 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuang
Field Testing of a Stochastic Planner for ASV Navigation Using Satellite Images
Sep 26, 2023

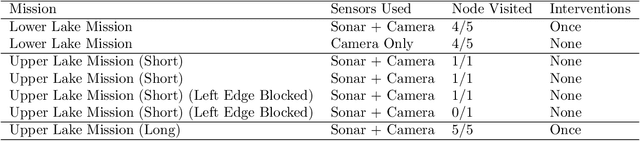
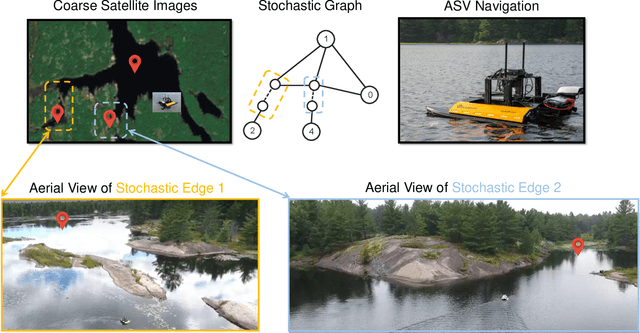

We introduce a multi-sensor navigation system for autonomous surface vessels (ASV) intended for water-quality monitoring in freshwater lakes. Our mission planner uses satellite imagery as a prior map, formulating offline a mission-level policy for global navigation of the ASV and enabling autonomous online execution via local perception and local planning modules. A significant challenge is posed by the inconsistencies in traversability estimation between satellite images and real lakes, due to environmental effects such as wind, aquatic vegetation, shallow waters, and fluctuating water levels. Hence, we specifically modelled these traversability uncertainties as stochastic edges in a graph and optimized for a mission-level policy that minimizes the expected total travel distance. To execute the policy, we propose a modern local planner architecture that processes sensor inputs and plans paths to execute the high-level policy under uncertain traversability conditions. Our system was tested on three km-scale missions on a Northern Ontario lake, demonstrating that our GPS-, vision-, and sonar-enabled ASV system can effectively execute the mission-level policy and disambiguate the traversability of stochastic edges. Finally, we provide insights gained from practical field experience and offer several future directions to enhance the overall reliability of ASV navigation systems.
Nationality Bias in Text Generation
Feb 11, 2023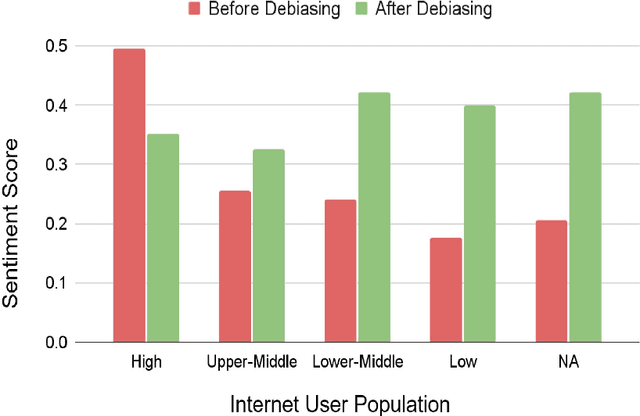


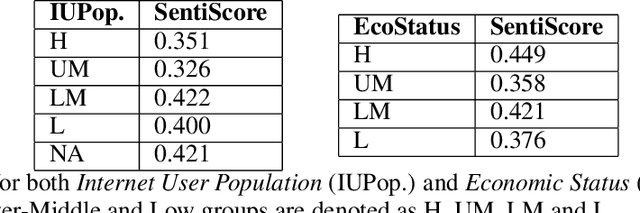
Little attention is placed on analyzing nationality bias in language models, especially when nationality is highly used as a factor in increasing the performance of social NLP models. This paper examines how a text generation model, GPT-2, accentuates pre-existing societal biases about country-based demonyms. We generate stories using GPT-2 for various nationalities and use sensitivity analysis to explore how the number of internet users and the country's economic status impacts the sentiment of the stories. To reduce the propagation of biases through large language models (LLM), we explore the debiasing method of adversarial triggering. Our results show that GPT-2 demonstrates significant bias against countries with lower internet users, and adversarial triggering effectively reduces the same.
