 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJiaqi Zhang
Membership Testing in Markov Equivalence Classes via Independence Query Oracles
Mar 09, 2024
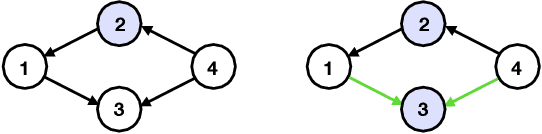
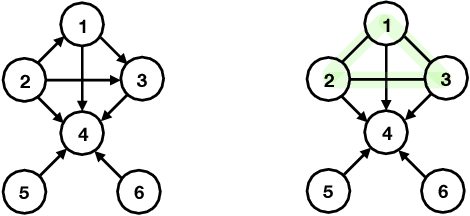

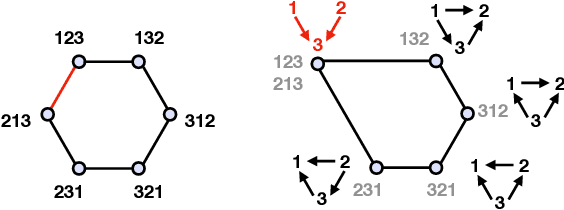
Understanding causal relationships between variables is a fundamental problem with broad impact in numerous scientific fields. While extensive research has been dedicated to learning causal graphs from data, its complementary concept of testing causal relationships has remained largely unexplored. While learning involves the task of recovering the Markov equivalence class (MEC) of the underlying causal graph from observational data, the testing counterpart addresses the following critical question: Given a specific MEC and observational data from some causal graph, can we determine if the data-generating causal graph belongs to the given MEC? We explore constraint-based testing methods by establishing bounds on the required number of conditional independence tests. Our bounds are in terms of the size of the maximum undirected clique ($s$) of the given MEC. In the worst case, we show a lower bound of $\exp(\Omega(s))$ independence tests. We then give an algorithm that resolves the task with $\exp(O(s))$ tests, matching our lower bound. Compared to the learning problem, where algorithms often use a number of independence tests that is exponential in the maximum in-degree, this shows that testing is relatively easier. In particular, it requires exponentially less independence tests in graphs featuring high in-degrees and small clique sizes. Additionally, using the DAG associahedron, we provide a geometric interpretation of testing versus learning and discuss how our testing result can aid learning.
SecFormer: Towards Fast and Accurate Privacy-Preserving Inference for Large Language Models
Jan 06, 2024With the growing use of large language models hosted on cloud platforms to offer inference services, privacy concerns are escalating, especially concerning sensitive data like investment plans and bank account details. Secure Multi-Party Computing (SMPC) emerges as a promising solution to protect the privacy of inference data and model parameters. However, the application of SMPC in Privacy-Preserving Inference (PPI) for large language models, particularly those based on the Transformer architecture, often leads to considerable slowdowns or declines in performance. This is largely due to the multitude of nonlinear operations in the Transformer architecture, which are not well-suited to SMPC and difficult to circumvent or optimize effectively. To address this concern, we introduce an advanced optimization framework called SecFormer, to achieve fast and accurate PPI for Transformer models. By implementing model design optimization, we successfully eliminate the high-cost exponential and maximum operations in PPI without sacrificing model performance. Additionally, we have developed a suite of efficient SMPC protocols that utilize segmented polynomials, Fourier series and Goldschmidt's method to handle other complex nonlinear functions within PPI, such as GeLU, LayerNorm, and Softmax. Our extensive experiments reveal that SecFormer outperforms MPCFormer in performance, showing improvements of $5.6\%$ and $24.2\%$ for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, respectively. In terms of efficiency, SecFormer is 3.56 and 3.58 times faster than Puma for BERT$_{\text{BASE}}$ and BERT$_{\text{LARGE}}$, demonstrating its effectiveness and speed.
Signal Processing Meets SGD: From Momentum to Filter
Nov 17, 2023In the field of deep learning, Stochastic Gradient Descent (SGD) and its momentum-based variants are the predominant choices for optimization algorithms. Despite all that, these momentum strategies, which accumulate historical gradients by using a fixed $\beta$ hyperparameter to smooth the optimization processing, often neglect the potential impact of the variance of historical gradients on the current gradient estimation. In the gradient variance during training, fluctuation indicates the objective function does not meet the Lipschitz continuity condition at all time, which raises the troublesome optimization problem. This paper aims to explore the potential benefits of reducing the variance of historical gradients to make optimizer converge to flat solutions. Moreover, we proposed a new optimization method based on reducing the variance. We employed the Wiener filter theory to enhance the first moment estimation of SGD, notably introducing an adaptive weight to optimizer. Specifically, the adaptive weight dynamically changes along with temporal fluctuation of gradient variance during deep learning model training. Experimental results demonstrated our proposed adaptive weight optimizer, SGDF (Stochastic Gradient Descent With Filter), can achieve satisfactory performance compared with state-of-the-art optimizers.
