 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJeff Clune
Genie: Generative Interactive Environments
Feb 23, 2024
We introduce Genie, the first generative interactive environment trained in an unsupervised manner from unlabelled Internet videos. The model can be prompted to generate an endless variety of action-controllable virtual worlds described through text, synthetic images, photographs, and even sketches. At 11B parameters, Genie can be considered a foundation world model. It is comprised of a spatiotemporal video tokenizer, an autoregressive dynamics model, and a simple and scalable latent action model. Genie enables users to act in the generated environments on a frame-by-frame basis despite training without any ground-truth action labels or other domain-specific requirements typically found in the world model literature. Further the resulting learned latent action space facilitates training agents to imitate behaviors from unseen videos, opening the path for training generalist agents of the future.
Quality-Diversity through AI Feedback
Oct 31, 2023In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.
Managing AI Risks in an Era of Rapid Progress
Oct 26, 2023In this short consensus paper, we outline risks from upcoming, advanced AI systems. We examine large-scale social harms and malicious uses, as well as an irreversible loss of human control over autonomous AI systems. In light of rapid and continuing AI progress, we propose priorities for AI R&D and governance.
Quality Diversity through Human Feedback
Oct 18, 2023Reinforcement learning from human feedback (RLHF) has exhibited the potential to enhance the performance of foundation models for qualitative tasks. Despite its promise, its efficacy is often restricted when conceptualized merely as a mechanism to maximize learned reward models of averaged human preferences, especially in areas such as image generation which demand diverse model responses. Meanwhile, quality diversity (QD) algorithms, dedicated to seeking diverse, high-quality solutions, are often constrained by the dependency on manually defined diversity metrics. Interestingly, such limitations of RLHF and QD can be overcome by blending insights from both. This paper introduces Quality Diversity through Human Feedback (QDHF), which employs human feedback for inferring diversity metrics, expanding the applicability of QD algorithms. Empirical results reveal that QDHF outperforms existing QD methods regarding automatic diversity discovery, and matches the search capabilities of QD with human-constructed metrics. Notably, when deployed for a latent space illumination task, QDHF markedly enhances the diversity of images generated by a Diffusion model. The study concludes with an in-depth analysis of QDHF's sample efficiency and the quality of its derived diversity metrics, emphasizing its promise for enhancing exploration and diversity in optimization for complex, open-ended tasks.
Reset It and Forget It: Relearning Last-Layer Weights Improves Continual and Transfer Learning
Oct 12, 2023
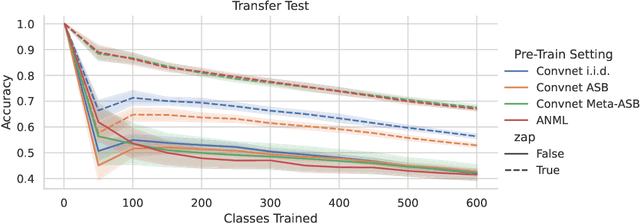

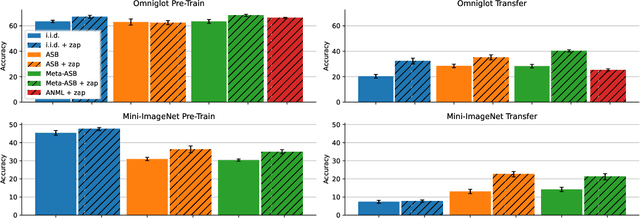
This work identifies a simple pre-training mechanism that leads to representations exhibiting better continual and transfer learning. This mechanism -- the repeated resetting of weights in the last layer, which we nickname "zapping" -- was originally designed for a meta-continual-learning procedure, yet we show it is surprisingly applicable in many settings beyond both meta-learning and continual learning. In our experiments, we wish to transfer a pre-trained image classifier to a new set of classes, in a few shots. We show that our zapping procedure results in improved transfer accuracy and/or more rapid adaptation in both standard fine-tuning and continual learning settings, while being simple to implement and computationally efficient. In many cases, we achieve performance on par with state of the art meta-learning without needing the expensive higher-order gradients, by using a combination of zapping and sequential learning. An intuitive explanation for the effectiveness of this zapping procedure is that representations trained with repeated zapping learn features that are capable of rapidly adapting to newly initialized classifiers. Such an approach may be considered a computationally cheaper type of, or alternative to, meta-learning rapidly adaptable features with higher-order gradients. This adds to recent work on the usefulness of resetting neural network parameters during training, and invites further investigation of this mechanism.
