 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLiu
The Model Openness Framework: Promoting Completeness and Openness for Reproducibility, Transparency and Usability in AI
Mar 21, 2024
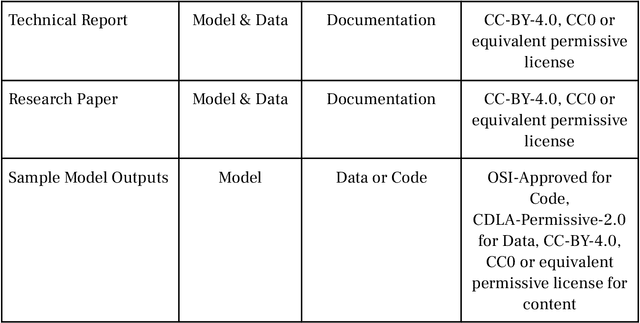

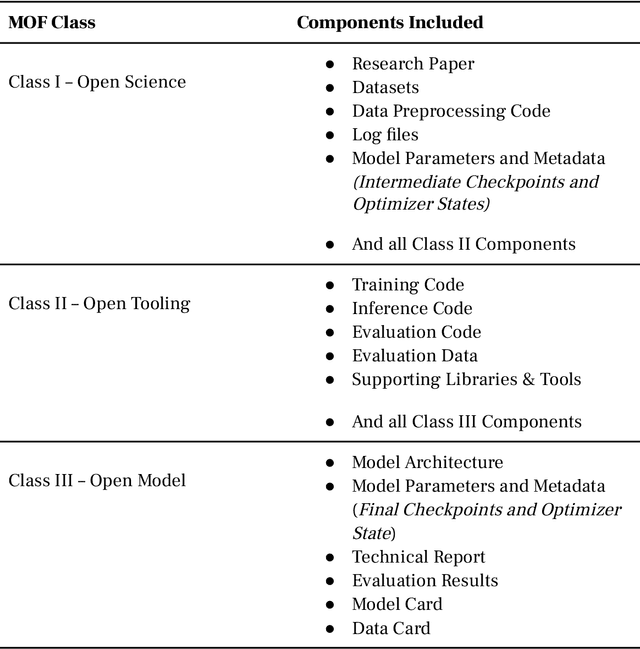
Generative AI (GAI) offers unprecedented possibilities but its commercialization has raised concerns about transparency, reproducibility, bias, and safety. Many "open-source" GAI models lack the necessary components for full understanding and reproduction, and some use restrictive licenses, a practice known as "openwashing." We propose the Model Openness Framework (MOF), a ranked classification system that rates machine learning models based on their completeness and openness, following principles of open science, open source, open data, and open access. The MOF requires specific components of the model development lifecycle to be included and released under appropriate open licenses. This framework aims to prevent misrepresentation of models claiming to be open, guide researchers and developers in providing all model components under permissive licenses, and help companies, academia, and hobbyists identify models that can be safely adopted without restrictions. Wide adoption of the MOF will foster a more open AI ecosystem, accelerating research, innovation, and adoption.
On the Channel Correlation in Reconfigurable Intelligent Surface-Aided System
May 03, 2023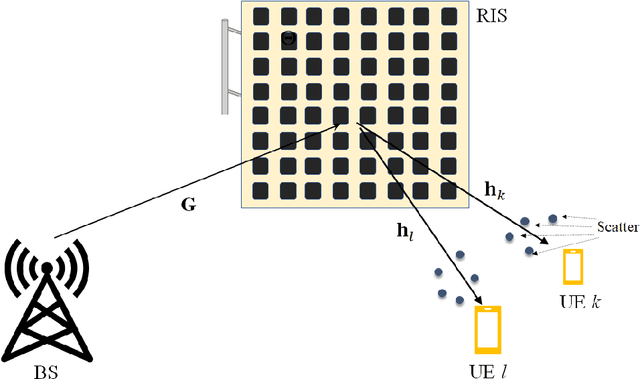
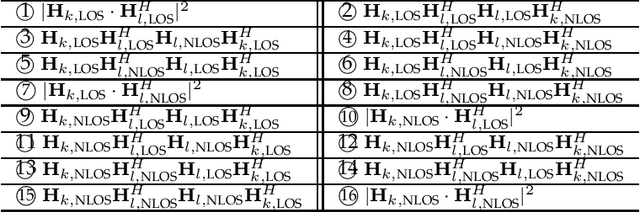
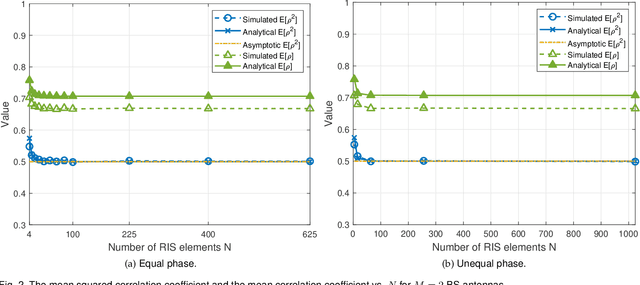

This works explores the correlation between channels in reconfigurable intelligent surface (RIS)-aided communication systems. In this type of system, an RIS made up of many passive elements with adjustable phases reflects the transmitter's signal to the receiver. Since the transmitter-RIS link may be shared by multiple receivers, the cascade channels of two receivers may experience correlated fading, which can negatively impact system performance. Using the mean correlation coefficient as a metric, we analyze the correlation between two cascade channels and derive an accurate approximation in closed form. We also consider the extreme case of an infinitely large number of RIS elements and obtain a convergence result. Our analysis accuracy is validated by simulation results, which offer insights into the correlation characteristics of RIS-aided fading channels.