Meek Separators and Their Applications in Targeted Causal Discovery
Oct 30, 2023Learning causal structures from interventional data is a fundamental problem with broad applications across various fields. While many previous works have focused on recovering the entire causal graph, in practice, there are scenarios where learning only part of the causal graph suffices. This is called $targeted$ causal discovery. In our work, we focus on two such well-motivated problems: subset search and causal matching. We aim to minimize the number of interventions in both cases. Towards this, we introduce the $Meek~separator$, which is a subset of vertices that, when intervened, decomposes the remaining unoriented edges into smaller connected components. We then present an efficient algorithm to find Meek separators that are of small sizes. Such a procedure is helpful in designing various divide-and-conquer-based approaches. In particular, we propose two randomized algorithms that achieve logarithmic approximation for subset search and causal matching, respectively. Our results provide the first known average-case provable guarantees for both problems. We believe that this opens up possibilities to design near-optimal methods for many other targeted causal structure learning problems arising from various applications.
Towards Causal Foundation Model: on Duality between Causal Inference and Attention
Oct 01, 2023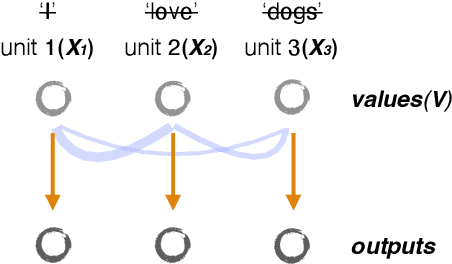
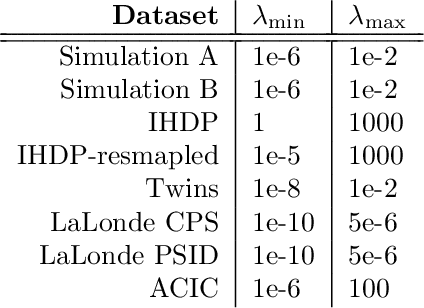
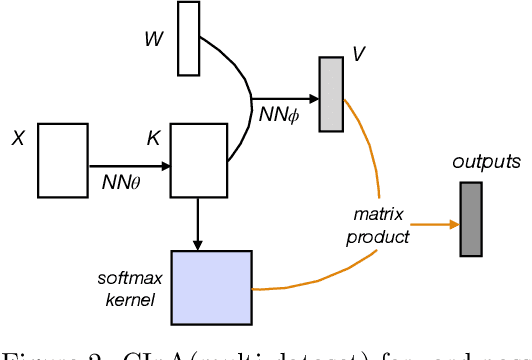
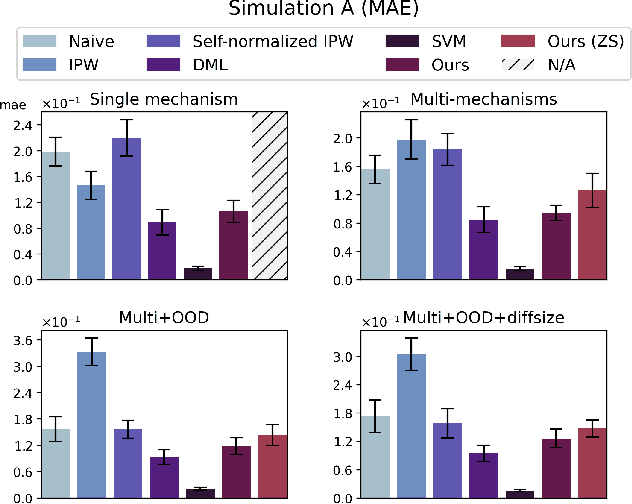
Foundation models have brought changes to the landscape of machine learning, demonstrating sparks of human-level intelligence across a diverse array of tasks. However, a gap persists in complex tasks such as causal inference, primarily due to challenges associated with intricate reasoning steps and high numerical precision requirements. In this work, we take a first step towards building causally-aware foundation models for complex tasks. We propose a novel, theoretically sound method called Causal Inference with Attention (CInA), which utilizes multiple unlabeled datasets to perform self-supervised causal learning, and subsequently enables zero-shot causal inference on unseen tasks with new data. This is based on our theoretical results that demonstrate the primal-dual connection between optimal covariate balancing and self-attention, facilitating zero-shot causal inference through the final layer of a trained transformer-type architecture. We demonstrate empirically that our approach CInA effectively generalizes to out-of-distribution datasets and various real-world datasets, matching or even surpassing traditional per-dataset causal inference methodologies.
