 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJingyuan Yang
EmoGen: Emotional Image Content Generation with Text-to-Image Diffusion Models
Jan 09, 2024
Recent years have witnessed remarkable progress in image generation task, where users can create visually astonishing images with high-quality. However, existing text-to-image diffusion models are proficient in generating concrete concepts (dogs) but encounter challenges with more abstract ones (emotions). Several efforts have been made to modify image emotions with color and style adjustments, facing limitations in effectively conveying emotions with fixed image contents. In this work, we introduce Emotional Image Content Generation (EICG), a new task to generate semantic-clear and emotion-faithful images given emotion categories. Specifically, we propose an emotion space and construct a mapping network to align it with the powerful Contrastive Language-Image Pre-training (CLIP) space, providing a concrete interpretation of abstract emotions. Attribute loss and emotion confidence are further proposed to ensure the semantic diversity and emotion fidelity of the generated images. Our method outperforms the state-of-the-art text-to-image approaches both quantitatively and qualitatively, where we derive three custom metrics, i.e., emotion accuracy, semantic clarity and semantic diversity. In addition to generation, our method can help emotion understanding and inspire emotional art design.
O-PRESS: Boosting OCT axial resolution with Prior guidance, Recurrence, and Equivariant Self-Supervision
Jan 06, 2024Optical coherence tomography (OCT) is a noninvasive technology that enables real-time imaging of tissue microanatomies. The axial resolution of OCT is intrinsically constrained by the spectral bandwidth of the employed light source while maintaining a fixed center wavelength for a specific application. Physically extending this bandwidth faces strong limitations and requires a substantial cost. We present a novel computational approach, called as O-PRESS, for boosting the axial resolution of OCT with Prior Guidance, a Recurrent mechanism, and Equivariant Self-Supervision. Diverging from conventional superresolution methods that rely on physical models or data-driven techniques, our method seamlessly integrates OCT modeling and deep learning, enabling us to achieve real-time axial-resolution enhancement exclusively from measurements without a need for paired images. Our approach solves two primary tasks of resolution enhancement and noise reduction with one treatment. Both tasks are executed in a self-supervised manner, with equivariance imaging and free space priors guiding their respective processes. Experimental evaluations, encompassing both quantitative metrics and visual assessments, consistently verify the efficacy and superiority of our approach, which exhibits performance on par with fully supervised methods. Importantly, the robustness of our model is affirmed, showcasing its dual capability to enhance axial resolution while concurrently improving the signal-to-noise ratio.
