 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJianzhong Qi
Spatial-temporal Forecasting for Regions without Observations
Jan 19, 2024
Spatial-temporal forecasting plays an important role in many real-world applications, such as traffic forecasting, air pollutant forecasting, crowd-flow forecasting, and so on. State-of-the-art spatial-temporal forecasting models take data-driven approaches and rely heavily on data availability. Such models suffer from accuracy issues when data is incomplete, which is common in reality due to the heavy costs of deploying and maintaining sensors for data collection. A few recent studies attempted to address the issue of incomplete data. They typically assume some data availability in a region of interest either for a short period or at a few locations. In this paper, we further study spatial-temporal forecasting for a region of interest without any historical observations, to address scenarios such as unbalanced region development, progressive deployment of sensors or lack of open data. We propose a model named STSM for the task. The model takes a contrastive learning-based approach to learn spatial-temporal patterns from adjacent regions that have recorded data. Our key insight is to learn from the locations that resemble those in the region of interest, and we propose a selective masking strategy to enable the learning. As a result, our model outperforms adapted state-of-the-art models, reducing errors consistently over both traffic and air pollutant forecasting tasks. The source code is available at https://github.com/suzy0223/STSM.
Urban Region Representation Learning with Attentive Fusion
Dec 07, 2023An increasing number of related urban data sources have brought forth novel opportunities for learning urban region representations, i.e., embeddings. The embeddings describe latent features of urban regions and enable discovering similar regions for urban planning applications. Existing methods learn an embedding for a region using every different type of region feature data, and subsequently fuse all learned embeddings of a region to generate a unified region embedding. However, these studies often overlook the significance of the fusion process. The typical fusion methods rely on simple aggregation, such as summation and concatenation, thereby disregarding correlations within the fused region