 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaniel Rebain
BANF: Band-limited Neural Fields for Levels of Detail Reconstruction
Apr 19, 2024
Largely due to their implicit nature, neural fields lack a direct mechanism for filtering, as Fourier analysis from discrete signal processing is not directly applicable to these representations. Effective filtering of neural fields is critical to enable level-of-detail processing in downstream applications, and support operations that involve sampling the field on regular grids (e.g. marching cubes). Existing methods that attempt to decompose neural fields in the frequency domain either resort to heuristics or require extensive modifications to the neural field architecture. We show that via a simple modification, one can obtain neural fields that are low-pass filtered, and in turn show how this can be exploited to obtain a frequency decomposition of the entire signal. We demonstrate the validity of our technique by investigating level-of-detail reconstruction, and showing how coarser representations can be computed effectively.
Does Gaussian Splatting need SFM Initialization?
Apr 18, 20243D Gaussian Splatting has recently been embraced as a versatile and effective method for scene reconstruction and novel view synthesis, owing to its high-quality results and compatibility with hardware rasterization. Despite its advantages, Gaussian Splatting's reliance on high-quality point cloud initialization by Structure-from-Motion (SFM) algorithms is a significant limitation to be overcome. To this end, we investigate various initialization strategies for Gaussian Splatting and delve into how volumetric reconstructions from Neural Radiance Fields (NeRF) can be utilized to bypass the dependency on SFM data. Our findings demonstrate that random initialization can perform much better if carefully designed and that by employing a combination of improved initialization strategies and structure distillation from low-cost NeRF models, it is possible to achieve equivalent results, or at times even superior, to those obtained from SFM initialization.
3D Gaussian Splatting as Markov Chain Monte Carlo
Apr 15, 2024While 3D Gaussian Splatting has recently become popular for neural rendering, current methods rely on carefully engineered cloning and splitting strategies for placing Gaussians, which does not always generalize and may lead to poor-quality renderings. In addition, for real-world scenes, they rely on a good initial point cloud to perform well. In this work, we rethink 3D Gaussians as random samples drawn from an underlying probability distribution describing the physical representation of the scene -- in other words, Markov Chain Monte Carlo (MCMC) samples. Under this view, we show that the 3D Gaussian updates are strikingly similar to a Stochastic Langevin Gradient Descent (SGLD) update. As with MCMC, samples are nothing but past visit locations, adding new Gaussians under our framework can simply be realized without heuristics as placing Gaussians at existing Gaussian locations. To encourage using fewer Gaussians for efficiency, we introduce an L1-regularizer on the Gaussians. On various standard evaluation scenes, we show that our method provides improved rendering quality, easy control over the number of Gaussians, and robustness to initialization.
Volumetric Rendering with Baked Quadrature Fields
Dec 02, 2023We propose a novel Neural Radiance Field (NeRF) representation for non-opaque scenes that allows fast inference by utilizing textured polygons. Despite the high-quality novel view rendering that NeRF provides, a critical limitation is that it relies on volume rendering that can be computationally expensive and does not utilize the advancements in modern graphics hardware. Existing methods for this problem fall short when it comes to modelling volumetric effects as they rely purely on surface rendering. We thus propose to model the scene with polygons, which can then be used to obtain the quadrature points required to model volumetric effects, and also their opacity and colour from the texture. To obtain such polygonal mesh, we train a specialized field whose zero-crossings would correspond to the quadrature points when volume rendering, and perform marching cubes on this field. We then rasterize the polygons and utilize the fragment shaders to obtain the final colour image. Our method allows rendering on various devices and easy integration with existing graphics frameworks while keeping the benefits of volume rendering alive.
Accelerating Neural Field Training via Soft Mining
Nov 29, 2023We present an approach to accelerate Neural Field training by efficiently selecting sampling locations. While Neural Fields have recently become popular, it is often trained by uniformly sampling the training domain, or through handcrafted heuristics. We show that improved convergence and final training quality can be achieved by a soft mining technique based on importance sampling: rather than either considering or ignoring a pixel completely, we weigh the corresponding loss by a scalar. To implement our idea we use Langevin Monte-Carlo sampling. We show that by doing so, regions with higher error are being selected more frequently, leading to more than 2x improvement in convergence speed. The code and related resources for this study are publicly available at https://ubc-vision.github.io/nf-soft-mining/.
nerf2nerf: Pairwise Registration of Neural Radiance Fields
Nov 03, 2022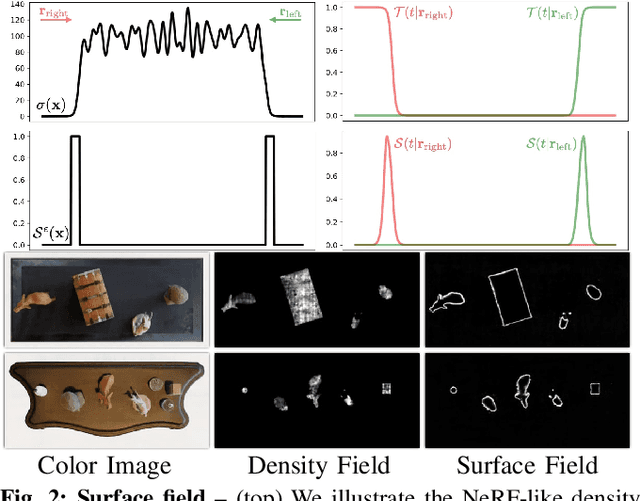

