 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNan Zhou
iVPT: Improving Task-relevant Information Sharing in Visual Prompt Tuning by Cross-layer Dynamic Connection
Apr 08, 2024
Recent progress has shown great potential of visual prompt tuning (VPT) when adapting pre-trained vision transformers to various downstream tasks. However, most existing solutions independently optimize prompts at each layer, thereby neglecting the usage of task-relevant information encoded in prompt tokens across layers. Additionally, existing prompt structures are prone to interference from task-irrelevant noise in input images, which can do harm to the sharing of task-relevant information. In this paper, we propose a novel VPT approach, \textbf{iVPT}. It innovatively incorporates a cross-layer dynamic connection (CDC) for input prompt tokens from adjacent layers, enabling effective sharing of task-relevant information. Furthermore, we design a dynamic aggregation (DA) module that facilitates selective sharing of information between layers. The combination of CDC and DA enhances the flexibility of the attention process within the VPT framework. Building upon these foundations, iVPT introduces an attentive reinforcement (AR) mechanism, by automatically identifying salient image tokens, which are further enhanced by prompt tokens in an additive manner. Extensive experiments on 24 image classification and semantic segmentation benchmarks clearly demonstrate the advantage of the proposed iVPT, compared to the state-of-the-art counterparts.
Capturing Shock Waves by Relaxation Neural Networks
Apr 01, 2024In this paper, we put forward a neural network framework to solve the nonlinear hyperbolic systems. This framework, named relaxation neural networks(RelaxNN), is a simple and scalable extension of physics-informed neural networks(PINN). It is shown later that a typical PINN framework struggles to handle shock waves that arise in hyperbolic systems' solutions. This ultimately results in the failure of optimization that is based on gradient descent in the training process. Relaxation systems provide a smooth asymptotic to the discontinuity solution, under the expectation that macroscopic problems can be solved from a microscopic perspective. Based on relaxation systems, the RelaxNN framework alleviates the conflict of losses in the training process of the PINN framework. In addition to the remarkable results demonstrated in numerical simulations, most of the acceleration techniques and improvement strategies aimed at the standard PINN framework can also be applied to the RelaxNN framework.
DR-Tune: Improving Fine-tuning of Pretrained Visual Models by Distribution Regularization with Semantic Calibration
Aug 23, 2023The visual models pretrained on large-scale benchmarks encode general knowledge and prove effective in building more powerful representations for downstream tasks. Most existing approaches follow the fine-tuning paradigm, either by initializing or regularizing the downstream model based on the pretrained one. The former fails to retain the knowledge in the successive fine-tuning phase, thereby prone to be over-fitting, and the latter imposes strong constraints to the weights or feature maps of the downstream model without considering semantic drift, often incurring insufficient optimization. To deal with these issues, we propose a novel fine-tuning framework, namely distribution regularization with semantic calibration (DR-Tune). It employs distribution regularization by enforcing the downstream task head to decrease its classification error on the pretrained feature distribution, which prevents it from over-fitting while enabling sufficient training of downstream encoders. Furthermore, to alleviate the interference by semantic drift, we develop the semantic calibration (SC) module to align the global shape and class centers of the pretrained and downstream feature distributions. Extensive experiments on widely used image classification datasets show that DR-Tune consistently improves the performance when combing with various backbones under different pretraining strategies. Code is available at: https://github.com/weeknan/DR-Tune.
