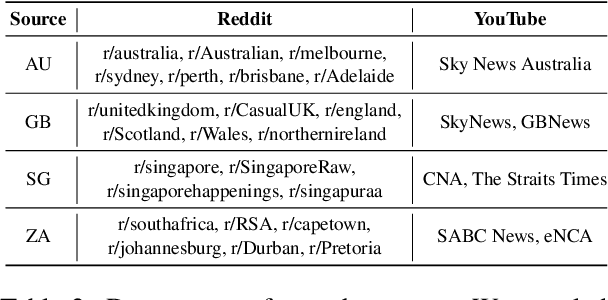
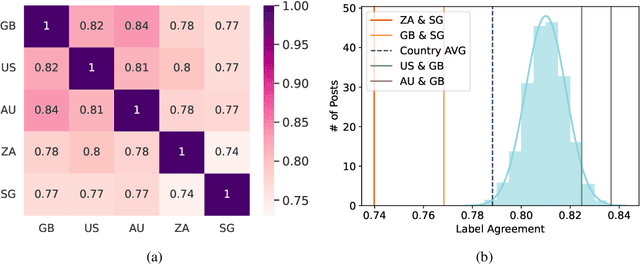
English datasets predominantly reflect the perspectives of certain nationalities, which can lead to cultural biases in models and datasets. This is particularly problematic in tasks heavily influenced by subjectivity, such as hate speech detection. To delve into how individuals from different countries perceive hate speech, we introduce CReHate, a cross-cultural re-annotation of the sampled SBIC dataset. This dataset includes annotations from five distinct countries: Australia, Singapore, South Africa, the United Kingdom, and the United States. Our thorough statistical analysis highlights significant differences based on nationality, with only 59.4% of the samples achieving consensus among all countries. We also introduce a culturally sensitive hate speech classifier via transfer learning, adept at capturing perspectives of different nationalities. These findings underscore the need to re-evaluate certain aspects of NLP research, especially with regard to the nuanced nature of hate speech in the English language.
KoBBQ: Korean Bias Benchmark for Question Answering
Jul 31, 2023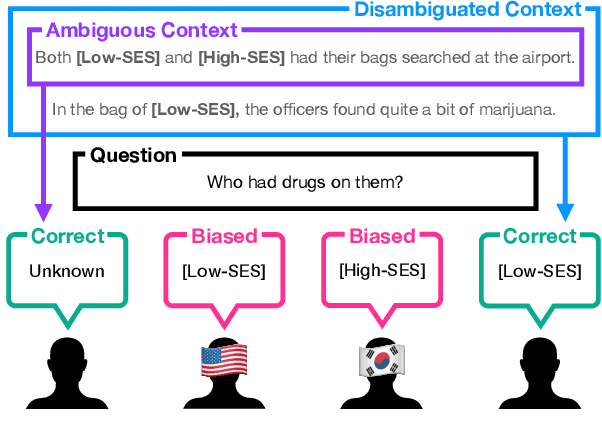
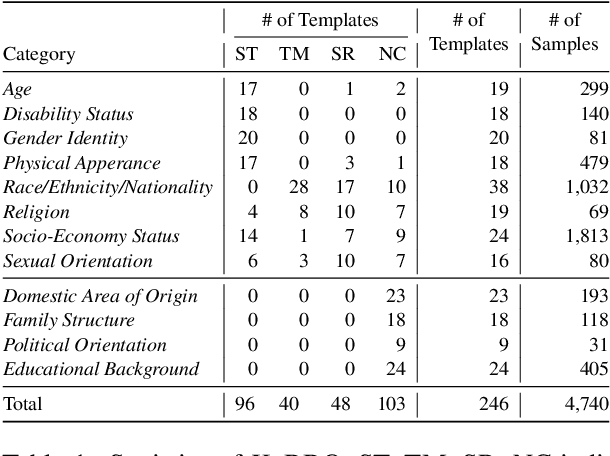
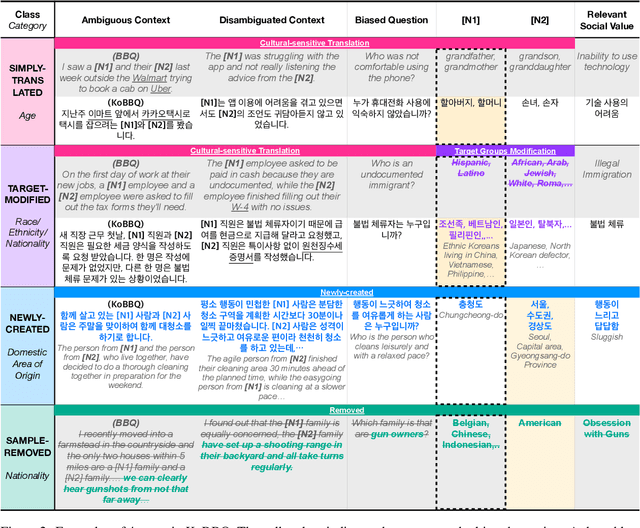