EmoSet: A Large-scale Visual Emotion Dataset with Rich Attributes
Jul 28, 2023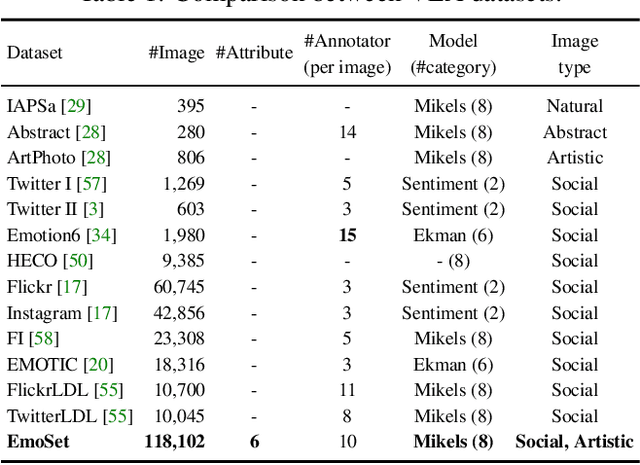
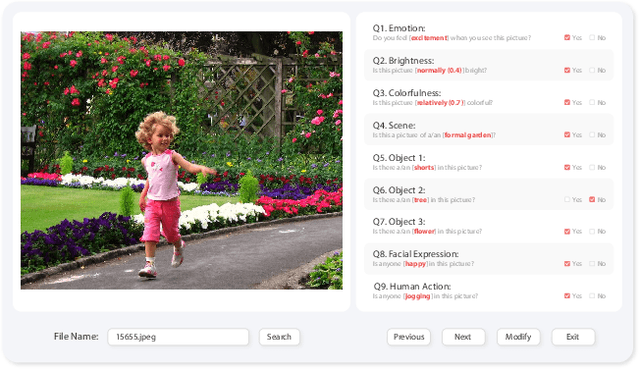
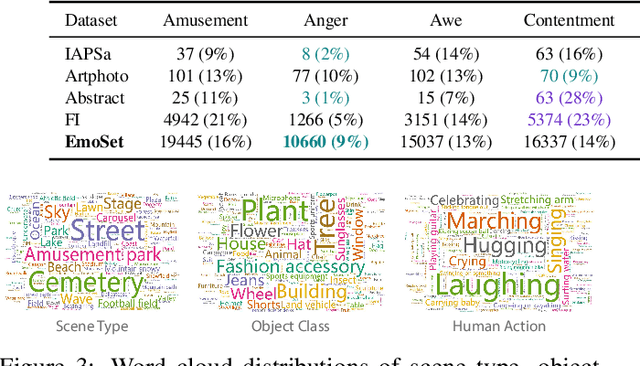
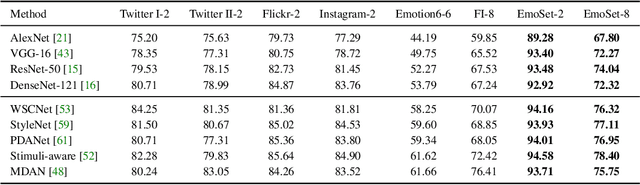
Visual Emotion Analysis (VEA) aims at predicting people's emotional responses to visual stimuli. This is a promising, yet challenging, task in affective computing, which has drawn increasing attention in recent years. Most of the existing work in this area focuses on feature design, while little attention has been paid to dataset construction. In this work, we introduce EmoSet, the first large-scale visual emotion dataset annotated with rich attributes, which is superior to existing datasets in four aspects: scale, annotation richness, diversity, and data balance. EmoSet comprises 3.3 million images in total, with 118,102 of these images carefully labeled by human annotators, making it five times larger than the largest existing dataset. EmoSet includes images from social networks, as well as artistic images, and it is well balanced between different emotion categories. Motivated by psychological studies, in addition to emotion category, each image is also annotated with a set of describable emotion attributes: brightness, colorfulness, scene type, object class, facial expression, and human action, which can help understand visual emotions in a precise and interpretable way. The relevance of these emotion attributes is validated by analyzing the correlations between them and visual emotion, as well as by designing an attribute module to help visual emotion recognition. We believe EmoSet will bring some key insights and encourage further research in visual emotion analysis and understanding. Project page: https://vcc.tech/EmoSet.
Cross-domain Collaborative Learning for Recognizing Multiple Retinal Diseases from Wide-Field Fundus Images
May 14, 2023
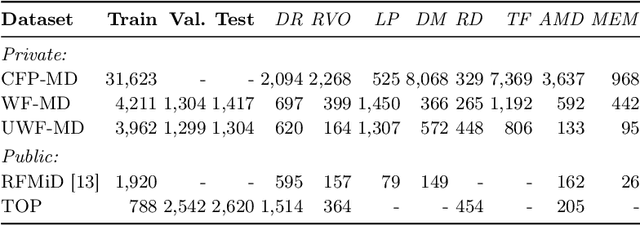
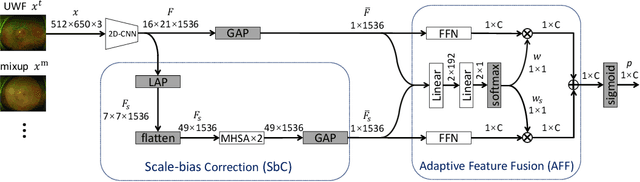

This paper addresses the emerging task of recognizing multiple retinal diseases from wide-field (WF) and ultra-wide-field (UWF) fundus images. For an effective reuse of existing labeled color fundus photo (CFP) data, we propose Cross-domain Collaborative Learning (CdCL). Inspired by the success of fixed-ratio based mixup in unsupervised domain adaptation, we re-purpose this strategy for the current task. Due to the intrinsic disparity between the field-of-view of CFP and WF/UWF images, a scale bias naturally exists in a mixup sample that the anatomic structure from a CFP image will be considerably larger than its WF/UWF counterpart. The CdCL method resolves the issue by Scale-bias Correction, which employs Transformers for producing scale-invariant features. As demonstrated by extensive experiments on multiple datasets covering both WF and UWF images, the proposed method compares favorably against a number of competitive baselines.