CONA: A novel CONtext-Aware instruction paradigm for communication using large language model
May 26, 2023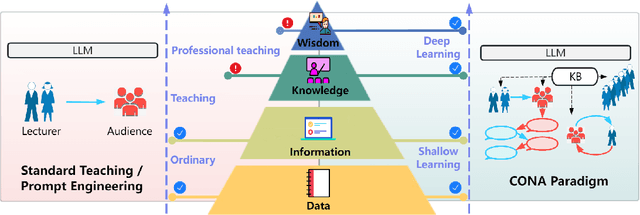
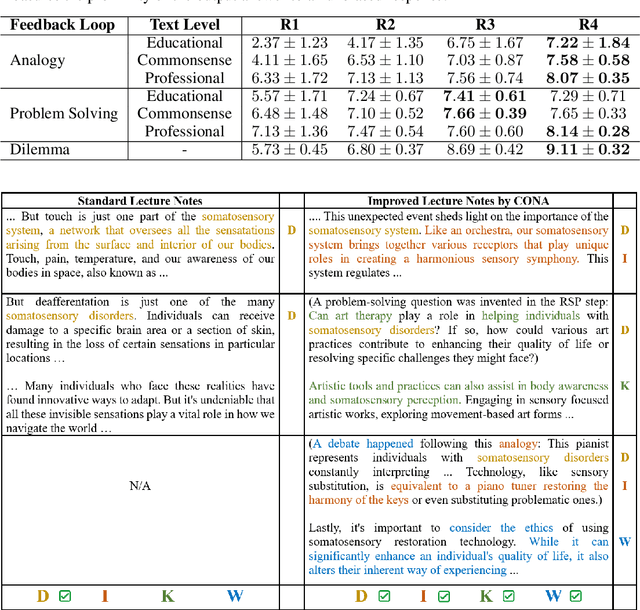
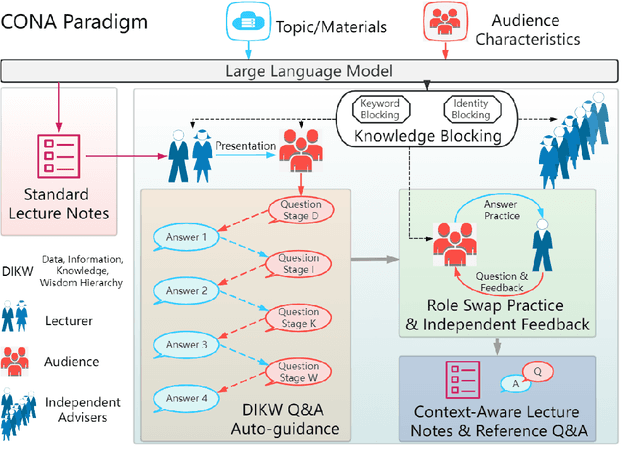
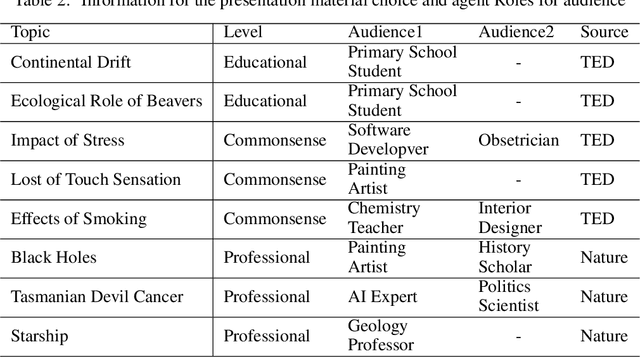
We introduce CONA, a novel context-aware instruction paradigm for effective knowledge dissemination using generative pre-trained transformer (GPT) models. CONA is a flexible framework designed to leverage the capabilities of Large Language Models (LLMs) and incorporate DIKW (Data, Information, Knowledge, Wisdom) hierarchy to automatically instruct and optimise presentation content, anticipate potential audience inquiries, and provide context-aware answers that adaptive to the knowledge level of the audience group. The unique aspect of the CONA paradigm lies in its combination of an independent advisory mechanism and a recursive feedback loop rooted on the DIKW hierarchy. This synergy significantly enhances context-aware contents, ensuring they are accessible and easily comprehended by the audience. This paradigm is an early pioneer to explore new methods for knowledge dissemination and communication in the LLM era, offering effective support for everyday knowledge sharing scenarios. We conduct experiments on a range of audience roles, along with materials from various disciplines using GPT4. Both quantitative and qualitative results demonstrated that the proposed CONA paradigm achieved remarkable performance compared to the outputs guided by conventional prompt engineering.