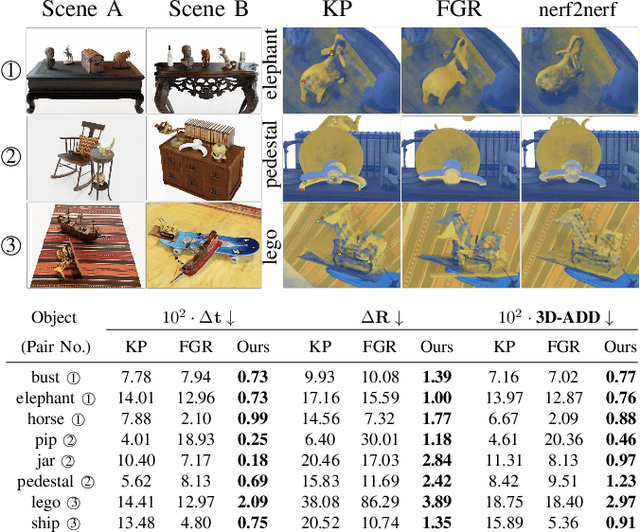

We introduce a technique for pairwise registration of neural fields that extends classical optimization-based local registration (i.e. ICP) to operate on Neural Radiance Fields (NeRF) -- neural 3D scene representations trained from collections of calibrated images. NeRF does not decompose illumination and color, so to make registration invariant to illumination, we introduce the concept of a ''surface field'' -- a field distilled from a pre-trained NeRF model that measures the likelihood of a point being on the surface of an object. We then cast nerf2nerf registration as a robust optimization that iteratively seeks a rigid transformation that aligns the surface fields of the two scenes. We evaluate the effectiveness of our technique by introducing a dataset of pre-trained NeRF scenes -- our synthetic scenes enable quantitative evaluations and comparisons to classical registration techniques, while our real scenes demonstrate the validity of our technique in real-world scenarios. Additional results available at: https://nerf2nerf.github.io
Attention Beats Concatenation for Conditioning Neural Fields
Sep 21, 2022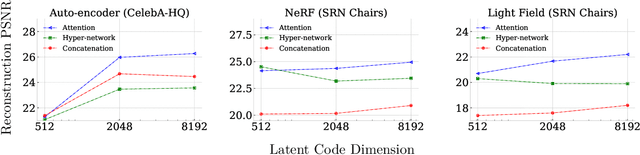


Neural fields model signals by mapping coordinate inputs to sampled values. They are becoming an increasingly important backbone architecture across many fields from vision and graphics to biology and astronomy. In this paper, we explore the differences between common conditioning mechanisms within these networks, an essential ingredient in shifting neural fields from memorization of signals to generalization, where the set of signals lying on a manifold is modelled jointly. In particular, we are interested in the scaling behaviour of these mechanisms to increasingly high-dimensional conditioning variables. As we show in our experiments, high-dimensional conditioning is key to modelling complex data distributions, thus it is important to determine what architecture choices best enable this when working on such problems. To this end, we run experiments modelling 2D, 3D, and 4D signals with neural fields, employing concatenation, hyper-network, and attention-based conditioning strategies -- a necessary but laborious effort that has not been performed in the literature. We find that attention-based conditioning outperforms other approaches in a variety of settings.
NeuralBF: Neural Bilateral Filtering for Top-down Instance Segmentation on Point Clouds
Jul 20, 2022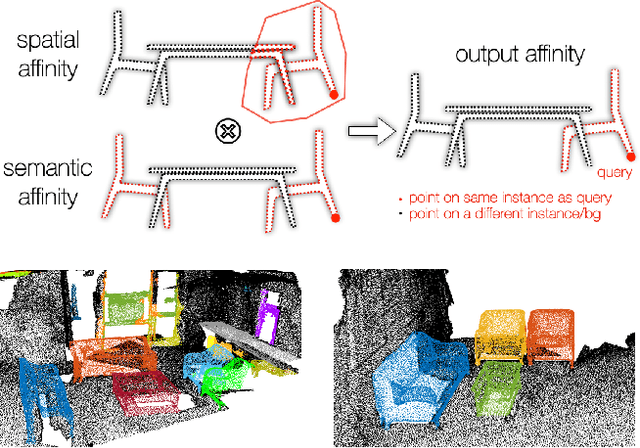
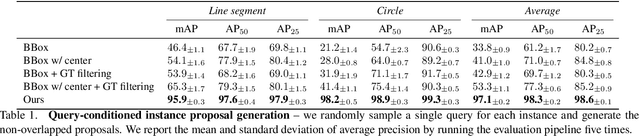