Research on Parallel SVM Algorithm Based on Cascade SVM
Mar 11, 2022

Cascade SVM (CSVM) can group datasets and train subsets in parallel, which greatly reduces the training time and memory consumption. However, the model accuracy obtained by using this method has some errors compared with direct training. In order to reduce the error, we analyze the causes of error in grouping training, and summarize the grouping without error under ideal conditions. A Balanced Cascade SVM (BCSVM) algorithm is proposed, which balances the sample proportion in the subset after grouping to ensure that the sample proportion in the subset is the same as the original dataset. At the same time, it proves that the accuracy of the model obtained by BCSVM algorithm is higher than that of CSVM. Finally, two common datasets are used for experimental verification, and the results show that the accuracy error obtained by using BCSVM algorithm is reduced from 1% of CSVM to 0.1%, which is reduced by an order of magnitude.
Kubric: A scalable dataset generator
Mar 07, 2022

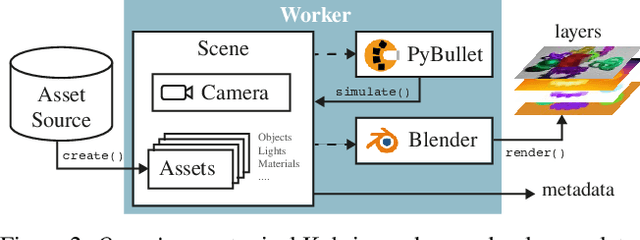
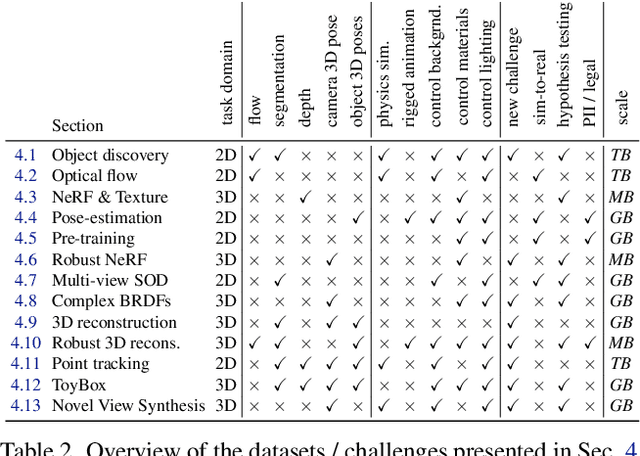
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
Active Learning for Contextual Search with Binary Feedbacks
Oct 03, 2021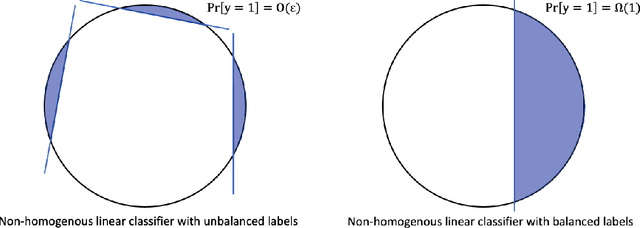
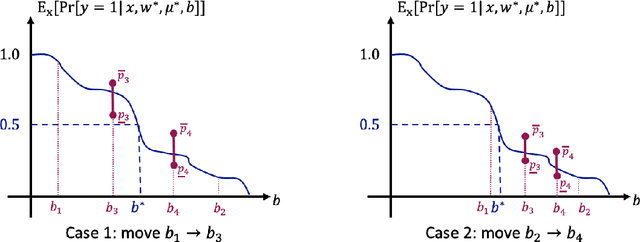
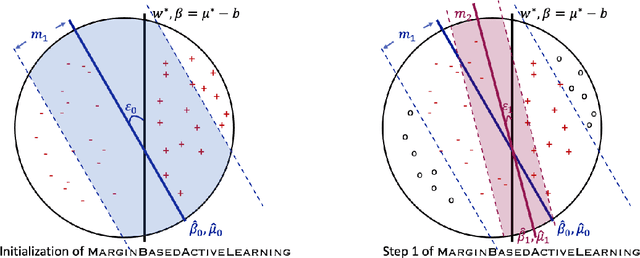
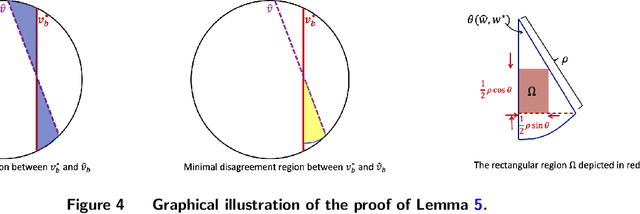
In this paper, we study the learning problem in contextual search, which is motivated by applications such as first-price auction, personalized medicine experiments, and feature-based pricing experiments. In particular, for a sequence of arriving context vectors, with each context associated with an underlying value, the decision-maker either makes a query at a certain point or skips the context. The decision-maker will