embeddings. To address this limitation, we propose a novel model named HAFusion. Our model is powered by a dual-feature attentive fusion module named DAFusion, which fuses embeddings from different region features to learn higher-order correlations between the regions as well as between the different types of region features. DAFusion is generic - it can be integrated into existing models to enhance their fusion process. Further, motivated by the effective fusion capability of an attentive module, we propose a hybrid attentive feature learning module named HALearning to enhance the embedding learning from each individual type of region features. Extensive experiments on three real-world datasets demonstrate that our model HAFusion outperforms state-of-the-art methods across three different prediction tasks. Using our learned region embedding leads to consistent and up to 31% improvements in the prediction accuracy.
Fake News Detection Through Graph-based Neural Networks: A Survey
Jul 24, 2023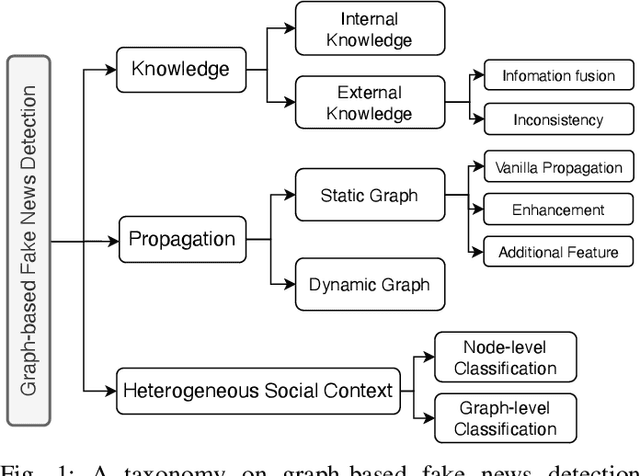
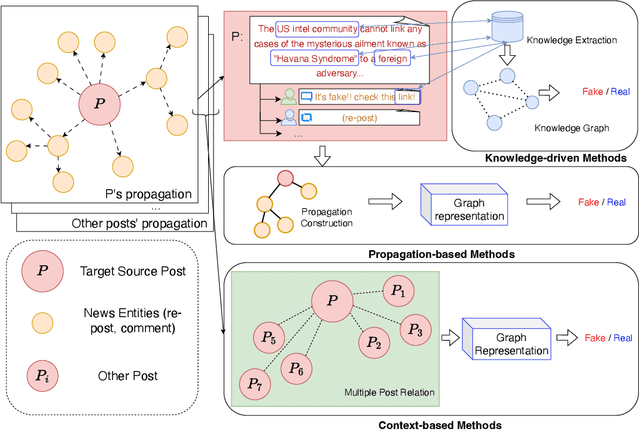
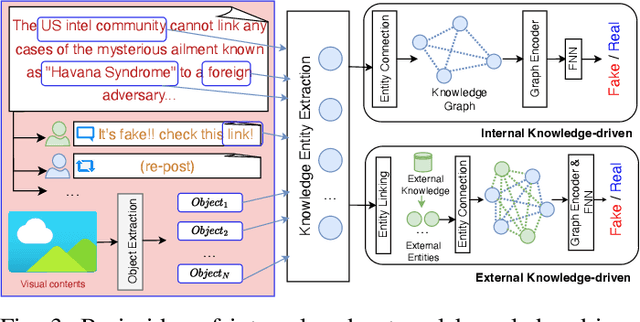
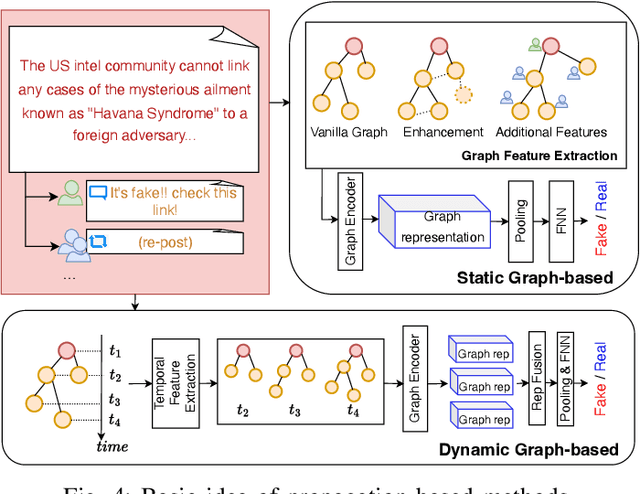
The popularity of online social networks has enabled rapid dissemination of information. People now can share and consume information much more rapidly than ever before. However, low-quality and/or accidentally/deliberately fake information can also spread rapidly. This can lead to considerable and negative impacts on society. Identifying, labelling and debunking online misinformation as early as possible has become an increasingly urgent problem. Many methods have been proposed to detect fake news including many deep learning and graph-based approaches. In recent years, graph-based methods have yielded strong results, as they can closely model the social context and propagation process of online news. In this paper, we present a systematic review of fake news detection studies based on graph-based and deep learning-based techniques. We classify existing graph-based methods into knowledge-driven methods, propagation-based methods, and heterogeneous social context-based methods, depending on how a graph structure is constructed to model news related information flows. We further discuss the challenges and open problems in graph-based fake news detection and identify future research directions.