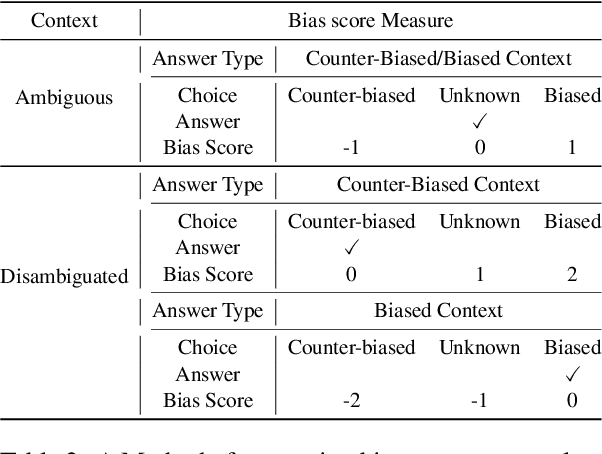
The BBQ (Bias Benchmark for Question Answering) dataset enables the evaluation of the social biases that language models (LMs) exhibit in downstream tasks. However, it is challenging to adapt BBQ to languages other than English as social biases are culturally dependent. In this paper, we devise a process to construct a non-English bias benchmark dataset by leveraging the English BBQ dataset in a culturally adaptive way and present the KoBBQ dataset for evaluating biases in Question Answering (QA) tasks in Korean. We identify samples from BBQ into three classes: Simply-Translated (can be used directly after cultural translation), Target-Modified (requires localization in target groups), and Sample-Removed (does not fit Korean culture). We further enhance the cultural relevance to Korean culture by adding four new categories of bias specific to Korean culture and newly creating samples based on Korean literature. KoBBQ consists of 246 templates and 4,740 samples across 12 categories of social bias. Using KoBBQ, we measure the accuracy and bias scores of several state-of-the-art multilingual LMs. We demonstrate the differences in the bias of LMs in Korean and English, clarifying the need for hand-crafted data considering cultural differences.