Graph Neural Networks for Community Detection on Sparse Graphs
Nov 06, 2022
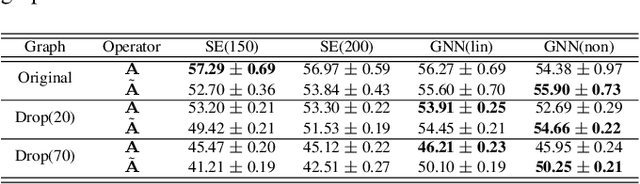
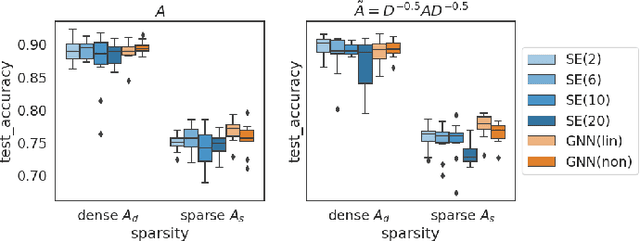
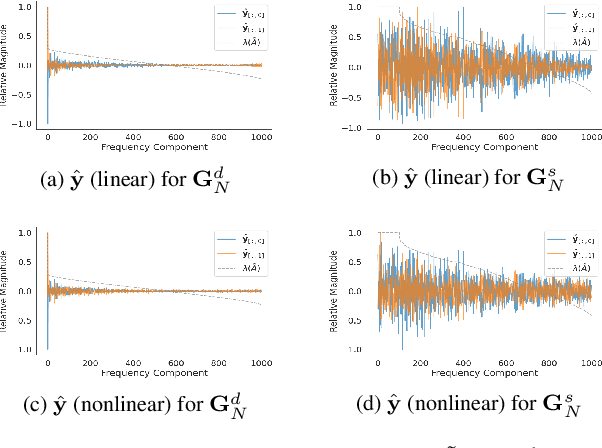
Spectral methods provide consistent estimators for community detection in dense graphs. However, their performance deteriorates as the graphs become sparser. In this work we consider a random graph model that can produce graphs at different levels of sparsity, and we show that graph neural networks can outperform spectral methods on sparse graphs. We illustrate the results with numerical examples in both synthetic and real graphs.
Masked Autoencoders that Listen
Jul 13, 2022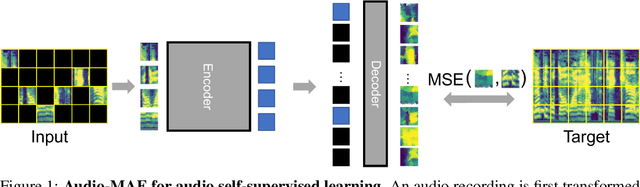
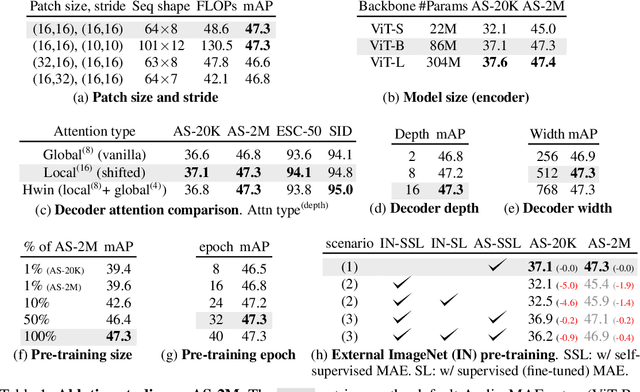

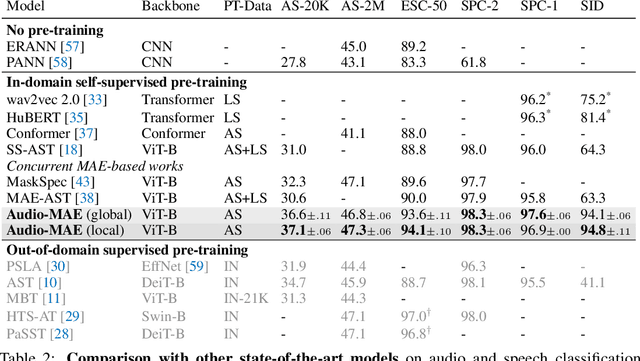
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
On Adversarial Robustness of Large-scale Audio Visual Learning
Mar 23, 2022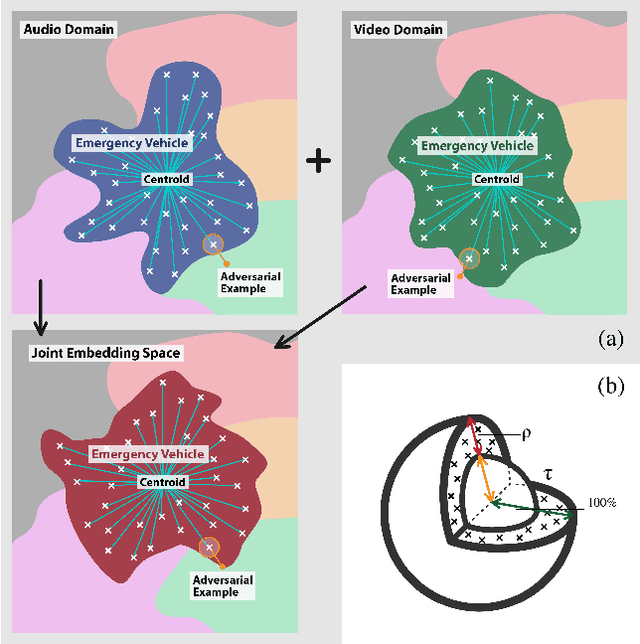
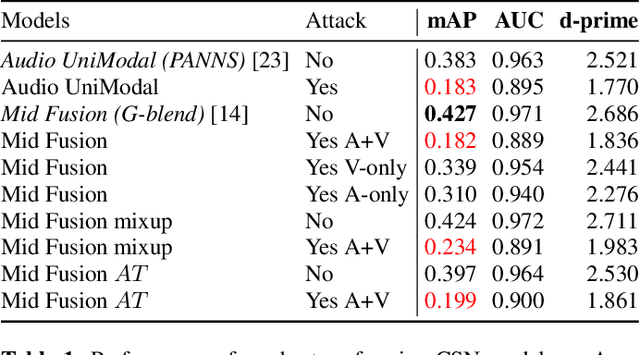
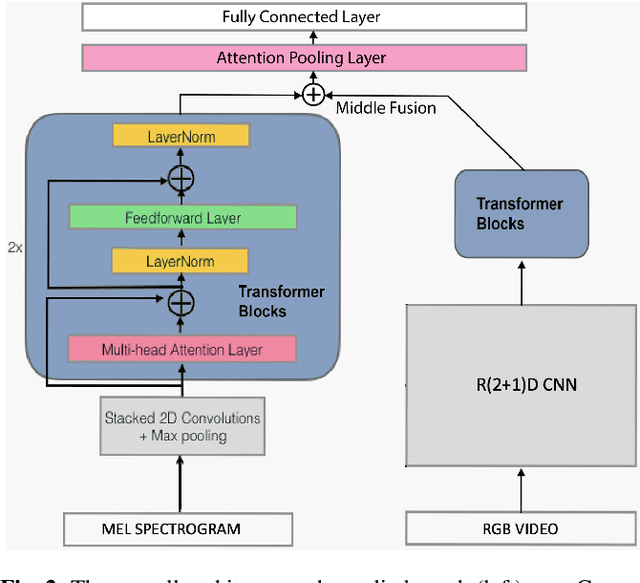
