 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQi Jiang
Design, analysis, and manufacturing of a glass-plastic hybrid minimalist aspheric panoramic annular lens
May 05, 2024
We propose a high-performance glass-plastic hybrid minimalist aspheric panoramic annular lens (ASPAL) to solve several major limitations of the traditional panoramic annular lens (PAL), such as large size, high weight, and complex system. The field of view (FoV) of the ASPAL is 360{\deg}x(35{\deg}~110{\deg}) and the imaging quality is close to the diffraction limit. This large FoV ASPAL is composed of only 4 lenses. Moreover, we establish a physical structure model of PAL using the ray tracing method and study the influence of its physical parameters on compactness ratio. In addition, for the evaluation of local tolerances of annular surfaces, we propose a tolerance analysis method suitable for ASPAL. This analytical method can effectively analyze surface irregularities on annular surfaces and provide clear guidance on manufacturing tolerances for ASPAL. Benefiting from high-precision glass molding and injection molding aspheric lens manufacturing techniques, we finally manufactured 20 ASPALs in small batches. The weight of an ASPAL prototype is only 8.5 g. Our framework provides promising insights for the application of panoramic systems in space and weight-constrained environmental sensing scenarios such as intelligent security, micro-UAVs, and micro-robots.
Global Search Optics: Automatically Exploring Optimal Solutions to Compact Computational Imaging Systems
Apr 30, 2024The popularity of mobile vision creates a demand for advanced compact computational imaging systems, which call for the development of both a lightweight optical system and an effective image reconstruction model. Recently, joint design pipelines come to the research forefront, where the two significant components are simultaneously optimized via data-driven learning to realize the optimal system design. However, the effectiveness of these designs largely depends on the initial setup of the optical system, complicated by a non-convex solution space that impedes reaching a globally optimal solution. In this work, we present Global Search Optics (GSO) to automatically design compact computational imaging systems through two parts: (i) Fused Optimization Method for Automatic Optical Design (OptiFusion), which searches for diverse initial optical systems under certain design specifications; and (ii) Efficient Physic-aware Joint Optimization (EPJO), which conducts parallel joint optimization of initial optical systems and image reconstruction networks with the consideration of physical constraints, culminating in the selection of the optimal solution. Extensive experimental results on the design of three-piece (3P) sphere computational imaging systems illustrate that the GSO serves as a transformative end-to-end lens design paradigm for superior global optimal structure searching ability, which provides compact computational imaging systems with higher imaging quality compared to traditional methods. The source code will be made publicly available at https://github.com/wumengshenyou/GSO.
