 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoha Radwan
Kubric: A scalable dataset generator
Mar 07, 2022


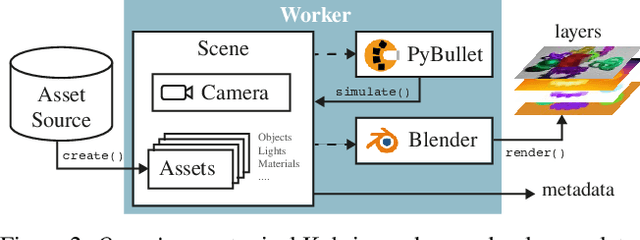
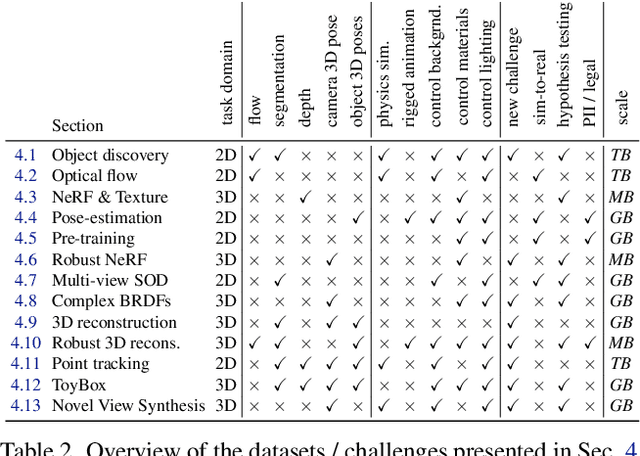
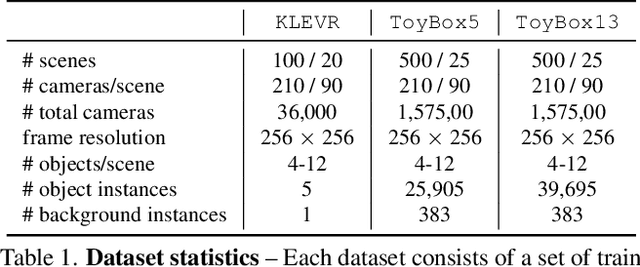
Data is the driving force of machine learning, with the amount and quality of training data often being more important for the performance of a system than architecture and training details. But collecting, processing and annotating real data at scale is difficult, expensive, and frequently raises additional privacy, fairness and legal concerns. Synthetic data is a powerful tool with the potential to address these shortcomings: 1) it is cheap 2) supports rich ground-truth annotations 3) offers full control over data and 4) can circumvent or mitigate problems regarding bias, privacy and licensing. Unfortunately, software tools for effective data generation are less mature than those for architecture design and training, which leads to fragmented generation efforts. To address these problems we introduce Kubric, an open-source Python framework that interfaces with PyBullet and Blender to generate photo-realistic scenes, with rich annotations, and seamlessly scales to large jobs distributed over thousands of machines, and generating TBs of data. We demonstrate the effectiveness of Kubric by presenting a series of 13 different generated datasets for tasks ranging from studying 3D NeRF models to optical flow estimation. We release Kubric, the used assets, all of the generation code, as well as the rendered datasets for reuse and modification.