Motion Sensitive Contrastive Learning for Self-supervised Video Representation
Aug 12, 2022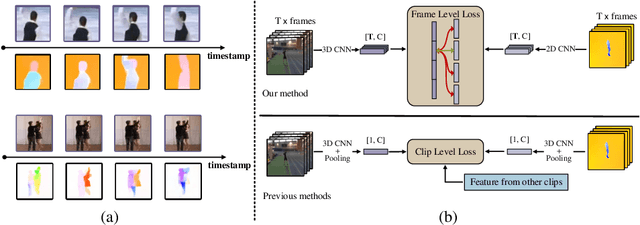
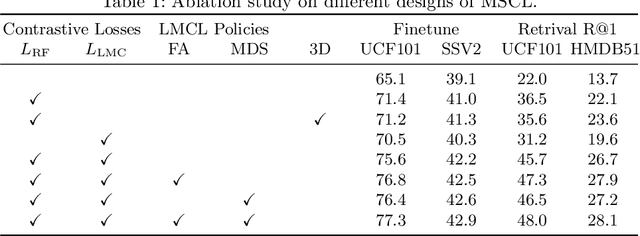
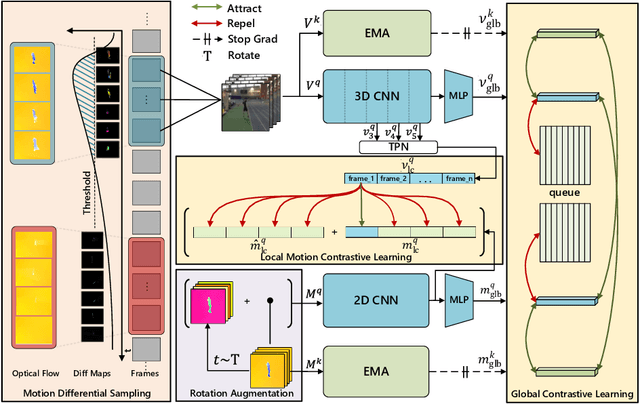
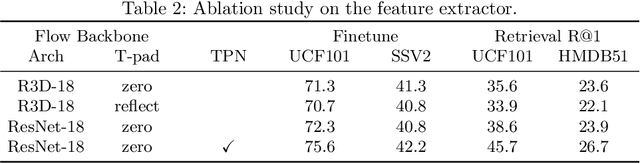
Contrastive learning has shown great potential in video representation learning. However, existing approaches fail to sufficiently exploit short-term motion dynamics, which are crucial to various down-stream video understanding tasks. In this paper, we propose Motion Sensitive Contrastive Learning (MSCL) that injects the motion information captured by optical flows into RGB frames to strengthen feature learning. To achieve this, in addition to clip-level global contrastive learning, we develop Local Motion Contrastive Learning (LMCL) with frame-level contrastive objectives across the two modalities. Moreover, we introduce Flow Rotation Augmentation (FRA) to generate extra motion-shuffled negative samples and Motion Differential Sampling (MDS) to accurately screen training samples. Extensive experiments on standard benchmarks validate the effectiveness of the proposed method. With the commonly-used 3D ResNet-18 as the backbone, we achieve the top-1 accuracies of 91.5\% on UCF101 and 50.3\% on Something-Something v2 for video classification, and a 65.6\% Top-1 Recall on UCF101 for video retrieval, notably improving the state-of-the-art.