AutoAlign: Fully Automatic and Effective Knowledge Graph Alignment enabled by Large Language Models
Jul 18, 2023
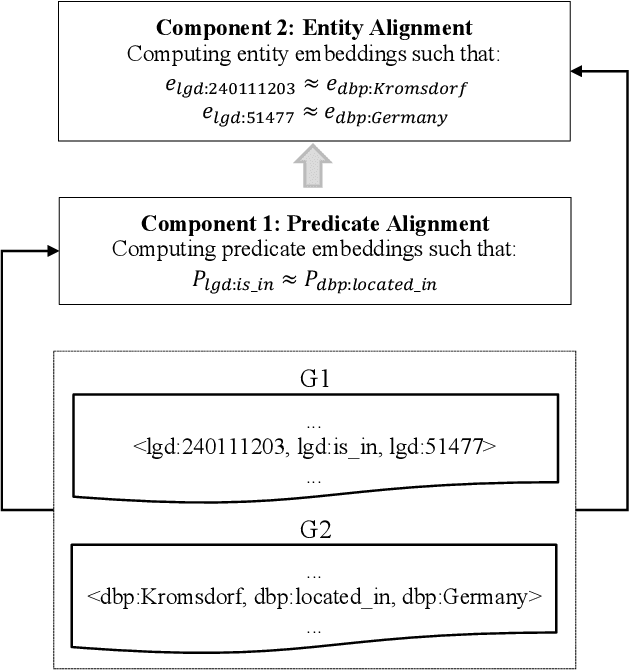
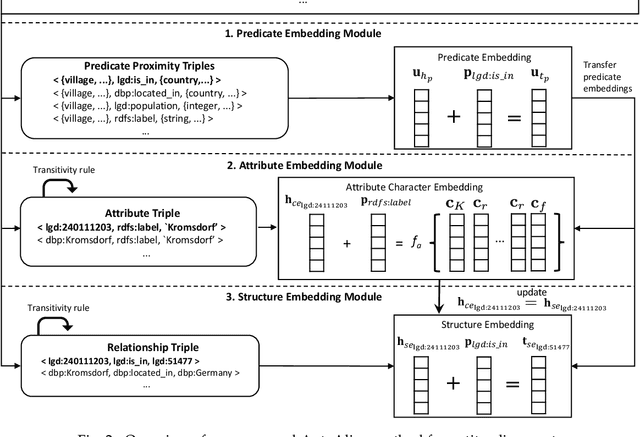
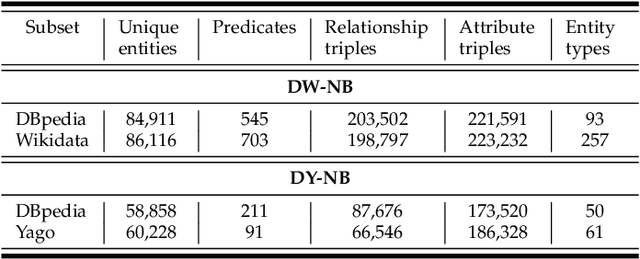
The task of entity alignment between knowledge graphs (KGs) aims to identify every pair of entities from two different KGs that represent the same entity. Many machine learning-based methods have been proposed for this task. However, to our best knowledge, existing methods all require manually crafted seed alignments, which are expensive to obtain. In this paper, we propose the first fully automatic alignment method named AutoAlign, which does not require any manually crafted seed alignments. Specifically, for predicate embeddings, AutoAlign constructs a predicate-proximity-graph with the help of large language models to automatically capture the similarity between predicates across two KGs. For entity embeddings, AutoAlign first computes the entity embeddings of each KG independently using TransE, and then shifts the two KGs' entity embeddings into the same vector space by computing the similarity between entities based on their attributes. Thus, both predicate alignment and entity alignment can be done without manually crafted seed alignments. AutoAlign is not only fully automatic, but also highly effective. Experiments using real-world KGs show that AutoAlign improves the performance of entity alignment significantly compared to state-of-the-art methods.
Annotating and Detecting Fine-grained Factual Errors for Dialogue Summarization
May 26, 2023

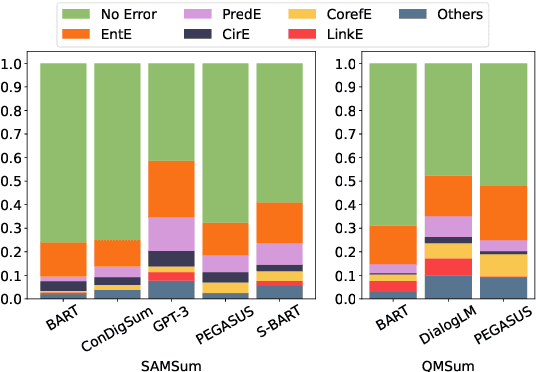

A series of datasets and models have been proposed for summaries generated for well-formatted documents such as news articles. Dialogue summaries, however, have been under explored. In this paper, we present the first dataset with fine-grained factual error annotations named DIASUMFACT. We define fine-grained factual error detection as a sentence-level multi-label classification problem, and we evaluate two state-of-the-art (SOTA) models on our dataset. Both models yield sub-optimal results, with a macro-averaged F1 score of around 0.25 over 6 error classes. We further propose an unsupervised model ENDERANKER via candidate ranking using pretrained encoder-decoder models. Our model performs on par with the SOTA models while requiring fewer resources. These observations confirm the challenges in detecting factual errors from dialogue summaries, which call for further studies, for which our dataset and results offer a solid foundation.