Real-World Computational Aberration Correction via Quantized Domain-Mixing Representation
Mar 15, 2024
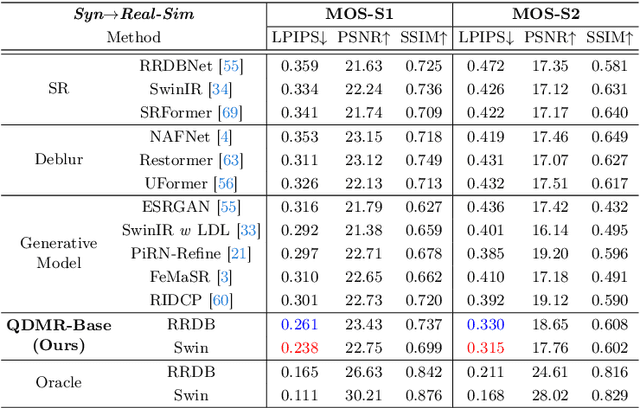
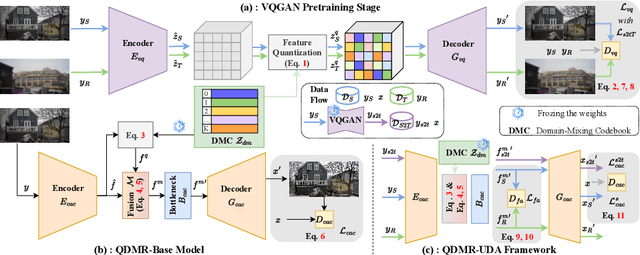
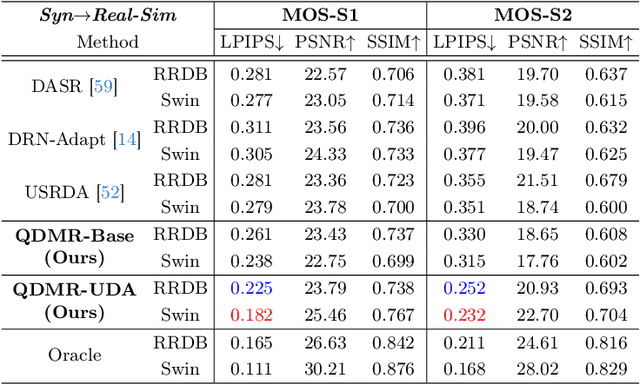
Relying on paired synthetic data, existing learning-based Computational Aberration Correction (CAC) methods are confronted with the intricate and multifaceted synthetic-to-real domain gap, which leads to suboptimal performance in real-world applications. In this paper, in contrast to improving the simulation pipeline, we deliver a novel insight into real-world CAC from the perspective of Unsupervised Domain Adaptation (UDA). By incorporating readily accessible unpaired real-world data into training, we formalize the Domain Adaptive CAC (DACAC) task, and then introduce a comprehensive Real-world aberrated images (Realab) dataset to benchmark it. The setup task presents a formidable challenge due to the intricacy of understanding the target aberration domain. To this intent, we propose a novel Quntized Domain-Mixing Representation (QDMR) framework as a potent solution to the issue. QDMR adapts the CAC model to the target domain from three key aspects: (1) reconstructing aberrated images of both domains by a VQGAN to learn a Domain-Mixing Codebook (DMC) which characterizes the degradation-aware priors; (2) modulating the deep features in CAC model with DMC to transfer the target domain knowledge; and (3) leveraging the trained VQGAN to generate pseudo target aberrated images from the source ones for convincing target domain supervision. Extensive experiments on both synthetic and real-world benchmarks reveal that the models with QDMR consistently surpass the competitive methods in mitigating the synthetic-to-real gap, which produces visually pleasant real-world CAC results with fewer artifacts. Codes and datasets will be made publicly available.
FocusFlow: Boosting Key-Points Optical Flow Estimation for Autonomous Driving
Aug 14, 2023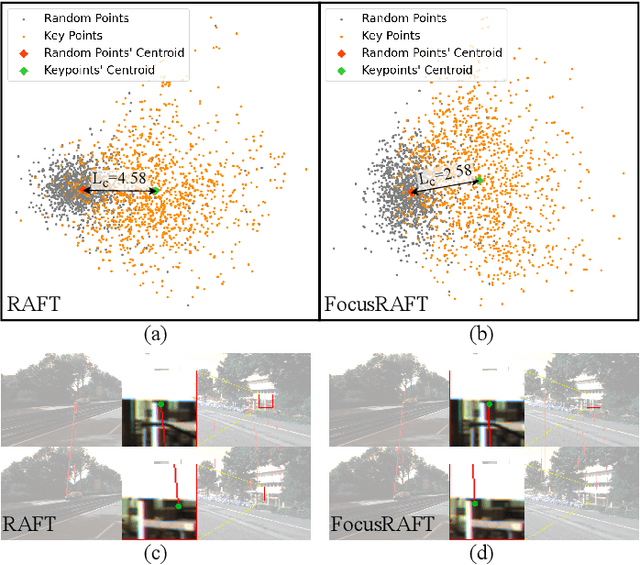
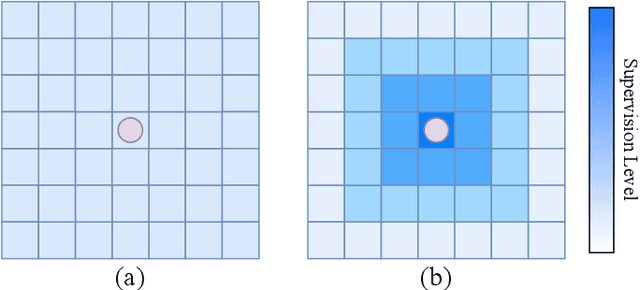
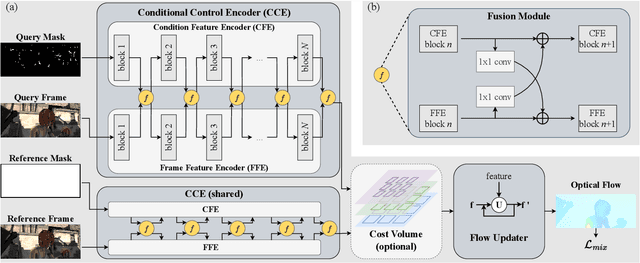
Key-point-based scene understanding is fundamental for autonomous driving applications. At the same time, optical flow plays an important role in many vision tasks. However, due to the implicit bias of equal attention on all points, classic data-driven optical flow estimation methods yield less satisfactory performance on key points, limiting their implementations in key-point-critical safety-relevant scenarios. To address these issues, we introduce a points-based modeling method that requires the