A Semantic Segmentation Network for Urban-Scale Building Footprint Extraction Using RGB Satellite Imagery
Apr 02, 2021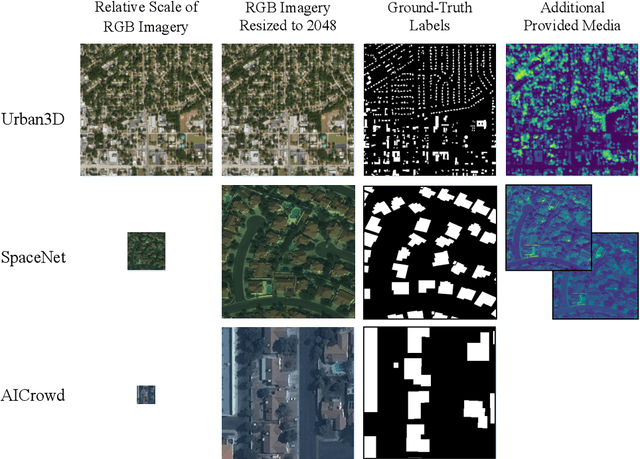
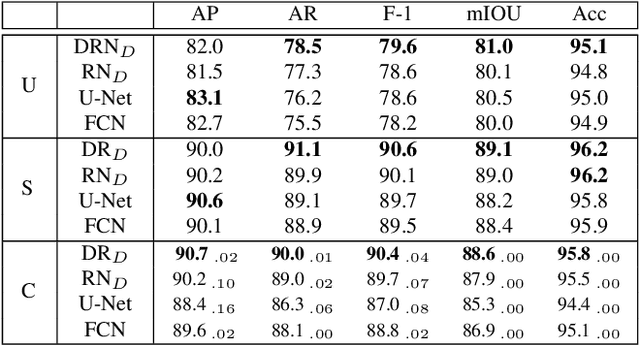
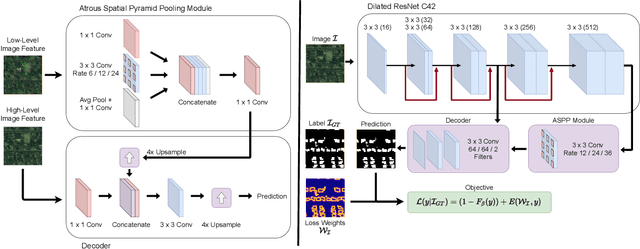
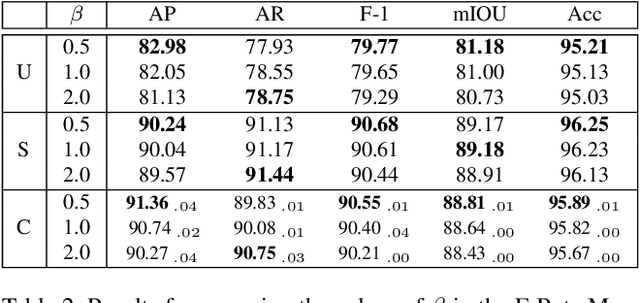
Urban areas consume over two-thirds of the world's energy and account for more than 70 percent of global CO2 emissions. As stated in IPCC's Global Warming of 1.5C report, achieving carbon neutrality by 2050 requires a scalable approach that can be applied in a global context. Conventional methods of collecting data on energy use and emissions of buildings are extremely expensive and require specialized geometry information that not all cities have readily available. High-quality building footprint generation from satellite images can accelerate this predictive process and empower municipal decision-making at scale. However, previous deep learning-based approaches use supplemental data such as point cloud data, building height information, and multi-band imagery - which has limited availability and is difficult to produce. In this paper, we propose a modified DeeplabV3+ module with a Dilated ResNet backbone to generate masks of building footprints from only three-channel RGB satellite imagery. Furthermore, we introduce an F-Beta measure in our objective function to help the model account for skewed class distributions. In addition to an F-Beta objective function, we incorporate an exponentially weighted boundary loss and use a cross-dataset training strategy to further increase the quality of predictions. As a result, we achieve state-of-the-art performance across three standard benchmarks and demonstrate that our RGB-only method is agnostic to the scale, resolution, and urban density of satellite imagery.