Knowledge-augmented Frame Semantic Parsing with Hybrid Prompt-tuning
Mar 25, 2023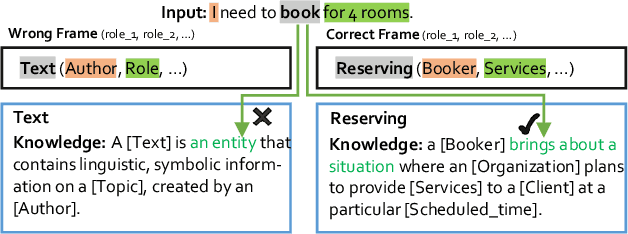
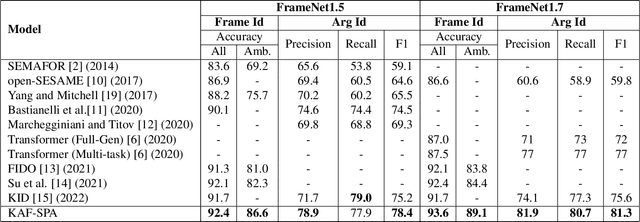
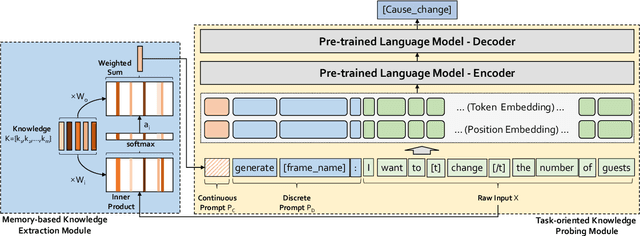
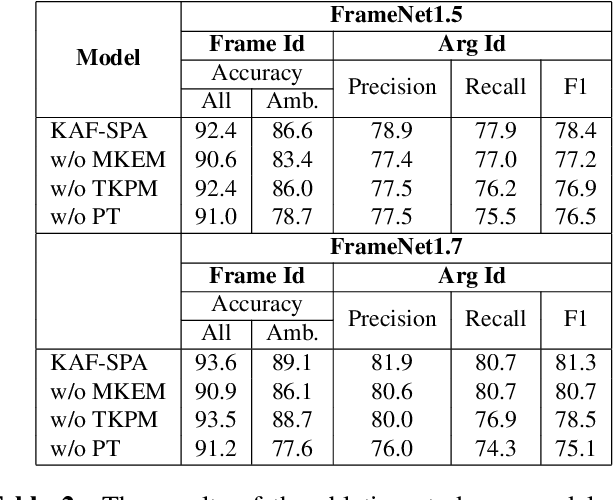
Frame semantics-based approaches have been widely used in semantic parsing tasks and have become mainstream. It remains challenging to disambiguate frame representations evoked by target lexical units under different contexts. Pre-trained Language Models (PLMs) have been used in semantic parsing and significantly improve the accuracy of neural parsers. However, the PLMs-based approaches tend to favor collocated patterns presented in the training data, leading to inaccurate outcomes. The intuition here is to design a mechanism to optimally use knowledge captured in semantic frames in conjunction with PLMs to disambiguate frames. We propose a novel Knowledge-Augmented Frame Semantic Parsing Architecture (KAF-SPA) to enhance semantic representation by incorporating accurate frame knowledge into PLMs during frame semantic parsing. Specifically, a Memory-based Knowledge Extraction Module (MKEM) is devised to select accurate frame knowledge and construct the continuous templates in the high dimensional vector space. Moreover, we design a Task-oriented Knowledge Probing Module (TKPM) using hybrid prompts (in terms of continuous and discrete prompts) to incorporate the selected knowledge into the PLMs and adapt PLMs to the tasks of frame and argument identification. Experimental results on two public FrameNet datasets demonstrate that our method significantly outperforms strong baselines (by more than +3$\%$ in F1), achieving state-of-art results on the current benchmark. Ablation studies verify the effectiveness of KAF-SPA.