NineRec: A Benchmark Dataset Suite for Evaluating Transferable Recommendation
Sep 20, 2023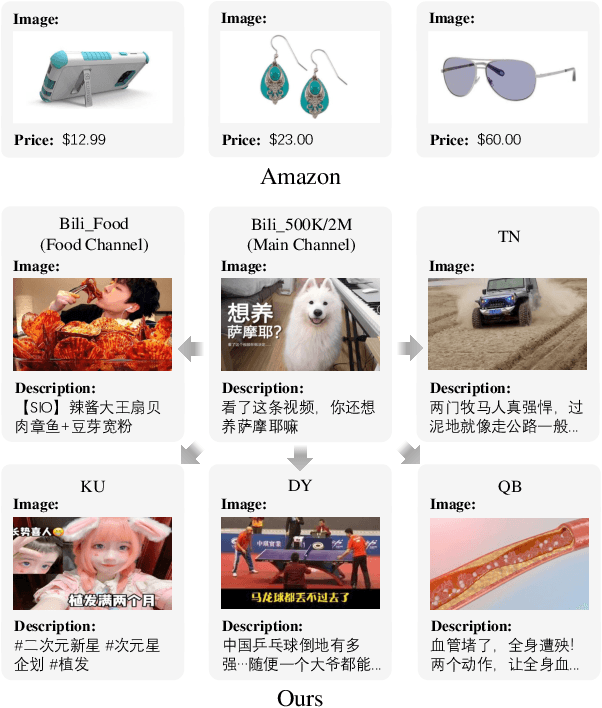

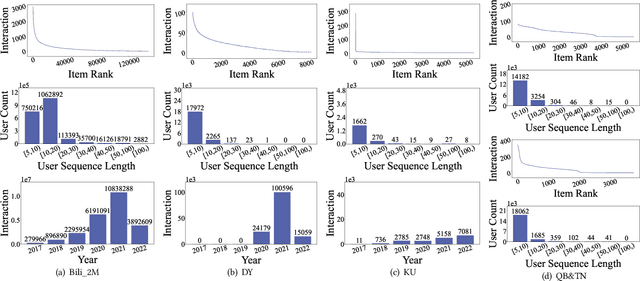
Learning a recommender system model from an item's raw modality features (such as image, text, audio, etc.), called MoRec, has attracted growing interest recently. One key advantage of MoRec is that it can easily benefit from advances in other fields, such as natural language processing (NLP) and computer vision (CV). Moreover, it naturally supports transfer learning across different systems through modality features, known as transferable recommender systems, or TransRec. However, so far, TransRec has made little progress, compared to groundbreaking foundation models in the fields of NLP and CV. The lack of large-scale, high-quality recommendation datasets poses a major obstacle. To this end, we introduce NineRec, a TransRec dataset suite that includes a large-scale source domain recommendation dataset and nine diverse target domain recommendation datasets. Each item in NineRec is represented by a text description and a high-resolution cover image. With NineRec, we can implement TransRec models in an end-to-end training manner instead of using pre-extracted invariant features. We conduct a benchmark study and empirical analysis of TransRec using NineRec, and our findings provide several valuable insights. To support further research, we make our code, datasets, benchmarks, and leaderboards publicly available at https://github.com/westlake-repl/NineRec.