Density-Aware Convolutional Networks with Context Encoding for Airborne LiDAR Point Cloud Classification
Oct 14, 2019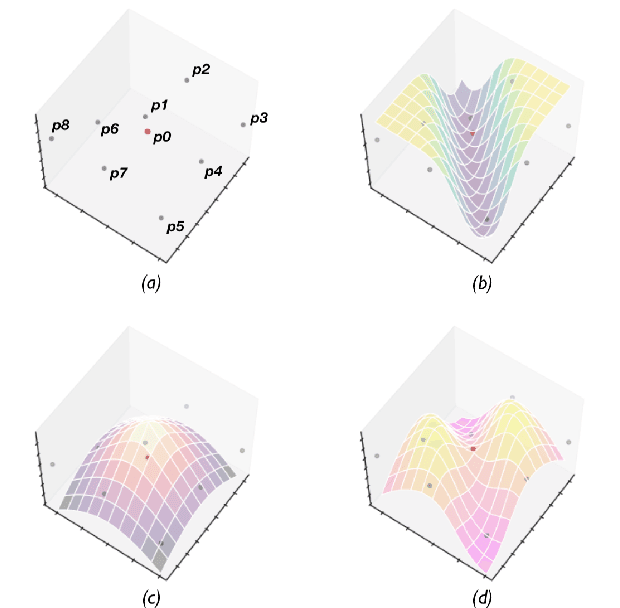
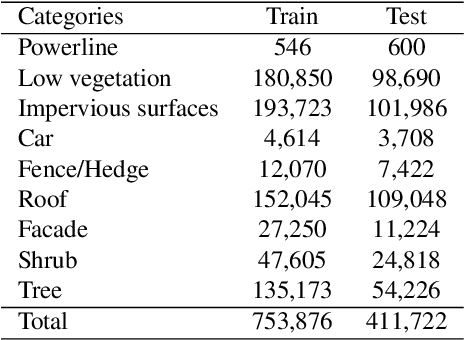
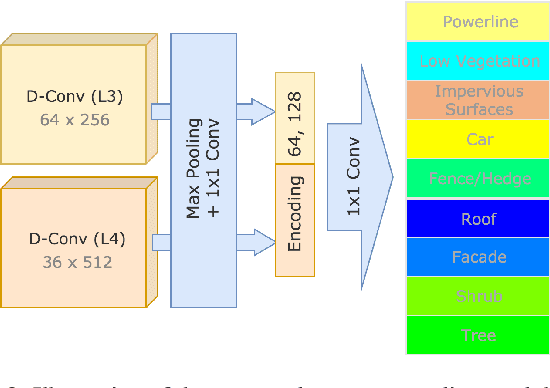
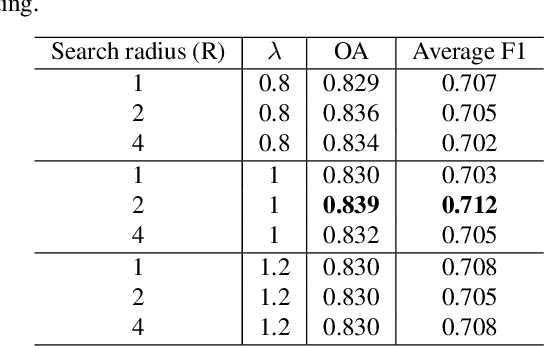
To better address challenging issues of the irregularity and inhomogeneity inherently present in 3D point clouds, researchers have been shifting their focus from the design of hand-craft point feature towards the learning of 3D point signatures using deep neural networks for 3D point cloud classification. Recent proposed deep learning based point cloud classification methods either apply 2D CNN on projected feature images or apply 1D convolutional layers directly on raw point sets. These methods cannot adequately recognize fine-grained local structures caused by the uneven density distribution of the point cloud data. In this paper, to address this challenging issue, we introduced a density-aware convolution module which uses the point-wise density to re-weight the learnable weights of convolution kernels. The proposed convolution module is able to fully approximate the 3D continuous convolution on unevenly distributed 3D point sets. Based on this convolution module, we further developed a multi-scale fully convolutional neural network with downsampling and upsampling blocks to enable hierarchical point feature learning. In addition, to regularize the global semantic context, we implemented a context encoding module to predict a global context encoding and formulated a context encoding regularizer to enforce the predicted context encoding to be aligned with the ground truth one. The overall network can be trained in an end-to-end fashion with the raw 3D coordinates as well as the height above ground as inputs. Experiments on the International Society for Photogrammetry and Remote Sensing (ISPRS) 3D labeling benchmark demonstrated the superiority of the proposed method for point cloud classification. Our model achieved a new state-of-the-art performance with an average F1 score of 71.2% and improved the performance by a large margin on several categories.