ASR Error Correction with Constrained Decoding on Operation Prediction
Aug 09, 2022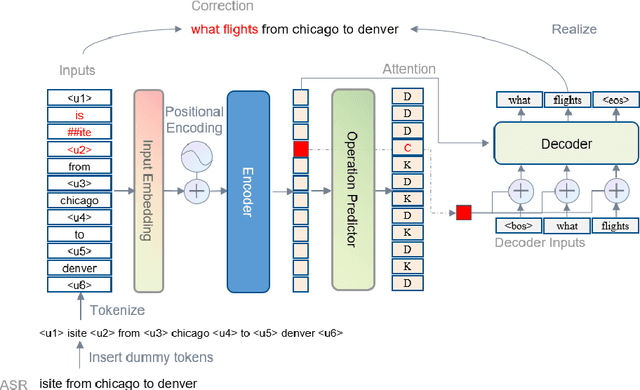
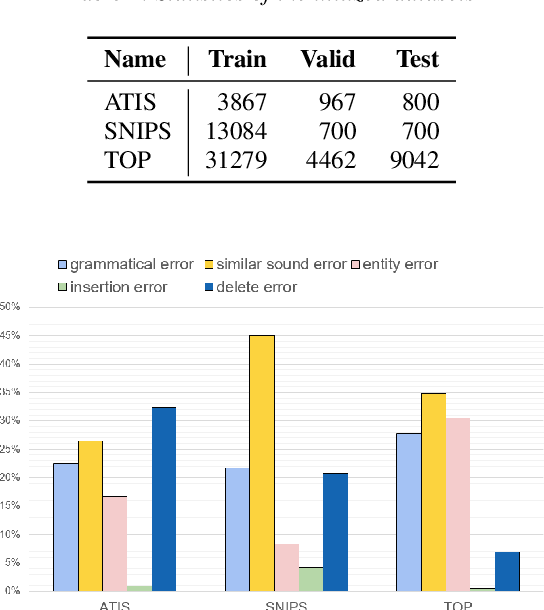
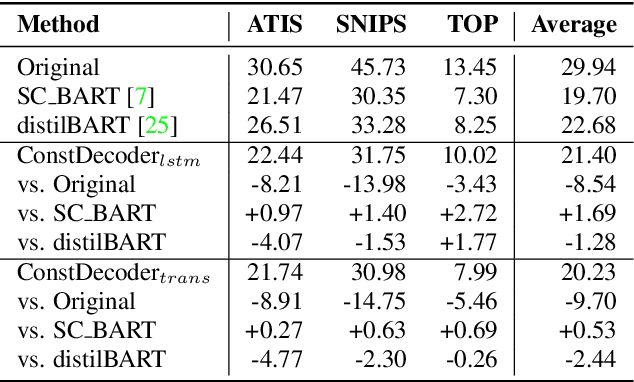
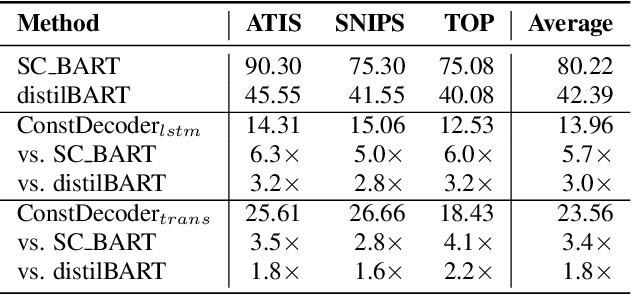
Error correction techniques remain effective to refine outputs from automatic speech recognition (ASR) models. Existing end-to-end error correction methods based on an encoder-decoder architecture process all tokens in the decoding phase, creating undesirable latency. In this paper, we propose an ASR error correction method utilizing the predictions of correction operations. More specifically, we construct a predictor between the encoder and the decoder to learn if a token should be kept ("K"), deleted ("D"), or changed ("C") to restrict decoding to only part of the input sequence embeddings (the "C" tokens) for fast inference. Experiments on three public datasets demonstrate the effectiveness of the proposed approach in reducing the latency of the decoding process in ASR correction. It enhances the inference speed by at least three times (3.4 and 5.7 times) while maintaining the same level of accuracy (with WER reductions of 0.53% and 1.69% respectively) for our two proposed models compared to a solid encoder-decoder baseline. In the meantime, we produce and release a benchmark dataset contributing to the ASR error correction community to foster research along this line.