NeSF: Neural Semantic Fields for Generalizable Semantic Segmentation of 3D Scenes
Dec 03, 2021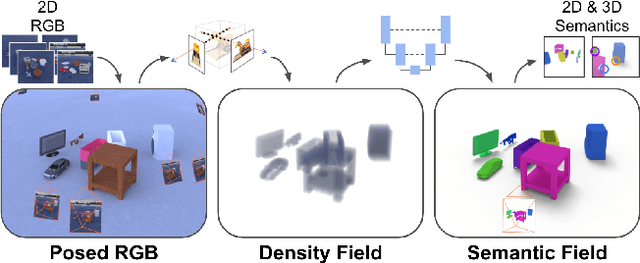

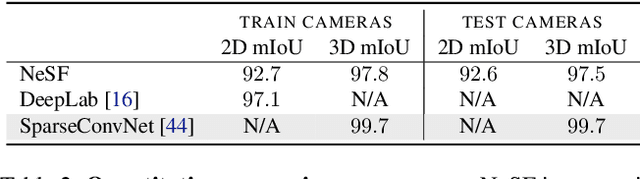
We present NeSF, a method for producing 3D semantic fields from posed RGB images alone. In place of classical 3D representations, our method builds on recent work in implicit neural scene representations wherein 3D structure is captured by point-wise functions. We leverage this methodology to recover 3D density fields upon which we then train a 3D semantic segmentation model supervised by posed 2D semantic maps. Despite being trained on 2D signals alone, our method is able to generate 3D-consistent semantic maps from novel camera poses and can be queried at arbitrary 3D points. Notably, NeSF is compatible with any method producing a density field, and its accuracy improves as the quality of the density field improves. Our empirical analysis demonstrates comparable quality to competitive 2D and 3D semantic segmentation baselines on complex, realistically rendered synthetic scenes. Our method is the first to offer truly dense 3D scene segmentations requiring only 2D supervision for training, and does not require any semantic input for inference on novel scenes. We encourage the readers to visit the project website.
RegNeRF: Regularizing Neural Radiance Fields for View Synthesis from Sparse Inputs
Dec 01, 2021

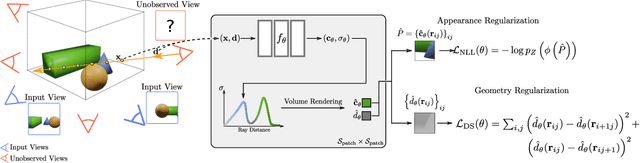
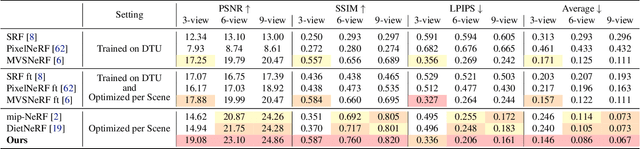
Neural Radiance Fields (NeRF) have emerged as a powerful representation for the task of novel view synthesis due to their simplicity and state-of-the-art performance. Though NeRF can produce photorealistic renderings of unseen viewpoints when many input views are available, its performance drops significantly when this number is reduced. We observe that the majority of artifacts in sparse input scenarios are caused by errors in the estimated scene geometry, and by divergent behavior at the start of training. We address this by regularizing the geometry and appearance of patches rendered from unobserved viewpoints, and annealing the ray sampling space during training. We additionally use a normalizing flow model to regularize the color of unobserved viewpoints. Our model outperforms not only other methods that optimize over a single scene, but in many cases also conditional models that are extensively pre-trained on large multi-view datasets.
Scene Representation Transformer: Geometry-Free Novel View Synthesis Through Set-Latent Scene Representations
Nov 29, 2021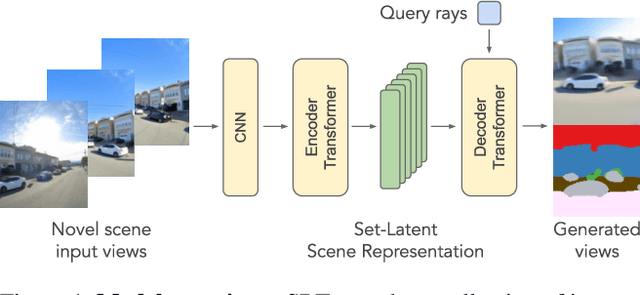