An Image Dataset for Benchmarking Recommender Systems with Raw Pixels
Sep 17, 2023

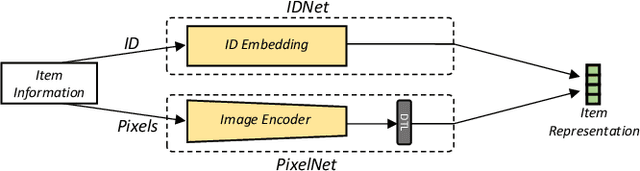

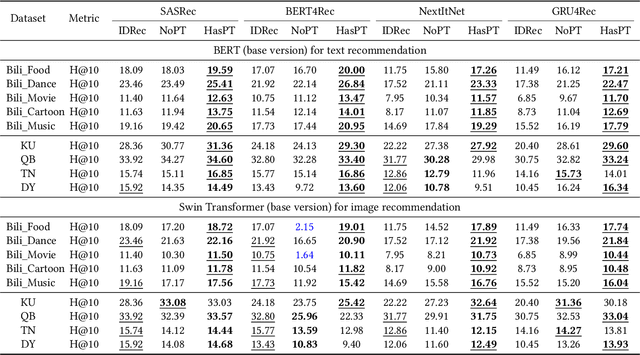
Recommender systems (RS) have achieved significant success by leveraging explicit identification (ID) features. However, the full potential of content features, especially the pure image pixel features, remains relatively unexplored. The limited availability of large, diverse, and content-driven image recommendation datasets has hindered the use of raw images as item representations. In this regard, we present PixelRec, a massive image-centric recommendation dataset that includes approximately 200 million user-image interactions, 30 million users, and 400,000 high-quality cover images. By providing direct access to raw image pixels, PixelRec enables recommendation models to learn item representation directly from them. To demonstrate its utility, we begin by presenting the results of several classical pure ID-based baseline models, termed IDNet, trained on PixelRec. Then, to show the effectiveness of the dataset's image features, we substitute the itemID embeddings (from IDNet) with a powerful vision encoder that represents items using their raw image pixels. This new model is dubbed PixelNet.Our findings indicate that even in standard, non-cold start recommendation settings where IDNet is recognized as highly effective, PixelNet can already perform equally well or even better than IDNet. Moreover, PixelNet has several other notable advantages over IDNet, such as being more effective in cold-start and cross-domain recommendation scenarios. These results underscore the importance of visual features in PixelRec. We believe that PixelRec can serve as a critical resource and testing ground for research on recommendation models that emphasize image pixel content. The dataset, code, and leaderboard will be available at https://github.com/westlake-repl/PixelRec.
Model Provenance via Model DNA
Aug 04, 2023


Understanding the life cycle of the machine learning (ML) model is an intriguing area of research (e.g., understanding where the model comes from, how it is trained, and how it is used). This paper focuses on a novel problem within this field, namely Model Provenance (MP), which concerns the relationship between a target model and its pre-training model and aims to determine whether a source model serves as the provenance for a target model. This is an important problem that has significant implications for ensuring the security and intellectual property of machine learning models but has not received much attention in the literature. To fill in this gap, we introduce a novel concept of Model DNA which represents the unique characteristics of a machine learning model. We utilize a data-driven and model-driven representation learning method to encode the model's training data and input-output information as a compact and comprehensive representation (i.e., DNA) of the model. Using this model DNA, we develop an efficient framework for model provenance identification, which enables us to identify whether a source model is a pre-training model of a target model. We conduct evaluations on both computer vision and natural language processing tasks using various models, datasets, and scenarios to demonstrate the effectiveness of our approach in accurately identifying model provenance.