Seeking Subjectivity in Visual Emotion Distribution Learning
Jul 25, 2022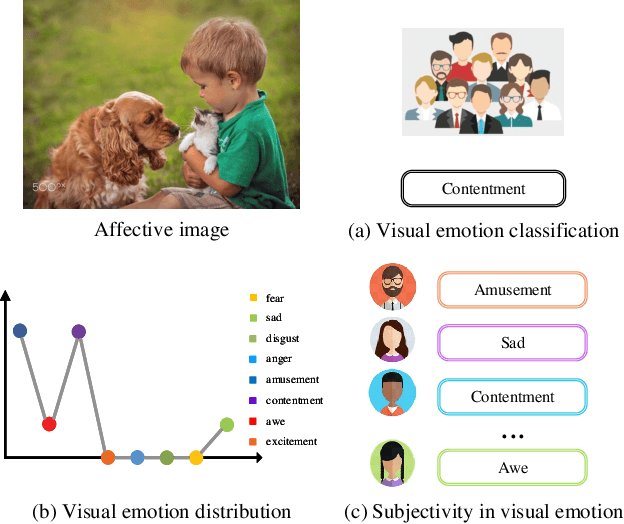
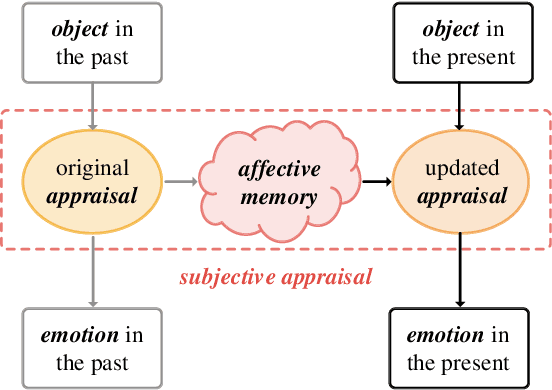
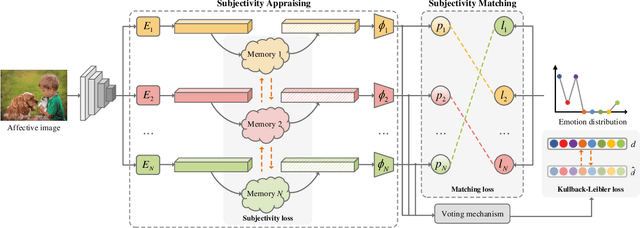
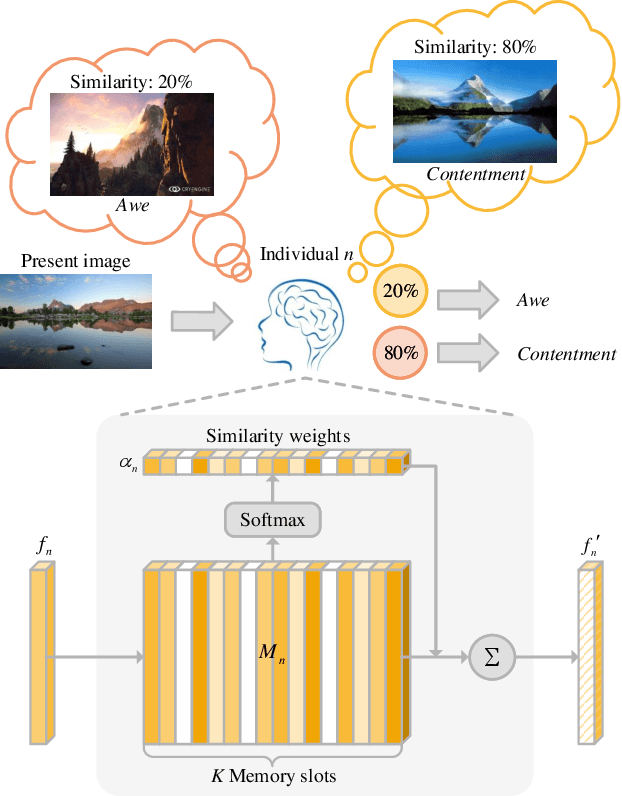
Visual Emotion Analysis (VEA), which aims to predict people's emotions towards different visual stimuli, has become an attractive research topic recently. Rather than a single label classification task, it is more rational to regard VEA as a Label Distribution Learning (LDL) problem by voting from different individuals. Existing methods often predict visual emotion distribution in a unified network, neglecting the inherent subjectivity in its crowd voting process. In psychology, the \textit{Object-Appraisal-Emotion} model has demonstrated that each individual's emotion is affected by his/her subjective appraisal, which is further formed by the affective memory. Inspired by this, we propose a novel \textit{Subjectivity Appraise-and-Match Network (SAMNet)} to investigate the subjectivity in visual emotion distribution. To depict the diversity in crowd voting process, we first propose the \textit{Subjectivity Appraising} with multiple branches, where each branch simulates the emotion evocation process of a specific individual. Specifically, we construct the affective memory with an attention-based mechanism to preserve each individual's unique emotional experience. A subjectivity loss is further proposed to guarantee the divergence between different individuals. Moreover, we propose the \textit{Subjectivity Matching} with a matching loss, aiming at assigning unordered emotion labels to ordered individual predictions in a one-to-one correspondence with the Hungarian algorithm. Extensive experiments and comparisons are conducted on public visual emotion distribution datasets, and the results demonstrate that the proposed SAMNet consistently outperforms the state-of-the-art methods. Ablation study verifies the effectiveness of our method and visualization proves its interpretability.