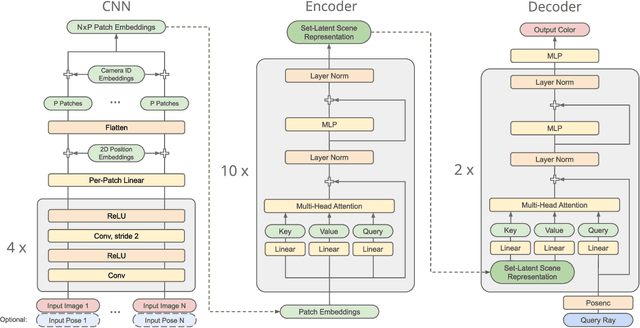
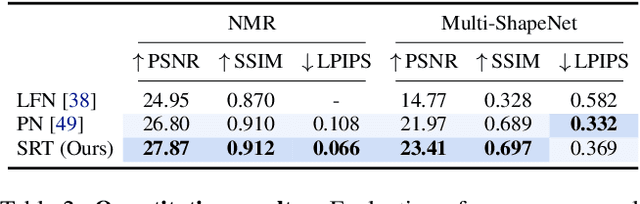
A classical problem in computer vision is to infer a 3D scene representation from few images that can be used to render novel views at interactive rates. Previous work focuses on reconstructing pre-defined 3D representations, e.g. textured meshes, or implicit representations, e.g. radiance fields, and often requires input images with precise camera poses and long processing times for each novel scene. In this work, we propose the Scene Representation Transformer (SRT), a method which processes posed or unposed RGB images of a new area, infers a "set-latent scene representation", and synthesises novel views, all in a single feed-forward pass. To calculate the scene representation, we propose a generalization of the Vision Transformer to sets of images, enabling global information integration, and hence 3D reasoning. An efficient decoder transformer parameterizes the light field by attending into the scene representation to render novel views. Learning is supervised end-to-end by minimizing a novel-view reconstruction error. We show that this method outperforms recent baselines in terms of PSNR and speed on synthetic datasets, including a new dataset created for the paper. Further, we demonstrate that SRT scales to support interactive visualization and semantic segmentation of real-world outdoor environments using Street View imagery.
NeRF in the Wild: Neural Radiance Fields for Unconstrained Photo Collections
Aug 13, 2020
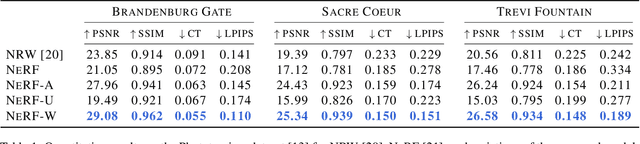

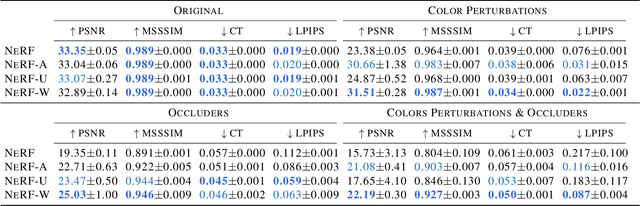
We present a learning-based method for synthesizing novel views of complex outdoor scenes using only unstructured collections of in-the-wild photographs. We build on neural radiance fields (NeRF), which uses the weights of a multilayer perceptron to implicitly model the volumetric density and color of a scene. While NeRF works well on images of static subjects captured under controlled settings, it is incapable of modeling many ubiquitous, real-world phenomena in uncontrolled images, such as variable illumination or transient occluders. In this work, we introduce a series of extensions to NeRF to address these issues, thereby allowing for accurate reconstructions from unstructured image collections taken from the internet. We apply our system, which we dub NeRF-W, to internet photo collections of famous landmarks, thereby producing photorealistic, spatially consistent scene representations despite unknown and confounding factors, resulting in significant improvement over the state of the art.
