 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristos Kotselidis
Towards High Performance Java-based Deep Learning Frameworks
Jan 13, 2020

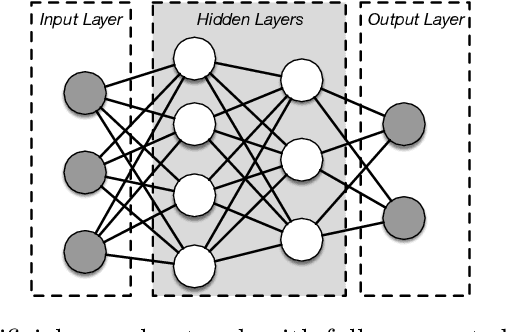
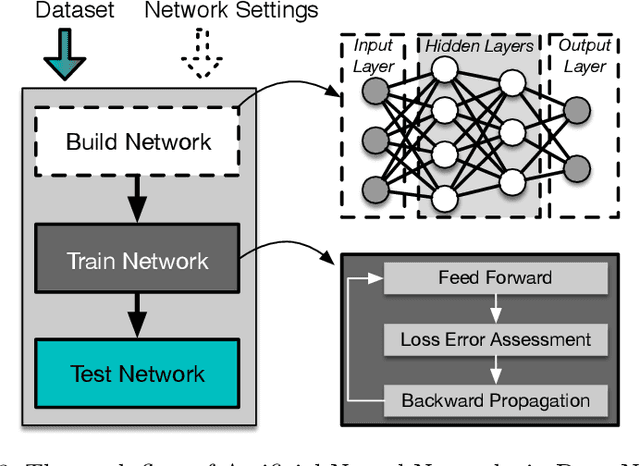
The advent of modern cloud services along with the huge volume of data produced on a daily basis, have set the demand for fast and efficient data processing. This demand is common among numerous application domains, such as deep learning, data mining, and computer vision. Prior research has focused on employing hardware accelerators as a means to overcome this inefficiency. This trend has driven software development to target heterogeneous execution, and several modern computing systems have incorporated a mixture of diverse computing components, including GPUs and FPGAs. However, the specialization of the applications' code for heterogeneous execution is not a trivial task, as it requires developers to have hardware expertise in order to obtain high performance. The vast majority of the existing deep learning frameworks that support heterogeneous acceleration, rely on the implementation of wrapper calls from a high-level programming language to a low-level accelerator backend, such as OpenCL, CUDA or HLS. In this paper we have employed TornadoVM, a state-of-the-art heterogeneous programming framework to transparently accelerate Deep Netts; a Java-based deep learning framework. Our initial results demonstrate up to 8x performance speedup when executing the back propagation process of the network's training on AMD GPUs against the sequential execution of the original Deep Netts framework.
Navigating the Landscape for Real-time Localisation and Mapping for Robotics and Virtual and Augmented Reality
Aug 20, 2018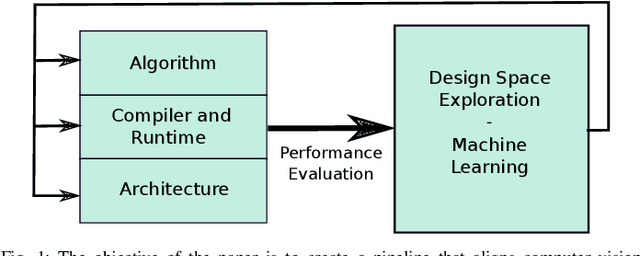
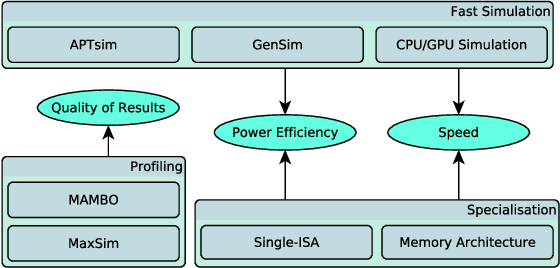
Visual understanding of 3D environments in real-time, at low power, is a huge computational challenge. Often referred to as SLAM (Simultaneous Localisation and Mapping), it is central to applications spanning domestic and industrial robotics, autonomous vehicles, virtual and augmented reality. This paper describes the results of a major research effort to assemble the algorithms, architectures, tools, and systems software needed to enable delivery of SLAM, by supporting applications specialists in selecting and configuring the appropriate algorithm and the appropriate hardware, and compilation pathway, to meet their performance, accuracy, and energy consumption goals. The major contributions we present are (1) tools and methodology for systematic quantitative evaluation of SLAM algorithms, (2) automated, machine-learning-guided exploration of the algorithmic and implementation design space with respect to multiple objectives, (3) end-to-end simulation tools to enable optimisation of heterogeneous, accelerated architectures for the specific algorithmic requirements of the various SLAM algorithmic approaches, and (4) tools for delivering, where appropriate, accelerated, adaptive SLAM solutions in a managed, JIT-compiled, adaptive runtime context.