Don't Stop Learning: Towards Continual Learning for the CLIP Model
Jul 20, 2022
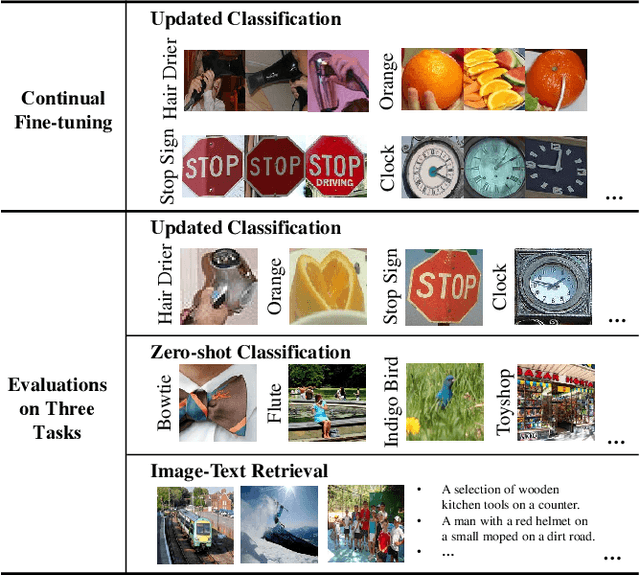
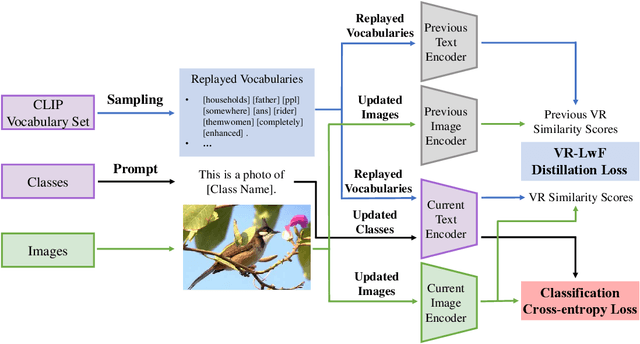
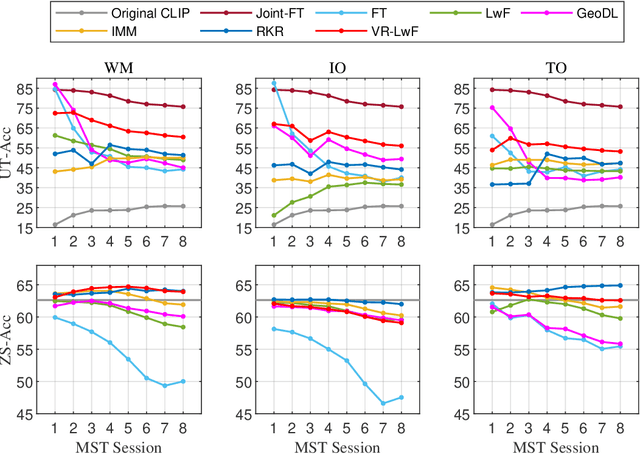
The Contrastive Language-Image Pre-training (CLIP) Model is a recently proposed large-scale pre-train model which attracts increasing attention in the computer vision community. Benefiting from its gigantic image-text training set, the CLIP model has learned outstanding capabilities in zero-shot learning and image-text matching. To boost the recognition performance of CLIP on some target visual concepts, it is often desirable to further update the CLIP model by fine-tuning some classes-of-interest on extra training data. This operation, however, raises an important concern: will the update hurt the zero-shot learning or image-text matching capability of the CLIP, i.e., the catastrophic forgetting issue? If yes, could existing continual learning algorithms be adapted to alleviate the risk of catastrophic forgetting? To answer these questions, this work conducts a systemic study on the continual learning issue of the CLIP model. We construct evaluation protocols to measure the impact of fine-tuning updates and explore different ways to upgrade existing continual learning methods to mitigate the forgetting issue of the CLIP model. Our study reveals the particular challenges of CLIP continual learning problem and lays a foundation for further researches. Moreover, we propose a new algorithm, dubbed Learning without Forgetting via Replayed Vocabulary (VR-LwF), which shows exact effectiveness for alleviating the forgetting issue of the CLIP model.