VLocNet++: Deep Multitask Learning for Semantic Visual Localization and Odometry
Oct 11, 2018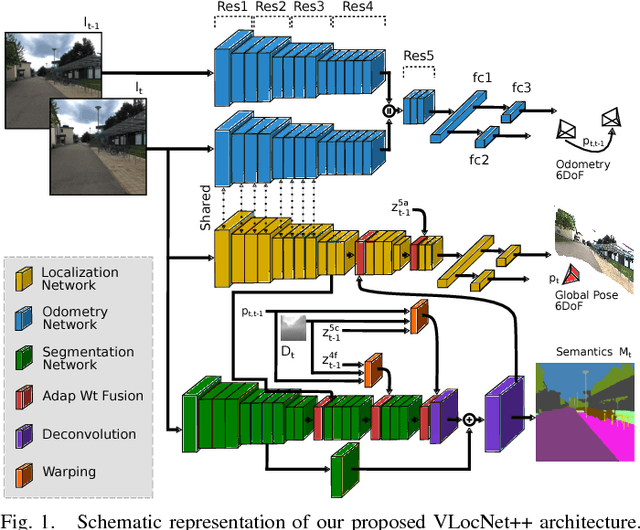



Semantic understanding and localization are fundamental enablers of robot autonomy that have for the most part been tackled as disjoint problems. While deep learning has enabled recent breakthroughs across a wide spectrum of scene understanding tasks, its applicability to state estimation tasks has been limited due to the direct formulation that renders it incapable of encoding scene-specific constrains. In this work, we propose the VLocNet++ architecture that employs a multitask learning approach to exploit the inter-task relationship between learning semantics, regressing 6-DoF global pose and odometry, for the mutual benefit of each of these tasks. Our network overcomes the aforementioned limitation by simultaneously embedding geometric and semantic knowledge of the world into the pose regression network. We propose a novel adaptive weighted fusion layer to aggregate motion-specific temporal information and to fuse semantic features into the localization stream based on region activations. Furthermore, we propose a self-supervised warping technique that uses the relative motion to warp intermediate network representations in the segmentation stream for learning consistent semantics. Finally, we introduce a first-of-a-kind urban outdoor localization dataset with pixel-level semantic labels and multiple loops for training deep networks. Extensive experiments on the challenging Microsoft 7-Scenes benchmark and our DeepLoc dataset demonstrate that our approach exceeds the state-of-the-art outperforming local feature-based methods while simultaneously performing multiple tasks and exhibiting substantial robustness in challenging scenarios.
* Demo and dataset available at http://deeploc.cs.uni-freiburg.de
Multimodal Interaction-aware Motion Prediction for Autonomous Street Crossing
Aug 22, 2018

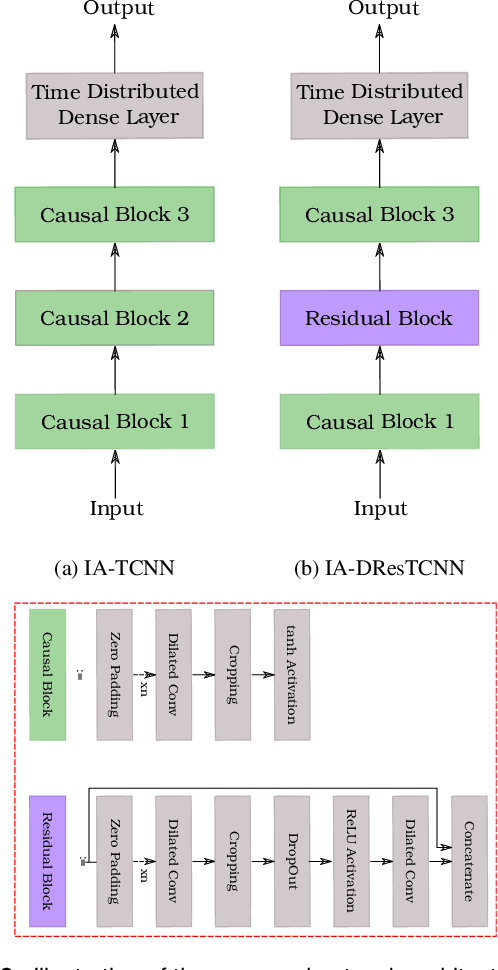
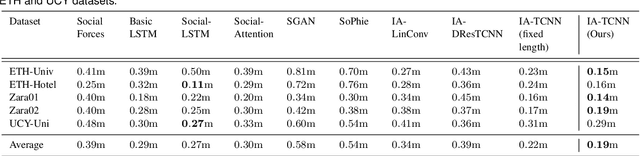
For mobile robots navigating on sidewalks, it is essential to be able to safely cross street intersections. Most existing approaches rely on the recognition of the traffic light signal to make an informed crossing decision. Although these approaches have been crucial enablers for urban navigation, the capabilities of robots employing such approaches are still limited to navigating only on streets containing signalized intersections. In this paper, we address this challenge and propose a multimodal convolutional neural network framework to predict the safety of a street intersection for crossing. Our architecture consists of two subnetworks; an interaction-aware trajectory estimation stream IA-TCNN, that predicts the future states of all observed traffic participants in the scene, and a traffic light recognition stream AtteNet. Our IA-TCNN utilizes dilated causal convolutions to model the behavior of the observable dynamic agents in the scene without explicitly assigning priorities to the interactions among them. While AtteNet utilizes Squeeze-Excitation blocks to learn a content-aware mechanism for selecting the relevant features from the data, thereby improving the noise robustness. Learned representations from the traffic light recognition stream are fused with the estimated trajectories from the motion prediction stream to learn the crossing decision. Furthermore, we extend our previously introduced Freiburg Street Crossing dataset with sequences captured at different types of intersections, demonstrating complex interactions among the traffic participants. Extensive experimental evaluations on public benchmark datasets and our proposed dataset demonstrate that our network achieves state-of-the-art performance for each of the subtasks, as well as for the crossing safety prediction.