First-Explore, then Exploit: Meta-Learning Intelligent Exploration
Jul 05, 2023


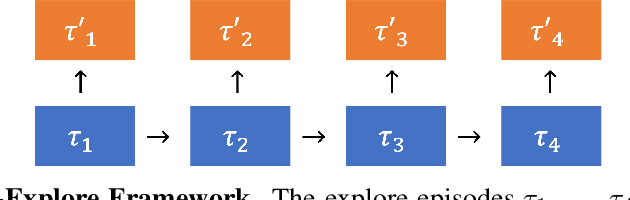
Standard reinforcement learning (RL) agents never intelligently explore like a human (i.e. by taking into account complex domain priors and previous explorations). Even the most basic intelligent exploration strategies such as exhaustive search are only inefficiently or poorly approximated by approaches such as novelty search or intrinsic motivation, let alone more complicated strategies like learning new skills, climbing stairs, opening doors, or conducting experiments. This lack of intelligent exploration limits sample efficiency and prevents solving hard exploration domains. We argue a core barrier prohibiting many RL approaches from learning intelligent exploration is that the methods attempt to explore and exploit simultaneously, which harms both exploration and exploitation as the goals often conflict. We propose a novel meta-RL framework (First-Explore) with two policies: one policy learns to only explore and one policy learns to only exploit. Once trained, we can then explore with the explore policy, for as long as desired, and then exploit based on all the information gained during exploration. This approach avoids the conflict of trying to do both exploration and exploitation at once. We demonstrate that First-Explore can learn intelligent exploration strategies such as exhaustive search and more, and that it outperforms dominant standard RL and meta-RL approaches on domains where exploration requires sacrificing reward. First-Explore is a significant step towards creating meta-RL algorithms capable of learning human-level exploration which is essential to solve challenging unseen hard-exploration domains.
OMNI: Open-endedness via Models of human Notions of Interestingness
Jun 02, 2023
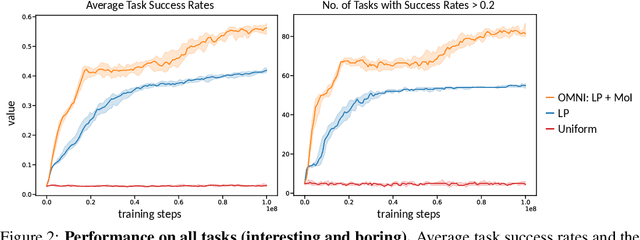
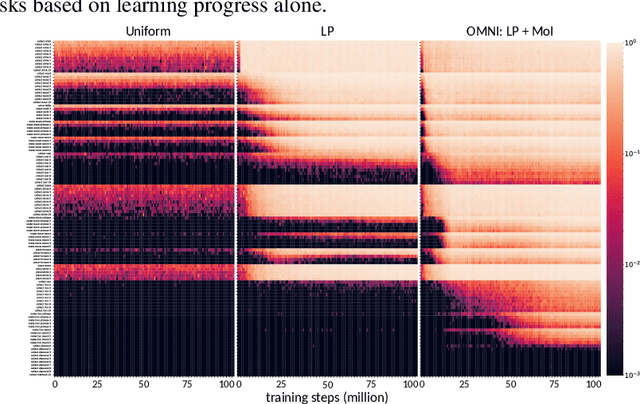
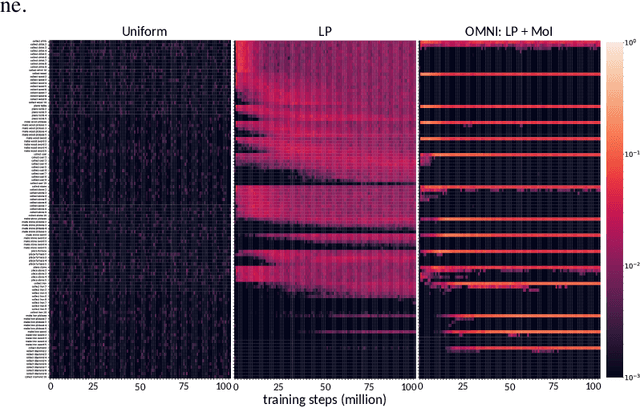
Open-ended algorithms aim to learn new, interesting behaviors forever. That requires a vast environment search space, but there are thus infinitely many possible tasks. Even after filtering for tasks the current agent can learn (i.e., learning progress), countless learnable yet uninteresting tasks remain (e.g., minor variations of previously learned tasks). An Achilles Heel of open-endedness research is the inability to quantify (and thus prioritize) tasks that are not just learnable, but also $\textit{interesting}$ (e.g., worthwhile and novel). We propose solving this problem by $\textit{Open-endedness via Models of human Notions of Interestingness}$ (OMNI). The insight is that we can utilize large (language) models (LMs) as a model of interestingness (MoI), because they $\textit{already}$ internalize human concepts of interestingness from training on vast amounts of human-generated data, where humans naturally write about what they find interesting or boring. We show that LM-based MoIs improve open-ended learning by focusing on tasks that are both learnable $\textit{and interesting}$, outperforming baselines based on uniform task sampling or learning progress alone. This approach has the potential to dramatically advance the ability to intelligently select which tasks to focus on next (i.e., auto-curricula), and could be seen as AI selecting its own next task to learn, facilitating self-improving AI and AI-Generating Algorithms.