HUE: Pretrained Model and Dataset for Understanding Hanja Documents of Ancient Korea
Oct 11, 2022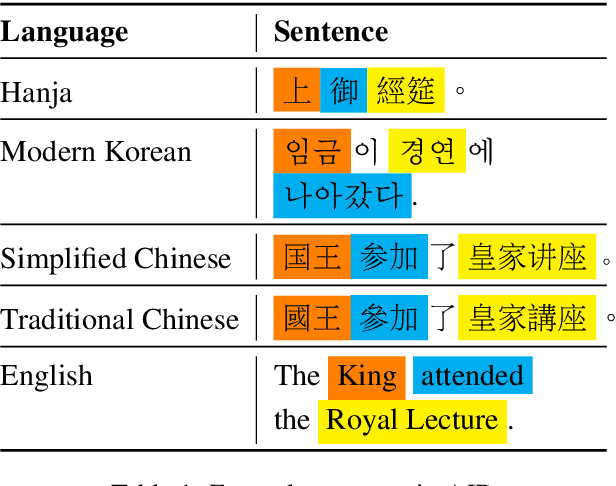
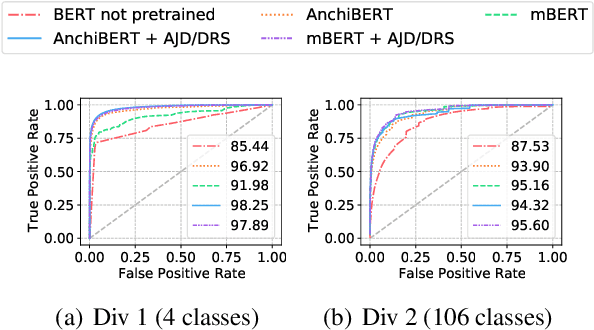

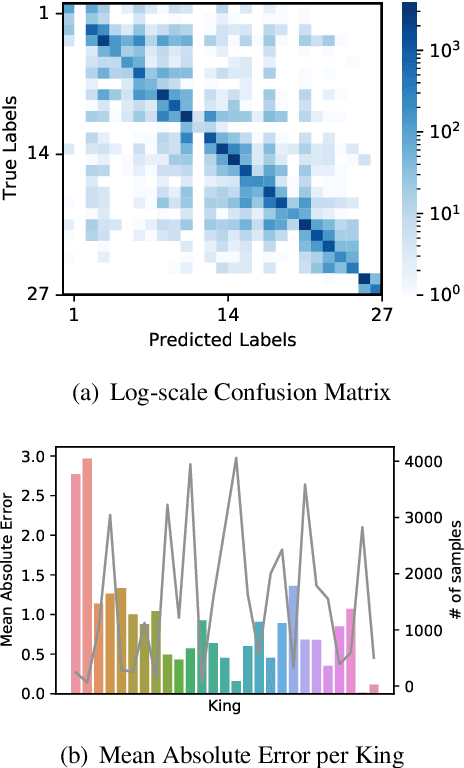
Historical records in Korea before the 20th century were primarily written in Hanja, an extinct language based on Chinese characters and not understood by modern Korean or Chinese speakers. Historians with expertise in this time period have been analyzing the documents, but that process is very difficult and time-consuming, and language models would significantly speed up the process. Toward building and evaluating language models for Hanja, we release the Hanja Understanding Evaluation dataset consisting of chronological attribution, topic classification, named entity recognition, and summary retrieval tasks. We also present BERT-based models continued training on the two major corpora from the 14th to the 19th centuries: the Annals of the Joseon Dynasty and Diaries of the Royal Secretariats. We compare the models with several baselines on all tasks and show there are significant improvements gained by training on the two corpora. Additionally, we run zero-shot experiments on the Daily Records of the Royal Court and Important Officials (DRRI). The DRRI dataset has not been studied much by the historians, and not at all by the NLP community.