Deep Auxiliary Learning for Visual Localization and Odometry
Mar 09, 2018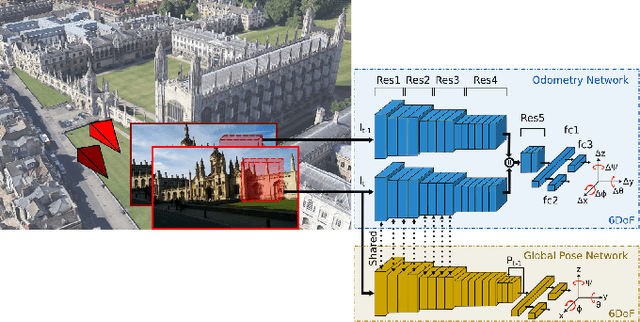

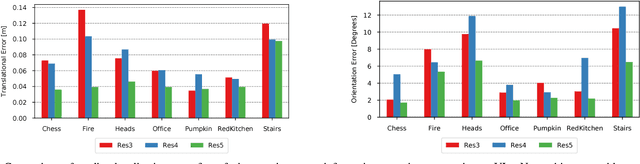
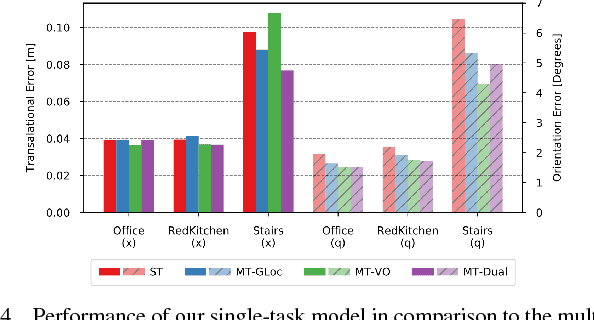
Localization is an indispensable component of a robot's autonomy stack that enables it to determine where it is in the environment, essentially making it a precursor for any action execution or planning. Although convolutional neural networks have shown promising results for visual localization, they are still grossly outperformed by state-of-the-art local feature-based techniques. In this work, we propose VLocNet, a new convolutional neural network architecture for 6-DoF global pose regression and odometry estimation from consecutive monocular images. Our multitask model incorporates hard parameter sharing, thus being compact and enabling real-time inference, in addition to being end-to-end trainable. We propose a novel loss function that utilizes auxiliary learning to leverage relative pose information during training, thereby constraining the search space to obtain consistent pose estimates. We evaluate our proposed VLocNet on indoor as well as outdoor datasets and show that even our single task model exceeds the performance of state-of-the-art deep architectures for global localization, while achieving competitive performance for visual odometry estimation. Furthermore, we present extensive experimental evaluations utilizing our proposed Geometric Consistency Loss that show the effectiveness of multitask learning and demonstrate that our model is the first deep learning technique to be on par with, and in some cases outperforms state-of-the-art SIFT-based approaches.