Thought Cloning: Learning to Think while Acting by Imitating Human Thinking
Jun 01, 2023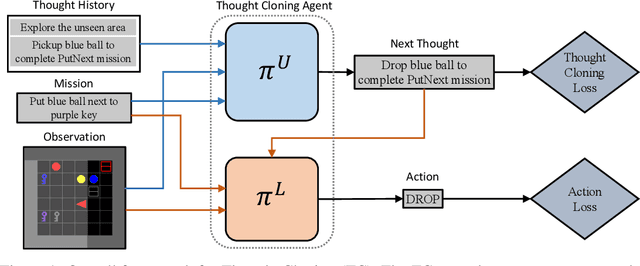
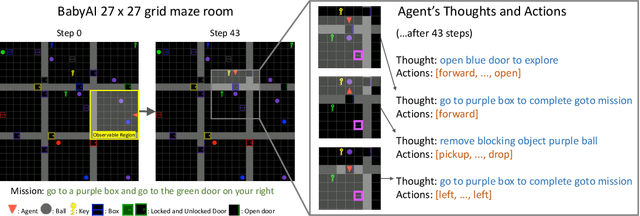
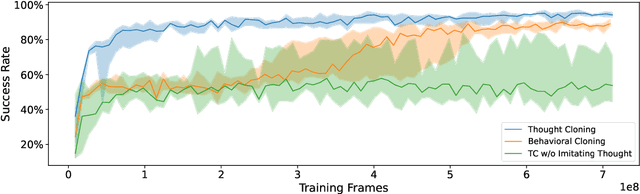
Language is often considered a key aspect of human thinking, providing us with exceptional abilities to generalize, explore, plan, replan, and adapt to new situations. However, Reinforcement Learning (RL) agents are far from human-level performance in any of these abilities. We hypothesize one reason for such cognitive deficiencies is that they lack the benefits of thinking in language and that we can improve AI agents by training them to think like humans do. We introduce a novel Imitation Learning framework, Thought Cloning, where the idea is to not just clone the behaviors of human demonstrators, but also the thoughts humans have as they perform these behaviors. While we expect Thought Cloning to truly shine at scale on internet-sized datasets of humans thinking out loud while acting (e.g. online videos with transcripts), here we conduct experiments in a domain where the thinking and action data are synthetically generated. Results reveal that Thought Cloning learns much faster than Behavioral Cloning and its performance advantage grows the further out of distribution test tasks are, highlighting its ability to better handle novel situations. Thought Cloning also provides important benefits for AI Safety and Interpretability, and makes it easier to debug and improve AI. Because we can observe the agent's thoughts, we can (1) more easily diagnose why things are going wrong, making it easier to fix the problem, (2) steer the agent by correcting its thinking, or (3) prevent it from doing unsafe things it plans to do. Overall, by training agents how to think as well as behave, Thought Cloning creates safer, more powerful agents.
Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
Jun 23, 2022

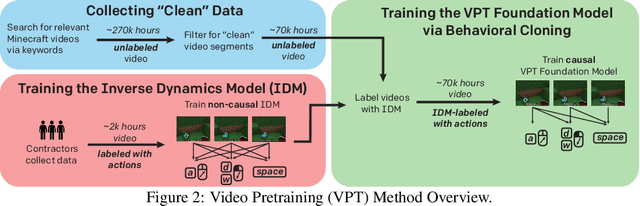
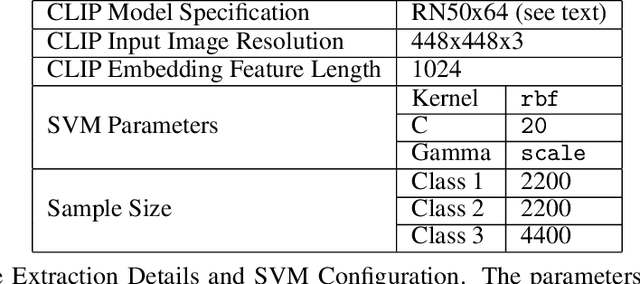
Pretraining on noisy, internet-scale datasets has been heavily studied as a technique for training models with broad, general capabilities for text, images, and other modalities. However, for many sequential decision domains such as robotics, video games, and computer use, publicly available data does not contain the labels required to train behavioral priors in the same way. We extend the internet-scale pretraining paradigm to sequential decision domains through semi-supervised imitation learning wherein agents learn to act by watching online unlabeled videos. Specifically, we show that with a small amount of labeled data we can train an inverse dynamics model accurate enough to label a huge unlabeled source of online data -- here, online videos of people playing Minecraft -- from which we can then train a general behavioral prior. Despite using the native human interface (mouse and keyboard at 20Hz), we show that this behavioral prior has nontrivial zero-shot capabilities and that it can be fine-tuned, with both imitation learning and reinforcement learning, to hard-exploration tasks that are impossible to learn from scratch via reinforcement learning. For many tasks our models exhibit human-level performance, and we are the first to report computer agents that can craft diamond tools, which can take proficient humans upwards of 20 minutes (24,000 environment actions) of gameplay to accomplish.