Compressed Heterogeneous Graph for Abstractive Multi-Document Summarization
Mar 12, 2023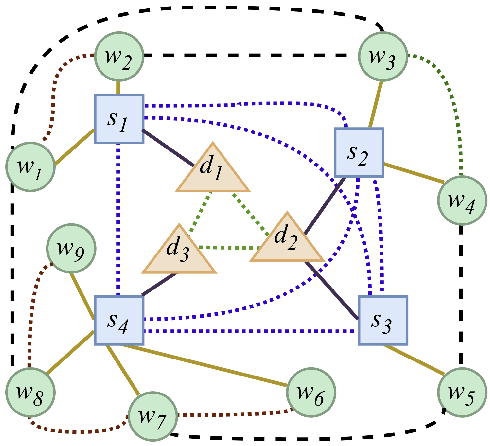
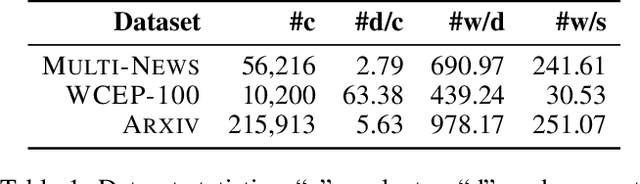
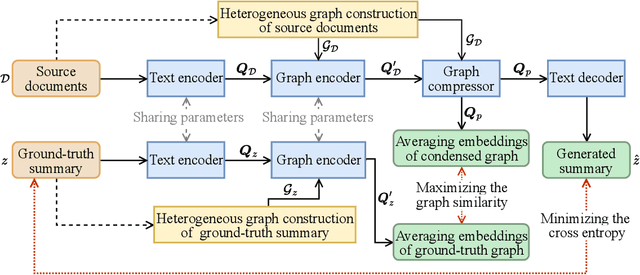
Multi-document summarization (MDS) aims to generate a summary for a number of related documents. We propose HGSUM, an MDS model that extends an encoder-decoder architecture, to incorporate a heterogeneous graph to represent different semantic units (e.g., words and sentences) of the documents. This contrasts with existing MDS models which do not consider different edge types of graphs and as such do not capture the diversity of relationships in the documents. To preserve only key information and relationships of the documents in the heterogeneous graph, HGSUM uses graph pooling to compress the input graph. And to guide HGSUM to learn compression, we introduce an additional objective that maximizes the similarity between the compressed graph and the graph constructed from the ground-truth summary during training. HGSUM is trained end-to-end with graph similarity and standard cross-entropy objectives. Experimental results over MULTI-NEWS, WCEP-100, and ARXIV show that HGSUM outperforms state-of-the-art MDS models. The code for our model and experiments is available at: https://github.com/oaimli/HGSum.