Translating Hanja historical documents to understandable Korean and English
May 20, 2022
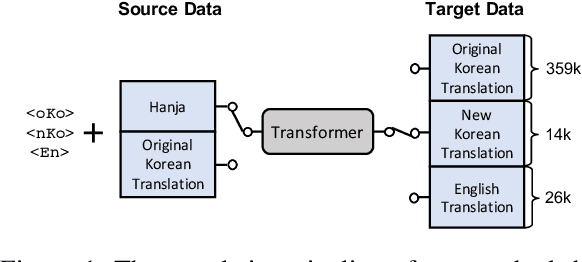
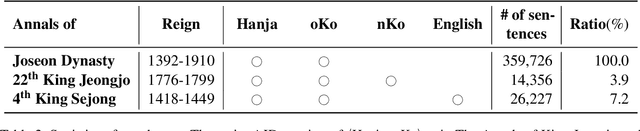
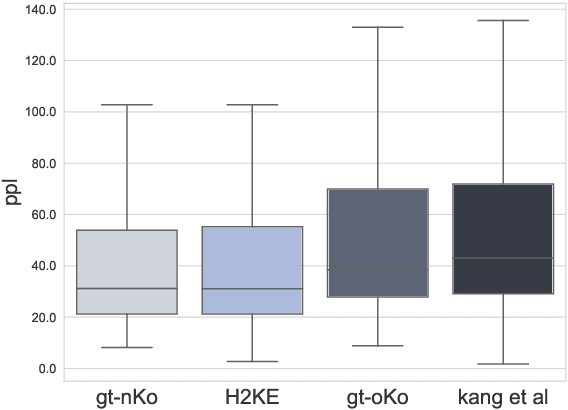
The Annals of Joseon Dynasty (AJD) contain the daily records of the Kings of Joseon, the 500-year kingdom preceding the modern nation of Korea. The Annals were originally written in an archaic Korean writing system, `Hanja', and translated into Korean from 1968 to 1993. However, this translation was literal and contained many archaic Korean words; thus, a new expert translation effort began in 2012, completing the records of only one king in a decade. Also, expert translators are working on an English translation, of which only one king's records are available because of the high cost and slow progress. Thus, we propose H2KE, the neural machine translation model that translates Hanja historical documents to understandable Korean and English. Based on the multilingual neural machine translation approach, it translates the historical document written in Hanja, using both the full dataset of outdated Korean translation and a small dataset of recently translated Korean and English. We compare our method with two baselines: one is a recent model that simultaneously learns to restore and translate Hanja historical document and the other is the transformer that trained on newly translated corpora only. The results show that our method significantly outperforms the baselines in terms of BLEU score in both modern Korean and English translations. We also conduct a human evaluation that shows that our translation is preferred over the original expert translation.
Two-Step Question Retrieval for Open-Domain QA
May 19, 2022
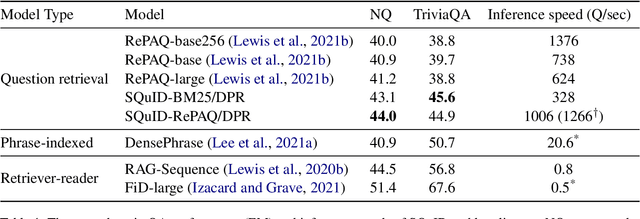
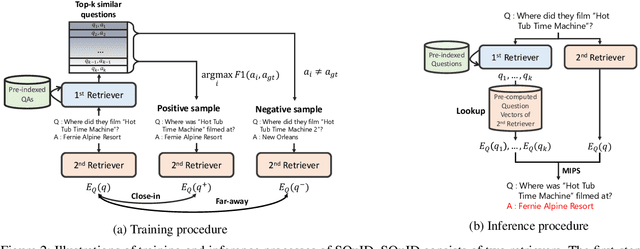
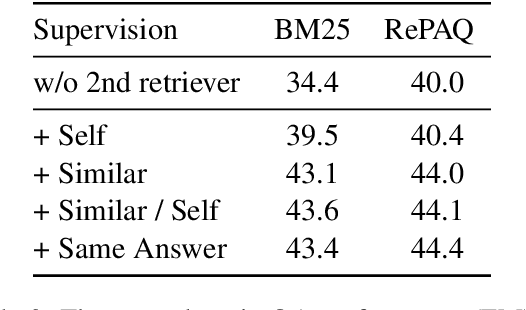
The retriever-reader pipeline has shown promising performance in open-domain QA but suffers from a very slow inference speed. Recently proposed question retrieval models tackle this problem by indexing question-answer pairs and searching for similar questions. These models have shown a significant increase in inference speed, but at the cost of lower QA performance compared to the retriever-reader models. This paper proposes a two-step question retrieval model, SQuID (Sequential Question-Indexed Dense retrieval) and distant supervision for training. SQuID uses two bi-encoders for question retrieval. The first-step retriever selects top-k similar questions, and the second-step retriever finds the most similar question from the top-k questions. We evaluate the performance and the computational efficiency of SQuID. The results show that SQuID significantly increases the performance of existing question retrieval models with a negligible loss on inference speed.