Continual learning under domain transfer with sparse synaptic bursting
Aug 26, 2021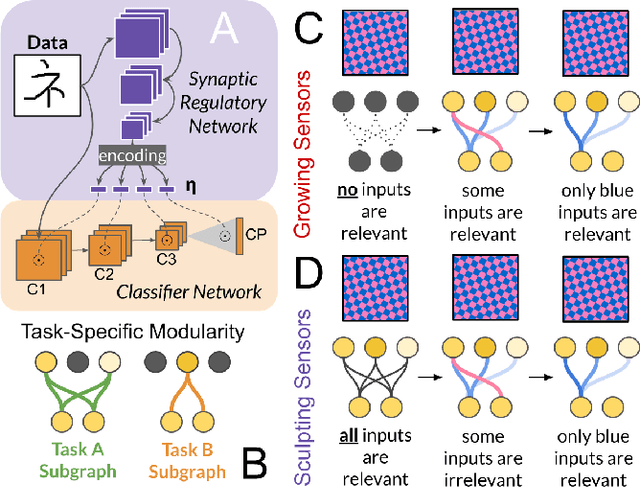
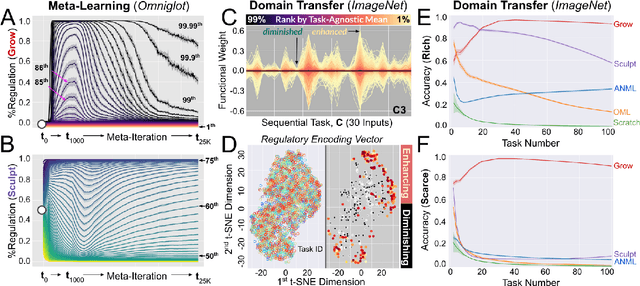
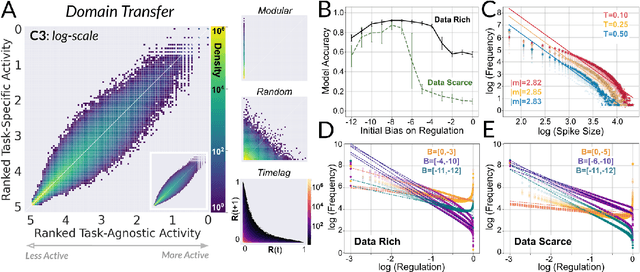
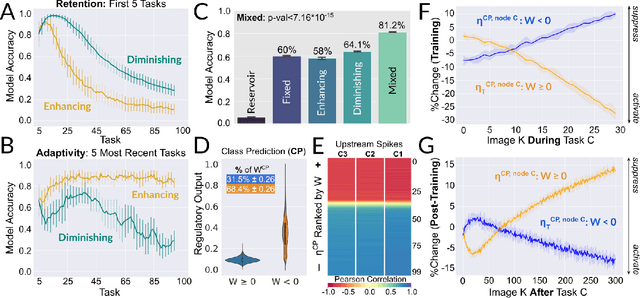
Existing machines are functionally specific tools that were made for easy prediction and control. Tomorrow's machines may be closer to biological systems in their mutability, resilience, and autonomy. But first they must be capable of learning, and retaining, new information without repeated exposure to it. Past efforts to engineer such systems have sought to build or regulate artificial neural networks using task-specific modules with constrained circumstances of application. This has not yet enabled continual learning over long sequences of previously unseen data without corrupting existing knowledge: a problem known as catastrophic forgetting. In this paper, we introduce a system that can learn sequentially over previously unseen datasets (ImageNet, CIFAR-100) with little forgetting over time. This is accomplished by regulating the activity of weights in a convolutional neural network on the basis of inputs using top-down modulation generated by a second feed-forward neural network. We find that our method learns continually under domain transfer with sparse bursts of activity in weights that are recycled across tasks, rather than by maintaining task-specific modules. Sparse synaptic bursting is found to balance enhanced and diminished activity in a way that facilitates adaptation to new inputs without corrupting previously acquired functions. This behavior emerges during a prior meta-learning phase in which regulated synapses are selectively disinhibited, or grown, from an initial state of uniform suppression.