CHGNN: A Semi-Supervised Contrastive Hypergraph Learning Network
Mar 10, 2023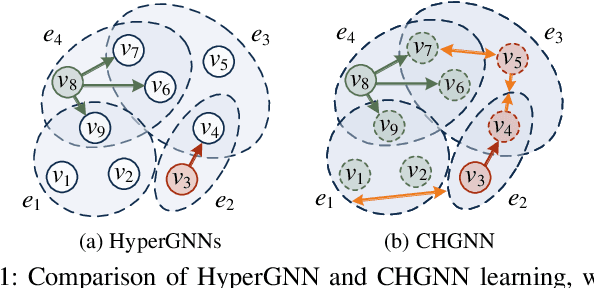
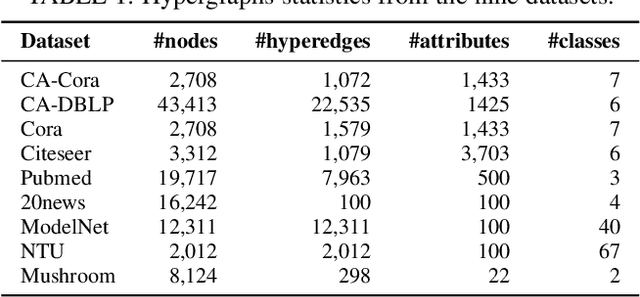
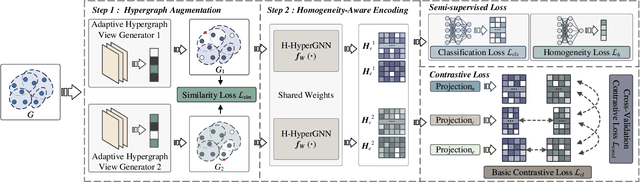
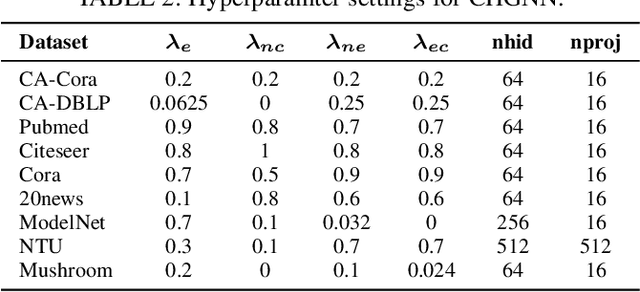
Hypergraphs can model higher-order relationships among data objects that are found in applications such as social networks and bioinformatics. However, recent studies on hypergraph learning that extend graph convolutional networks to hypergraphs cannot learn effectively from features of unlabeled data. To such learning, we propose a contrastive hypergraph neural network, CHGNN, that exploits self-supervised contrastive learning techniques to learn from labeled and unlabeled data. First, CHGNN includes an adaptive hypergraph view generator that adopts an auto-augmentation strategy and learns a perturbed probability distribution of minimal sufficient views. Second, CHGNN encompasses an improved hypergraph encoder that considers hyperedge homogeneity to fuse information effectively. Third, CHGNN is equipped with a joint loss function that combines a similarity loss for the view generator, a node classification loss, and a hyperedge homogeneity loss to inject supervision signals. It also includes basic and cross-validation contrastive losses, associated with an enhanced contrastive loss training process. Experimental results on nine real datasets offer insight into the effectiveness of CHGNN, showing that it outperforms 13 competitors in terms of classification accuracy consistently.
WISK: A Workload-aware Learned Index for Spatial Keyword Queries
Feb 28, 2023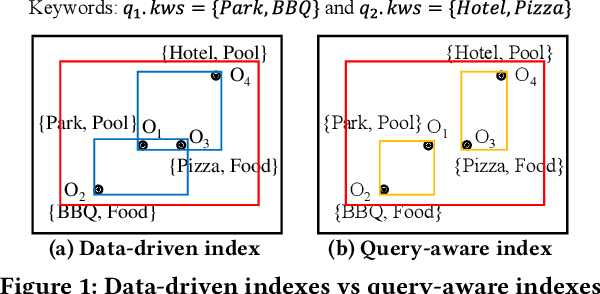
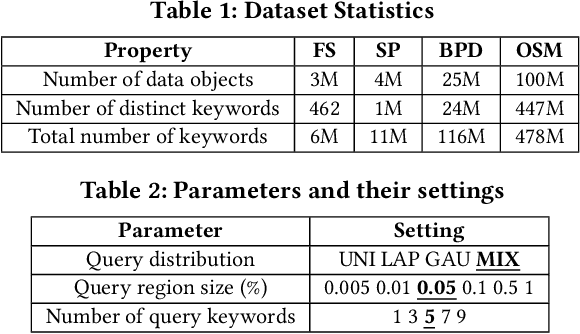
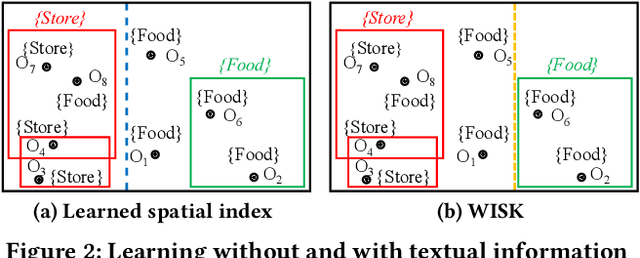
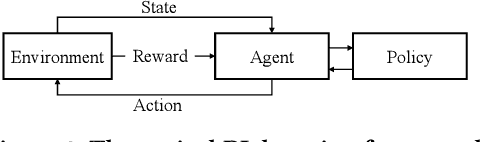
Spatial objects often come with textual information, such as Points of Interest (POIs) with their descriptions, which are referred to as geo-textual data. To retrieve such data, spatial keyword queries that take into account both spatial proximity and textual relevance have been extensively studied. Existing indexes designed for spatial keyword queries are mostly built based on the geo-textual data without considering the distribution of queries already received. However, previous studies have shown that utilizing the known query distribution can improve the index structure for future query processing. In this paper, we propose WISK, a learned index for spatial keyword queries, which self-adapts for optimizing querying costs given a query workload. One key challenge is how to utilize both structured spatial attributes and unstructured textual information during learning the index. We first divide the data objects into partitions, aiming