Random Directional Attack for Fooling Deep Neural Networks
Aug 06, 2019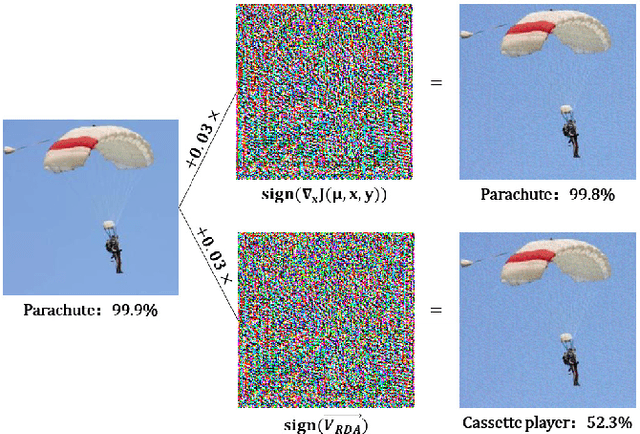

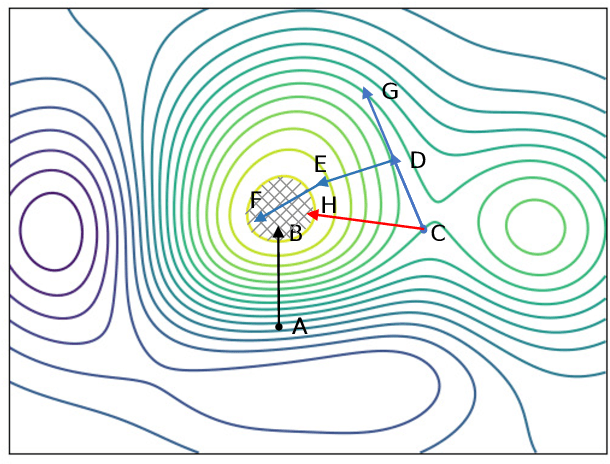
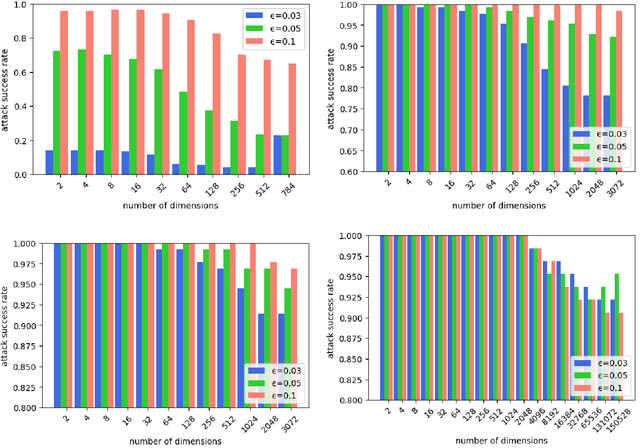
Deep neural networks (DNNs) have been widely used in many fields such as images processing, speech recognition; however, they are vulnerable to adversarial examples, and this is a security issue worthy of attention. Because the training process of DNNs converge the loss by updating the weights along the gradient descent direction, many gradient-based methods attempt to destroy the DNN model by adding perturbations in the gradient direction. Unfortunately, as the model is nonlinear in most cases, the addition of perturbations in the gradient direction does not necessarily increase loss. Thus, we propose a random directed attack (RDA) for generating adversarial examples in this paper. Rather than limiting the gradient direction to generate an attack, RDA searches the attack direction based on hill climbing and uses multiple strategies to avoid local optima that cause attack failure. Compared with state-of-the-art gradient-based methods, the attack performance of RDA is very competitive. Moreover, RDA can attack without any internal knowledge of the model, and its performance under black-box attack is similar to that of the white-box attack in most cases, which is difficult to achieve using existing gradient-based attack methods.