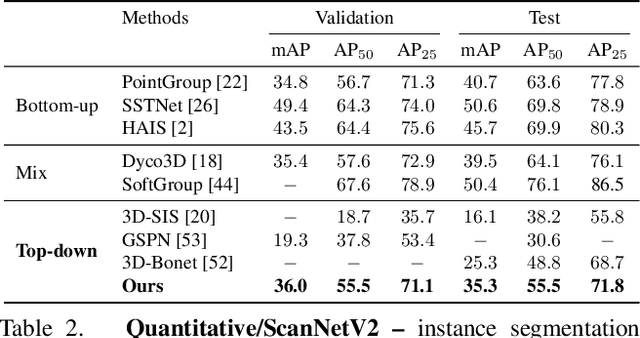
We introduce a method for instance proposal generation for 3D point clouds. Existing techniques typically directly regress proposals in a single feed-forward step, leading to inaccurate estimation. We show that this serves as a critical bottleneck, and propose a method based on iterative bilateral filtering with learned kernels. Following the spirit of bilateral filtering, we consider both the deep feature embeddings of each point, as well as their locations in the 3D space. We show via synthetic experiments that our method brings drastic improvements when generating instance proposals for a given point of interest. We further validate our method on the challenging ScanNet benchmark, achieving the best instance segmentation performance amongst the sub-category of top-down methods.
Kubric: A scalable dataset generator
Mar 07, 2022

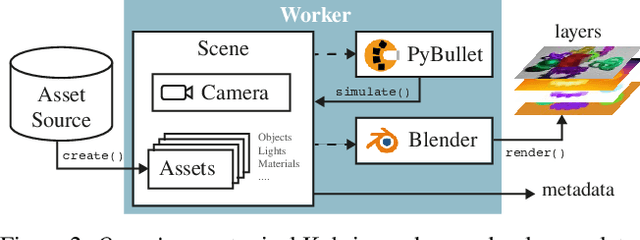
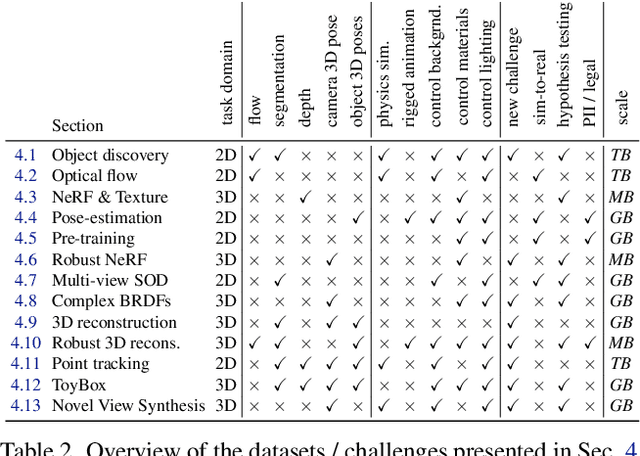
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
LOLNeRF: Learn from One Look
Nov 19, 2021
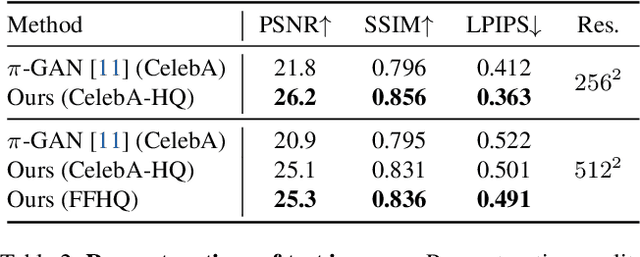


We present a method for learning a generative 3D model based on neural radiance fields, trained solely from data with only single views of each object. While generating realistic images is no longer a difficult task, producing the corresponding 3D structure such that they can be rendered from different views is non-trivial. We show that, unlike existing methods, one does not need multi-view data to achieve this goal. Specifically, we show that by reconstructing many images aligned to an approximate canonical pose with a single network conditioned on a shared latent space, you can learn a space of radiance fields that models shape and appearance for a class of objects. We demonstrate this by training models to reconstruct object categories using datasets that contain only one view of each subject without depth or geometry information. Our experiments show that we achieve state-of-the-art results in novel view synthesis and competitive results for monocular depth prediction.