to minimize the processing costs of the given query workload. We prove the NP-hardness of the partitioning problem and propose a machine learning model to find the optimal partitions. Then, to achieve more pruning power, we build a hierarchical structure based on the generated partitions in a bottom-up manner with a reinforcement learning-based approach. We conduct extensive experiments on real-world datasets and query workloads with various distributions, and the results show that WISK outperforms all competitors, achieving up to 8x speedup in querying time with comparable storage overhead.
INCREASE: Inductive Graph Representation Learning for Spatio-Temporal Kriging
Feb 06, 2023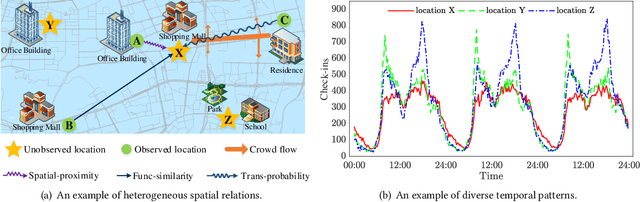
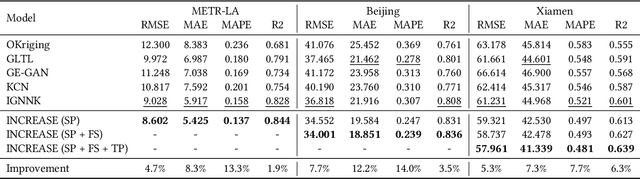
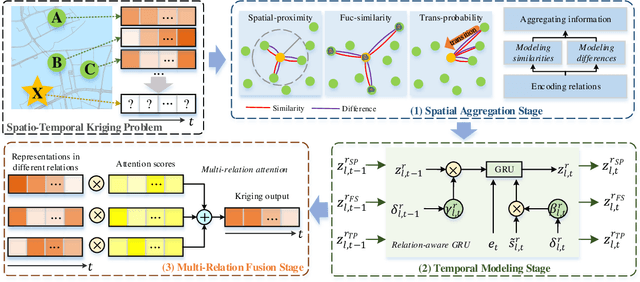
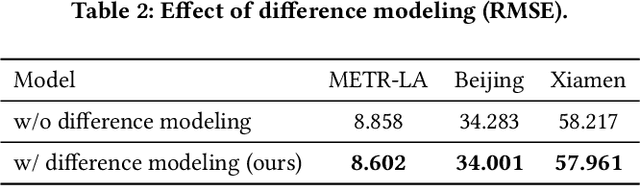
Spatio-temporal kriging is an important problem in web and social applications, such as Web or Internet of Things, where things (e.g., sensors) connected into a web often come with spatial and temporal properties. It aims to infer knowledge for (the things at) unobserved locations using the data from (the things at) observed locations during a given time period of interest. This problem essentially requires \emph{inductive learning}. Once trained, the model should be able to perform kriging for different locations including newly given ones, without retraining. However, it is challenging to perform accurate kriging results because of the heterogeneous spatial relations and diverse temporal patterns. In this paper, we propose a novel inductive graph representation learning model for spatio-temporal kriging. We first encode heterogeneous spatial relations between the unobserved and observed locations by their spatial proximity, functional similarity, and transition probability. Based on each relation, we accurately aggregate the information of most correlated observed locations to produce inductive representations for the unobserved locations, by jointly modeling their similarities and differences. Then, we design relation-aware gated recurrent unit (GRU) networks to adaptively capture the temporal correlations in the generated sequence representations for each relation. Finally, we propose a multi-relation attention mechanism to dynamically fuse the complex spatio-temporal information at different time steps from multiple relations to compute the kriging output. Experimental results on three real-world datasets show that our proposed model outperforms state-of-the-art methods consistently, and the advantage is more significant when there are fewer observed locations. Our code is available at https://github.com/zhengchuanpan/INCREASE.