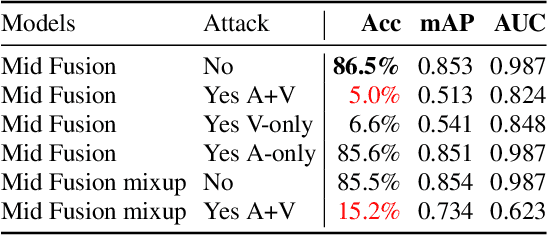
As audio-visual systems are being deployed for safety-critical tasks such as surveillance and malicious content filtering, their robustness remains an under-studied area. Existing published work on robustness either does not scale to large-scale dataset, or does not deal with multiple modalities. This work aims to study several key questions related to multi-modal learning through the lens of robustness: 1) Are multi-modal models necessarily more robust than uni-modal models? 2) How to efficiently measure the robustness of multi-modal learning? 3) How to fuse different modalities to achieve a more robust multi-modal model? To understand the robustness of the multi-modal model in a large-scale setting, we propose a density-based metric, and a convexity metric to efficiently measure the distribution of each modality in high-dimensional latent space. Our work provides a theoretical intuition together with empirical evidence showing how multi-modal fusion affects adversarial robustness through these metrics. We further devise a mix-up strategy based on our metrics to improve the robustness of the trained model. Our experiments on AudioSet and Kinetics-Sounds verify our hypothesis that multi-modal models are not necessarily more robust than their uni-modal counterparts in the face of adversarial examples. We also observe our mix-up trained method could achieve as much protection as traditional adversarial training, offering a computationally cheap alternative. Implementation: https://github.com/lijuncheng16/AudioSetDoneRight
Design of EMG-driven Musculoskeletal Model for Volitional Control of a Robotic Ankle Prosthesis
Feb 17, 2022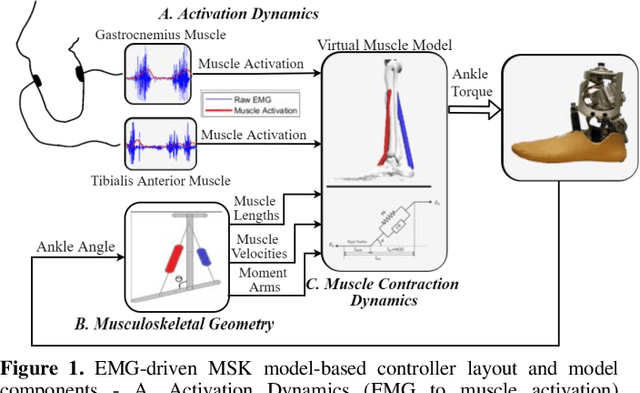
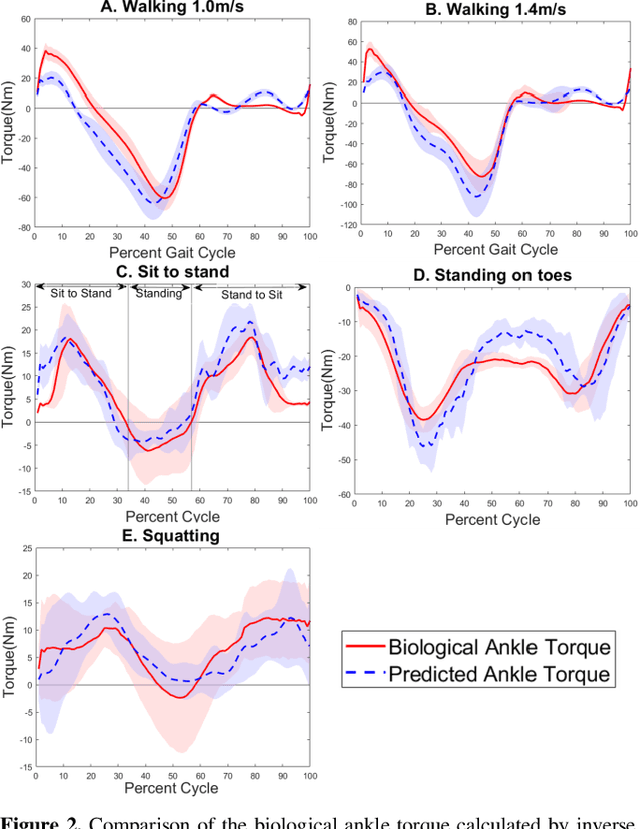
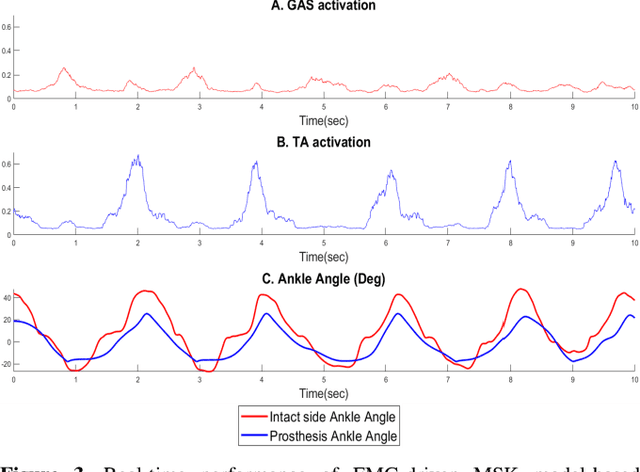
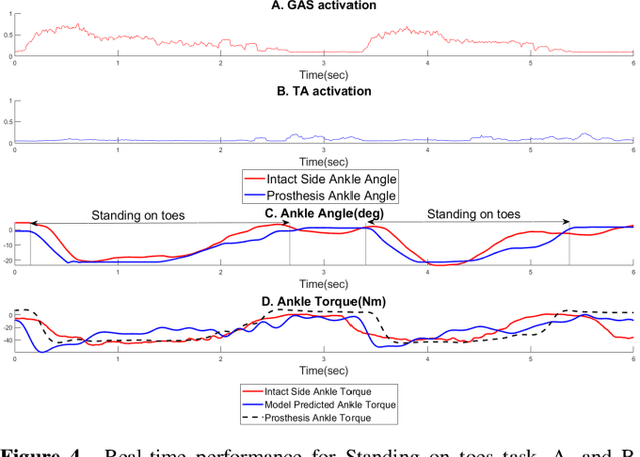
Existing robotic lower-limb prostheses use autonomous control to address cyclic, locomotive tasks, but they are inadequate to operate the prosthesis for daily activities that are non-cyclic and unpredictable. To address this challenge, this study aims to design a novel electromyography (EMG)-driven musculoskeletal model for volitional control of a robotic ankle-foot prosthesis. This controller places the user in continuous control of the device, allowing them to freely manipulate the prosthesis behavior at will. The Hill-type muscle model was used to model a dorsiflexor and a plantarflexor, which functioned around a virtual ankle joint. The model parameters were determined by fitting the model prediction to the experimental data collected from an able-bodied subject. EMG signals recorded from ankle agonist and antagonist muscle pair were used to activate the virtual muscle models. This model was validated via offline simulations and real-time prosthesis control. Additionally, the feasibility of the proposed prosthesis control on assisting the user's functional tasks was demonstrated. The present control may further improve the function of robotic prosthesis for supporting versatile activities in individuals with lower-limb amputations.