Digital twin brain: a bridge between biological intelligence and artificial intelligence
Aug 03, 2023
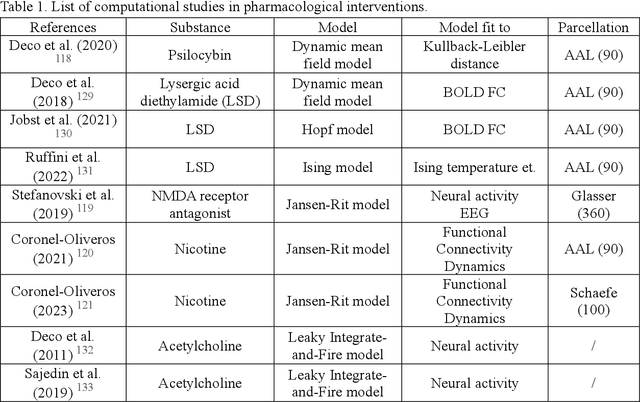
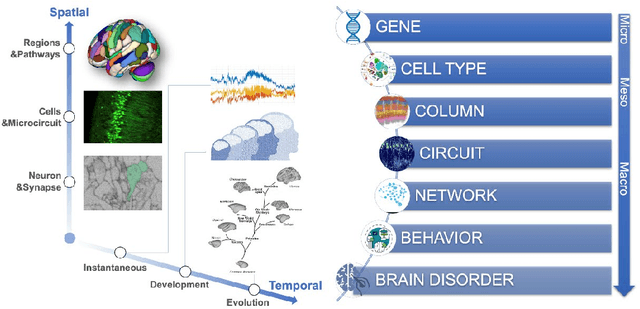
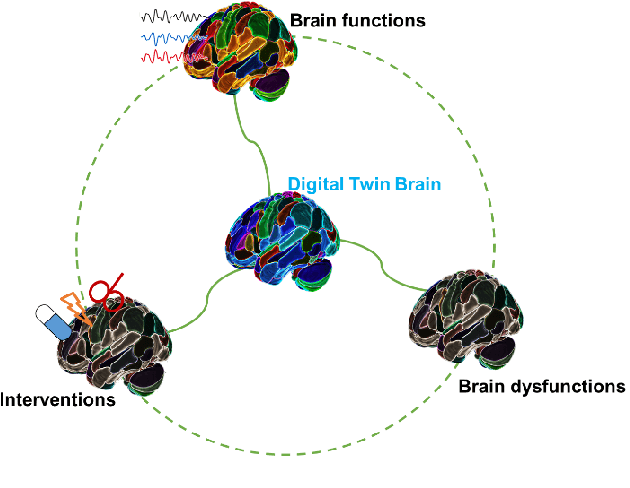
In recent years, advances in neuroscience and artificial intelligence have paved the way for unprecedented opportunities for understanding the complexity of the brain and its emulation by computational systems. Cutting-edge advancements in neuroscience research have revealed the intricate relationship between brain structure and function, while the success of artificial neural networks highlights the importance of network architecture. Now is the time to bring them together to better unravel how intelligence emerges from the brain's multiscale repositories. In this review, we propose the Digital Twin Brain (DTB) as a transformative platform that bridges the gap between biological and artificial intelligence. It consists of three core elements: the brain structure that is fundamental to the twinning process, bottom-layer models to generate brain functions, and its wide spectrum of applications. Crucially, brain atlases provide a vital constraint, preserving the brain's network organization within the DTB. Furthermore, we highlight open questions that invite joint efforts from interdisciplinary fields and emphasize the far-reaching implications of the DTB. The DTB can offer unprecedented insights into the emergence of intelligence and neurological disorders, which holds tremendous promise for advancing our understanding of both biological and artificial intelligence, and ultimately propelling the development of artificial general intelligence and facilitating precision mental healthcare.
Identifiability Guarantees for Causal Disentanglement from Soft Interventions
Jul 13, 2023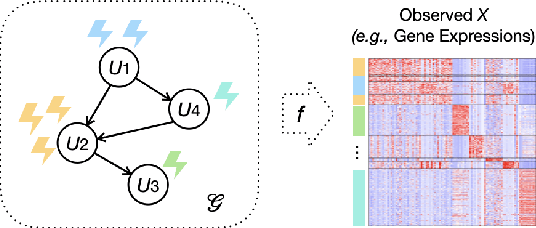
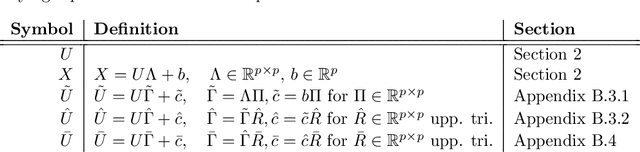
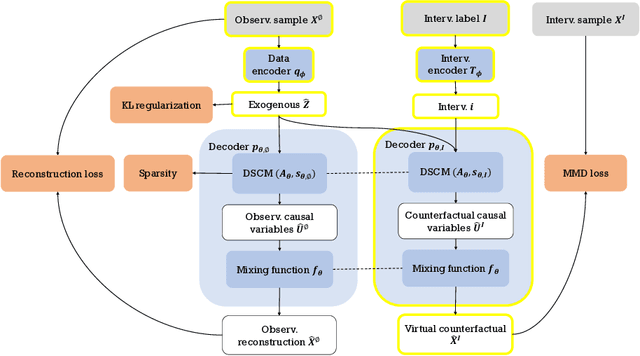
Causal disentanglement aims to uncover a representation of data using latent variables that are interrelated through a causal model. Such a representation is identifiable if the latent model that explains the data is unique. In this paper, we focus on the scenario where unpaired observational and interventional data are available, with each intervention changing the mechanism of a latent variable. When the causal variables are fully observed, statistically consistent algorithms have been developed to identify the causal model under faithfulness assumptions. We here show that identifiability can still be achieved with unobserved causal variables, given a generalized notion of faithfulness. Our results guarantee that we can recover the latent causal model up to an equivalence class and predict the effect of unseen combinations of interventions, in the limit of infinite data. We implement our causal disentanglement framework by developing an autoencoding variational Bayes algorithm and apply it to the problem of predicting combinatorial perturbation effects in genomics.