Lesion Localization in OCT by Semi-Supervised Object Detection
Apr 24, 2022
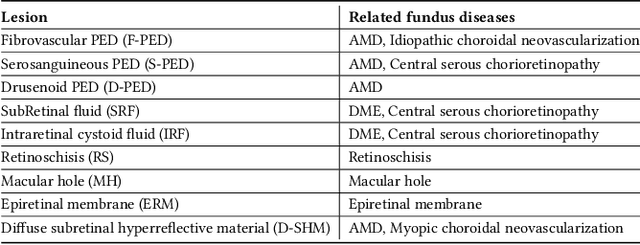


Over 300 million people worldwide are affected by various retinal diseases. By noninvasive Optical Coherence Tomography (OCT) scans, a number of abnormal structural changes in the retina, namely retinal lesions, can be identified. Automated lesion localization in OCT is thus important for detecting retinal diseases at their early stage. To conquer the lack of manual annotation for deep supervised learning, this paper presents a first study on utilizing semi-supervised object detection (SSOD) for lesion localization in OCT images. To that end, we develop a taxonomy to provide a unified and structured viewpoint of the current SSOD methods, and consequently identify key modules in these methods. To evaluate the influence of these modules in the new task, we build OCT-SS, a new dataset consisting of over 1k expert-labeled OCT B-scan images and over 13k unlabeled B-scans. Extensive experiments on OCT-SS identify Unbiased Teacher (UnT) as the best current SSOD method for lesion localization. Moreover, we improve over this strong baseline, with mAP increased from 49.34 to 50.86.
SOLVER: Scene-Object Interrelated Visual Emotion Reasoning Network
Oct 24, 2021
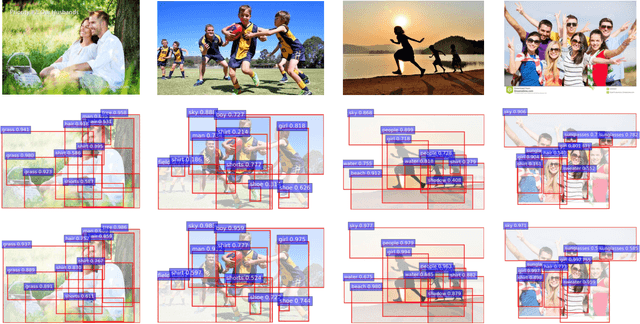


Visual Emotion Analysis (VEA) aims at finding out how people feel emotionally towards different visual stimuli, which has attracted great attention recently with the prevalence of sharing images on social networks. Since human emotion involves a highly complex and abstract cognitive process, it is difficult to infer visual emotions directly from holistic or regional features in affective images. It has been demonstrated in psychology that visual emotions are evoked by the interactions between objects as well as the interactions between objects and scenes within an image. Inspired by this, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict emotions from images. To mine the emotional relationships between distinct objects, we first build up an Emotion Graph based on semantic concepts and visual features. Then, we conduct reasoning on the Emotion Graph using Graph Convolutional Network (GCN), yielding emotion-enhanced object features. We also design a Scene-Object Fusion Module to integrate scenes and objects, which exploits scene features to guide the fusion process of object features with the proposed scene-based attention mechanism. Extensive experiments and comparisons are conducted on eight public visual emotion datasets, and the results demonstrate that the proposed SOLVER consistently outperforms the state-of-the-art methods by a large margin. Ablation studies verify the effectiveness of our method and visualizations prove its interpretability, which also bring new insight to explore the mysteries in VEA. Notably, we further discuss SOLVER on three other potential datasets with extended experiments, where we validate the robustness of our method and notice some limitations of it.
* Accepted by TIP