only observe the binary feedback on the relationship between the query point and the value associated with the context. We study a PAC learning setting, where the goal is to learn the underlying mean value function in context with a minimum number of queries. To address this challenge, we propose a tri-section search approach combined with a margin-based active learning method. We show that the algorithm only needs to make $O(1/\varepsilon^2)$ queries to achieve an $\epsilon$-estimation accuracy. This sample complexity significantly reduces the required sample complexity in the passive setting, at least $\Omega(1/\varepsilon^4)$.
A Smoothed Analysis of Online Lasso for the Sparse Linear Contextual Bandit Problem
Jul 16, 2020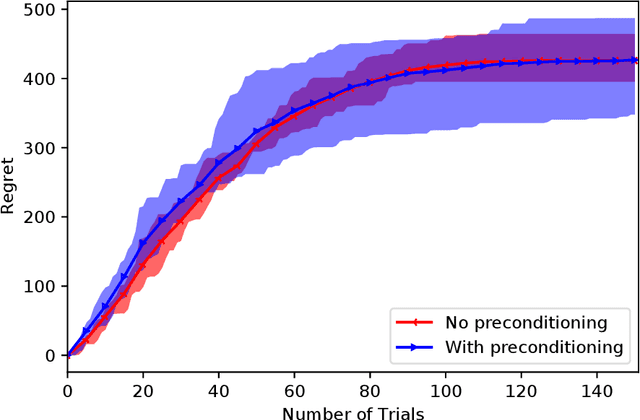
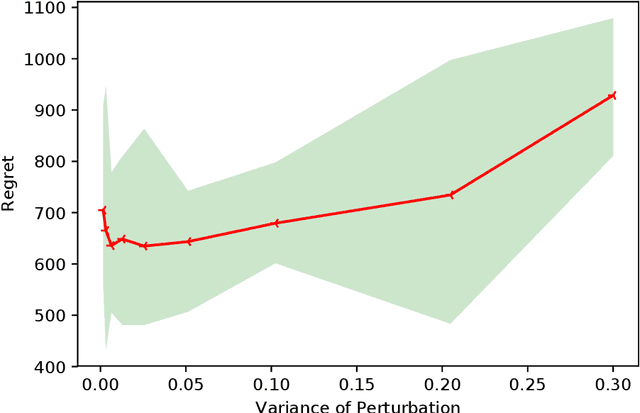
We investigate the sparse linear contextual bandit problem where the parameter $\theta$ is sparse. To relieve the sampling inefficiency, we utilize the "perturbed adversary" where the context is generated adversarilly but with small random non-adaptive perturbations. We prove that the simple online Lasso supports sparse linear contextual bandit with regret bound $\mathcal{O}(\sqrt{kT\log d})$ even when $d \gg T$ where $k$ and $d$ are the number of effective and ambient dimension, respectively. Compared to the recent work from Sivakumar et al. (2020), our analysis does not rely on the precondition processing, adaptive perturbation (the adaptive perturbation violates the i.i.d perturbation setting) or truncation on the error set. Moreover, the special structures in our results explicitly characterize how the perturbation affects exploration length, guide the design of perturbation together with the fundamental performance limit of perturbation method. Numerical experiments are provided to complement the theoretical analysis.