Algorithmic Collusion in Cournot Duopoly Market: Evidence from Experimental Economics
Feb 21, 2018
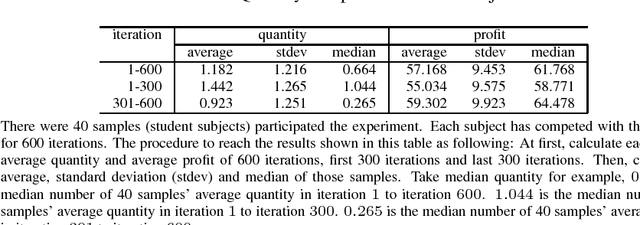
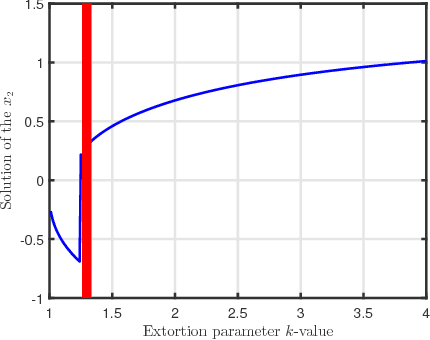
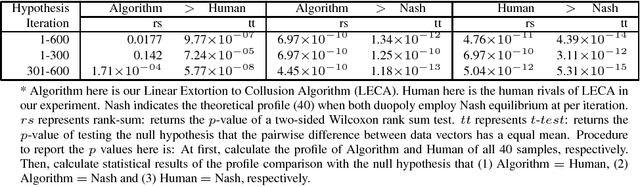
Algorithmic collusion is an emerging concept in current artificial intelligence age. Whether algorithmic collusion is a creditable threat remains as an argument. In this paper, we propose an algorithm which can extort its human rival to collude in a Cournot duopoly competing market. In experiments, we show that, the algorithm can successfully extorted its human rival and gets higher profit in long run, meanwhile the human rival will fully collude with the algorithm. As a result, the social welfare declines rapidly and stably. Both in theory and in experiment, our work confirms that, algorithmic collusion can be a creditable threat. In application, we hope, the frameworks, the algorithm design as well as the experiment environment illustrated in this work, can be an incubator or a test bed for researchers and policymakers to handle the emerging algorithmic collusion.
Global and Local Structure Preserving Sparse Subspace Learning: An Iterative Approach to Unsupervised Feature Selection
Oct 19, 2015
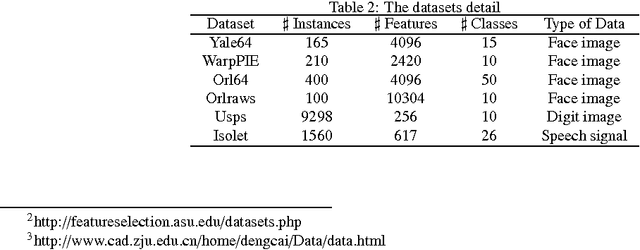
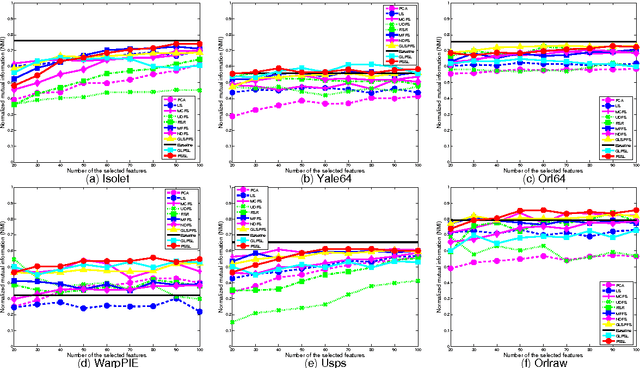
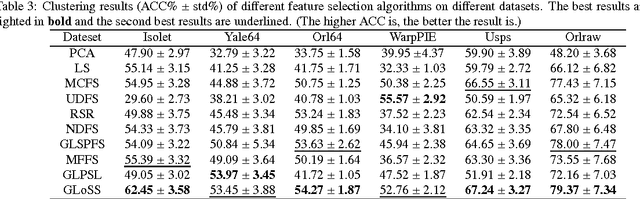
As we aim at alleviating the curse of high-dimensionality, subspace learning is becoming more popular. Existing approaches use either information about global or local structure of the data, and few studies simultaneously focus on global and local structures as the both of them contain important information. In this paper, we propose a global and local structure preserving sparse subspace learning (GLoSS) model for unsupervised feature selection. The model can simultaneously realize feature selection and subspace learning. In addition, we develop a greedy algorithm to establish a generic combinatorial model, and an iterative strategy based on an accelerated block coordinate descent is used to solve the GLoSS problem. We also provide whole iterate sequence convergence analysis of the proposed iterative algorithm. Extensive experiments are conducted on real-world datasets to show the superiority of the proposed approach over several state-of-the-art unsupervised feature selection approaches.