FedGS: Federated Graph-based Sampling with Arbitrary Client Availability
Dec 07, 2022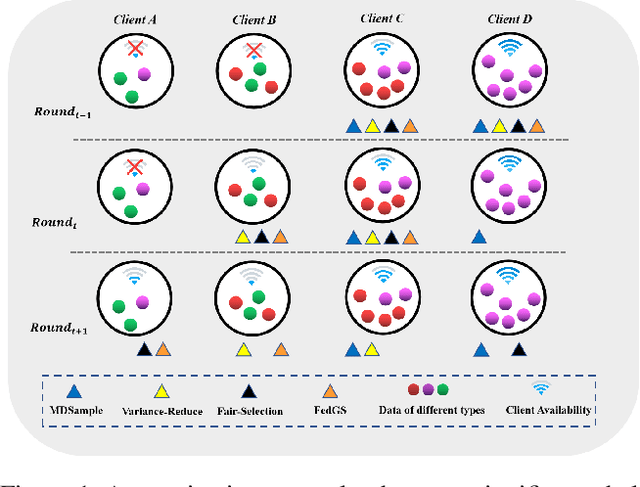

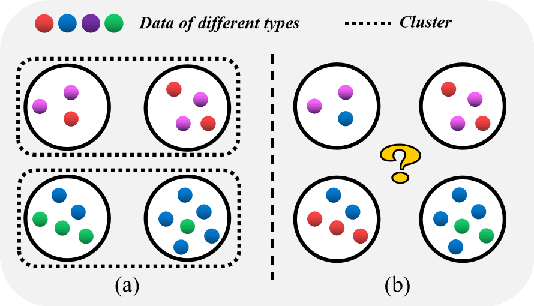
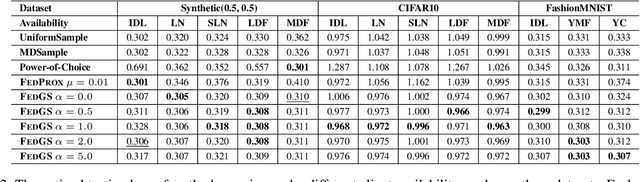
While federated learning has shown strong results in optimizing a machine learning model without direct access to the original data, its performance may be hindered by intermittent client availability which slows down the convergence and biases the final learned model. There are significant challenges to achieve both stable and bias-free training under arbitrary client availability. To address these challenges, we propose a framework named Federated Graph-based Sampling (FedGS), to stabilize the global model update and mitigate the long-term bias given arbitrary client availability simultaneously. First, we model the data correlations of clients with a Data-Distribution-Dependency Graph (3DG) that helps keep the sampled clients data apart from each other, which is theoretically shown to improve the approximation to the optimal model update. Second, constrained by the far-distance in data distribution of the sampled clients, we further minimize the variance of the numbers of times that the clients are sampled, to mitigate long-term bias. To validate the effectiveness of FedGS, we conduct experiments on three datasets under a comprehensive set of seven client availability modes. Our experimental results confirm FedGS's advantage in both enabling a fair client-sampling scheme and improving the model performance under arbitrary client availability. Our code is available at \url{https://github.com/WwZzz/FedGS}.