Enhanced Robot Speech Recognition Using Biomimetic Binaural Sound Source Localization
Feb 13, 2019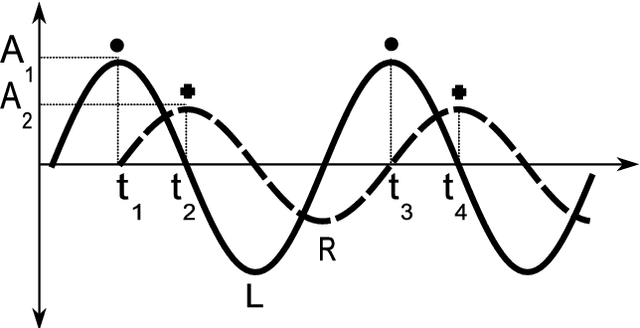
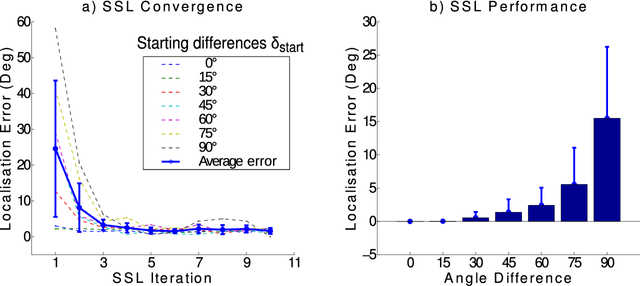
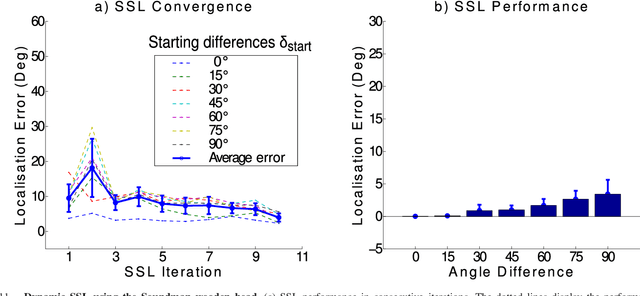
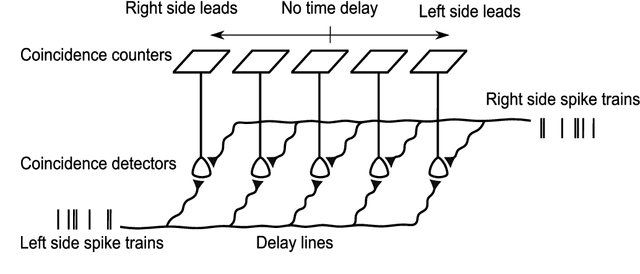
Inspired by the behavior of humans talking in noisy environments, we propose an embodied embedded cognition approach to improve automatic speech recognition (ASR) systems for robots in challenging environments, such as with ego noise, using binaural sound source localization (SSL). The approach is verified by measuring the impact of SSL with a humanoid robot head on the performance of an ASR system. More specifically, a robot orients itself toward the angle where the signal-to-noise ratio (SNR) of speech is maximized for one microphone before doing an ASR task. First, a spiking neural network inspired by the midbrain auditory system based on our previous work is applied to calculate the sound signal angle. Then, a feedforward neural network is used to handle high levels of ego noise and reverberation in the signal. Finally, the sound signal is fed into an ASR system. For ASR, we use a system developed by our group and compare its performance with and without the support from SSL. We test our SSL and ASR systems on two humanoid platforms with different structural and material properties. With our approach we halve the sentence error rate with respect to the common downmixing of both channels. Surprisingly, the ASR performance is more than two times better when the angle between the humanoid head and the sound source allows sound waves to be reflected most intensely from the pinna to the ear microphone, rather than when sound waves arrive perpendicularly to the membrane.