Online Self-Calibration for Visual-Inertial Navigation Systems: Models, Analysis and Degeneracy
Jan 26, 2022

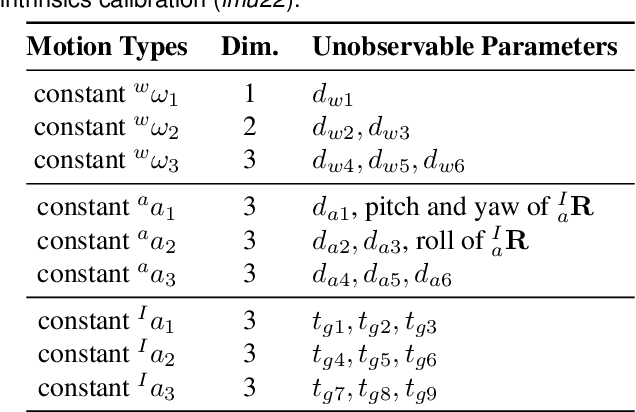
In this paper, we study in-depth the problem of online self-calibration for robust and accurate visual-inertial state estimation. In particular, we first perform a complete observability analysis for visual-inertial navigation systems (VINS) with full calibration of sensing parameters, including IMU and camera intrinsics and IMU-camera spatial-temporal extrinsic calibration, along with readout time of rolling shutter (RS) cameras (if used). We investigate different inertial model variants containing IMU intrinsic parameters that encompass most commonly used models for low-cost inertial sensors. The observability analysis results prove that VINS with full sensor calibration has four unobservable directions, corresponding to the system's global yaw and translation, while all sensor calibration parameters are observable given fully-excited 6-axis motion. Moreover, we, for the first time, identify primitive degenerate motions for IMU and camera intrinsic calibration. Each degenerate motion profile will cause a set of calibration parameters to be unobservable and any combination of these degenerate motions are still degenerate. Extensive Monte-Carlo simulations and real-world experiments are performed to validate both the observability analysis and identified degenerate motions, showing that online self-calibration improves system accuracy and robustness to calibration inaccuracies. We compare the proposed online self-calibration on commonly-used IMUs against the state-of-art offline calibration toolbox Kalibr, and show that the proposed system achieves better consistency and repeatability. Based on our analysis and experimental evaluations, we also provide practical guidelines for how to perform online IMU-camera sensor self-calibration.
Prospective Learning: Back to the Future
Jan 19, 2022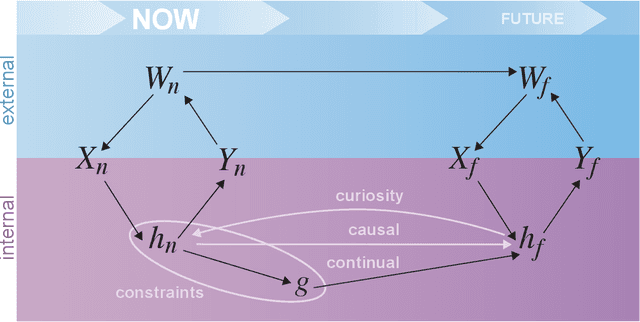

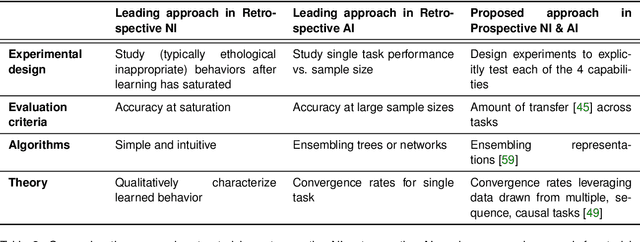
Research on both natural intelligence (NI) and artificial intelligence (AI) generally assumes that the future resembles the past: intelligent agents or systems (what we call 'intelligence') observe and act on the world, then use this experience to act on future experiences of the same kind. We call this 'retrospective learning'. For example, an intelligence may see a set of pictures of objects, along with their names, and learn to name them. A retrospective learning intelligence would merely be able to name more pictures of the same objects. We argue that this is not what true intelligence is about. In many real world problems, both NIs and AIs will have to learn for an uncertain future. Both must update their internal models to be useful for future tasks, such as naming fundamentally new objects and using these objects effectively in a new context or to achieve previously unencountered goals. This ability to learn for the future we call 'prospective learning'. We articulate four relevant factors that jointly define prospective learning. Continual learning enables intelligences to remember those aspects of the past which it believes will be most useful in the future. Prospective constraints (including biases and priors) facilitate the intelligence finding general solutions that will be applicable to future problems. Curiosity motivates taking actions that inform future decision making, including in previously unmet situations. Causal estimation enables learning the structure of relations that guide choosing actions for specific outcomes, even when the specific action-outcome contingencies have never been observed before. We argue that a paradigm shift from retrospective to prospective learning will enable the communities that study intelligence to unite and overcome existing bottlenecks to more effectively explain, augment, and engineer intelligences.