 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaochen Jiang
OpenOcc: Open Vocabulary 3D Scene Reconstruction via Occupancy Representation
Mar 18, 2024

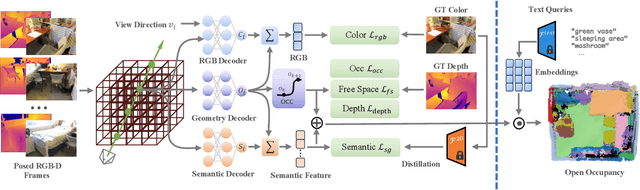
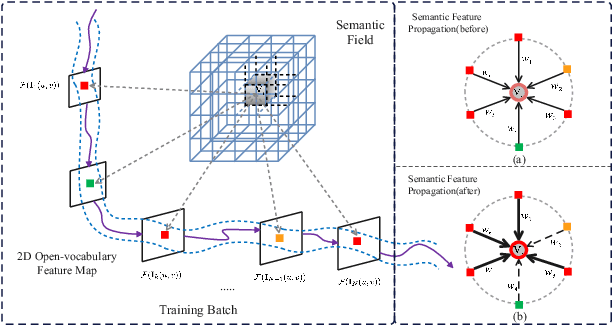
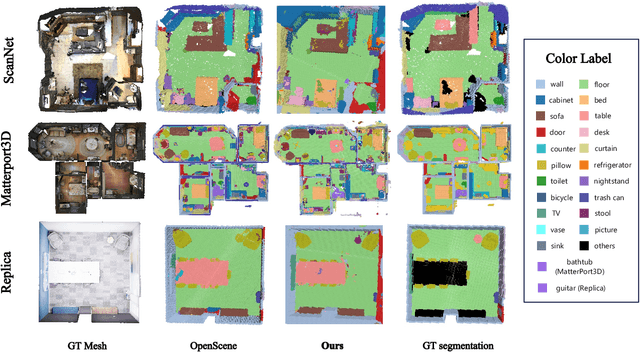
3D reconstruction has been widely used in autonomous navigation fields of mobile robotics. However, the former research can only provide the basic geometry structure without the capability of open-world scene understanding, limiting advanced tasks like human interaction and visual navigation. Moreover, traditional 3D scene understanding approaches rely on expensive labeled 3D datasets to train a model for a single task with supervision. Thus, geometric reconstruction with zero-shot scene understanding i.e. Open vocabulary 3D Understanding and Reconstruction, is crucial for the future development of mobile robots. In this paper, we propose OpenOcc, a novel framework unifying the 3D scene reconstruction and open vocabulary understanding with neural radiance fields. We model the geometric structure of the scene with occupancy representation and distill the pre-trained open vocabulary model into a 3D language field via volume rendering for zero-shot inference. Furthermore, a novel semantic-aware confidence propagation (SCP) method has been proposed to relieve the issue of language field representation degeneracy caused by inconsistent measurements in distilled features. Experimental results show that our approach achieves competitive performance in 3D scene understanding tasks, especially for small and long-tail objects.
NaSGEC: a Multi-Domain Chinese Grammatical Error Correction Dataset from Native Speaker Texts
May 25, 2023



We introduce NaSGEC, a new dataset to facilitate research on Chinese grammatical error correction (CGEC) for native speaker texts from multiple domains. Previous CGEC research primarily focuses on correcting texts from a single domain, especially learner essays. To broaden the target domain, we annotate multiple references for 12,500 sentences from three native domains, i.e., social media, scientific writing, and examination. We provide solid benchmark results for NaSGEC by employing cutting-edge CGEC models and different training data. We further perform detailed analyses of the connections and gaps between our domains from both empirical and statistical views. We hope this work can inspire future studies on an important but under-explored direction--cross-domain GEC.
Mining Error Templates for Grammatical Error Correction
Jun 23, 2022



Some grammatical error correction (GEC) systems incorporate hand-crafted rules and achieve positive results. However, manually defining rules is time-consuming and laborious. In view of this, we propose a method to mine error templates for GEC automatically. An error template is a regular expression aiming at identifying text errors. We use the web crawler to acquire such error templates from the Internet. For each template, we further select the corresponding corrective action by using the language model perplexity as a criterion. We have accumulated 1,119 error templates for Chinese GEC based on this method. Experimental results on the newly proposed CTC-2021 Chinese GEC benchmark show that combing our error templates can effectively improve the performance of a strong GEC system, especially on two error types with very little training data. Our error templates are available at \url{https://github.com/HillZhang1999/gec_error_template}.