Why did the Robot Cross the Road? - Learning from Multi-Modal Sensor Data for Autonomous Road Crossing
Sep 18, 2017
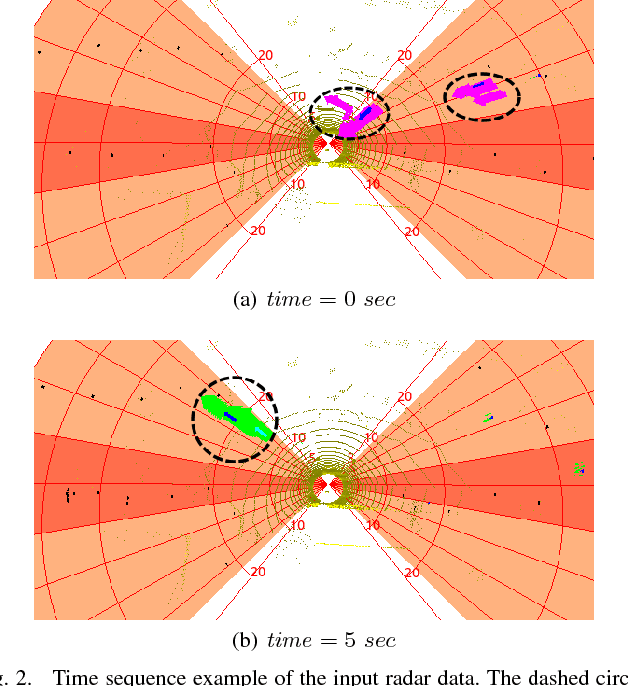


We consider the problem of developing robots that navigate like pedestrians on sidewalks through city centers for performing various tasks including delivery and surveillance. One particular challenge for such robots is crossing streets without pedestrian traffic lights. To solve this task the robot has to decide based on its sensory input if the road is clear. In this work, we propose a novel multi-modal learning approach for the problem of autonomous street crossing. Our approach solely relies on laser and radar data and learns a classifier based on Random Forests to predict when it is safe to cross the road. We present extensive experimental evaluations using real-world data collected from multiple street crossing situations which demonstrate that our approach yields a safe and accurate street crossing behavior and generalizes well over different types of situations. A comparison to alternative methods demonstrates the advantages of our approach.
Topometric Localization with Deep Learning
Jun 27, 2017
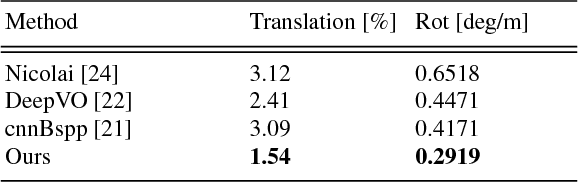
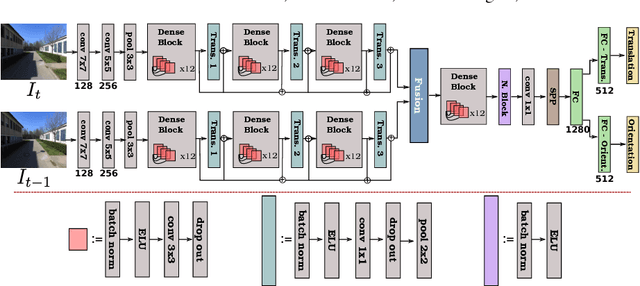
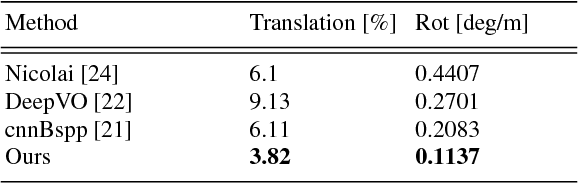
Compared to LiDAR-based localization methods, which provide high accuracy but rely on expensive sensors, visual localization approaches only require a camera and thus are more cost-effective while their accuracy and reliability typically is inferior to LiDAR-based methods. In this work, we propose a vision-based localization approach that learns from LiDAR-based localization methods by using their output as training data, thus combining a cheap, passive sensor with an accuracy that is on-par with LiDAR-based localization. The approach consists of two deep networks trained on visual odometry and topological localization, respectively, and a successive optimization to combine the predictions of these two networks. We evaluate the approach on a new challenging pedestrian-based dataset captured over the course of six months in varying weather conditions with a high degree of noise. The experiments demonstrate that the localization errors are up to 10 times smaller than with traditional vision-based localization methods.