model to learn key-point-related priors explicitly. Based on the modeling method, we present FocusFlow, a framework consisting of 1) a mix loss function combined with a classic photometric loss function and our proposed Conditional Point Control Loss (CPCL) function for diverse point-wise supervision; 2) a conditioned controlling model which substitutes the conventional feature encoder by our proposed Condition Control Encoder (CCE). CCE incorporates a Frame Feature Encoder (FFE) that extracts features from frames, a Condition Feature Encoder (CFE) that learns to control the feature extraction behavior of FFE from input masks containing information of key points, and fusion modules that transfer the controlling information between FFE and CFE. Our FocusFlow framework shows outstanding performance with up to +44.5% precision improvement on various key points such as ORB, SIFT, and even learning-based SiLK, along with exceptional scalability for most existing data-driven optical flow methods like PWC-Net, RAFT, and FlowFormer. Notably, FocusFlow yields competitive or superior performances rivaling the original models on the whole frame. The source code will be available at https://github.com/ZhonghuaYi/FocusFlow_official.
See More and Know More: Zero-shot Point Cloud Segmentation via Multi-modal Visual Data
Jul 20, 2023
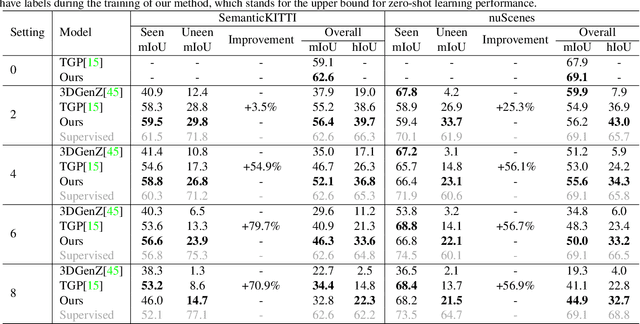
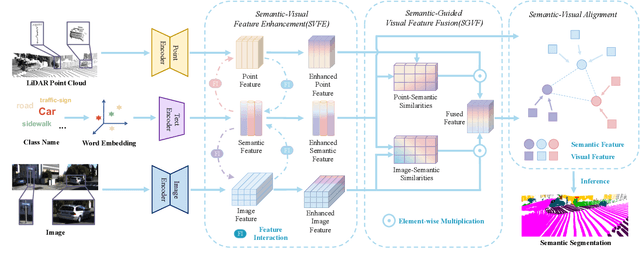
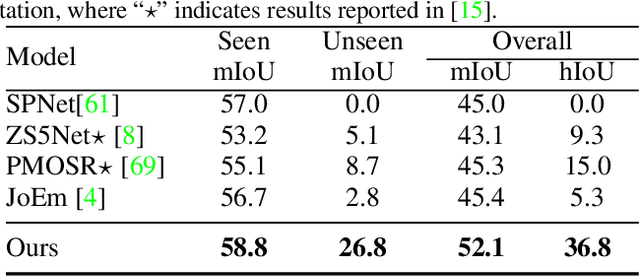
Zero-shot point cloud segmentation aims to make deep models capable of recognizing novel objects in point cloud that are unseen in the training phase. Recent trends favor the pipeline which transfers knowledge from seen classes with labels to unseen classes without labels. They typically align visual features with semantic features obtained from word embedding by the supervision of seen classes' annotations. However, point cloud contains limited information to fully match with semantic features. In fact, the rich appearance information of images is a natural complement to the textureless point cloud, which is not well explored in previous literature. Motivated by this, we propose a novel multi-modal zero-shot learning method to better utilize the complementary information of point clouds and images for more accurate visual-semantic alignment. Extensive experiments are performed in two popular benchmarks, i.e., SemanticKITTI and nuScenes, and our method outperforms current SOTA methods with 52% and 49% improvement on average for unseen class mIoU, respectively.
Semi-supervised multi-view concept decomposition
Jul 03, 2023Concept Factorization (CF), as a novel paradigm of representation learning, has demonstrated superior performance in multi-view clustering tasks. It overcomes limitations such as the non-negativity constraint imposed by traditional matrix factorization methods and leverages kernel methods to learn latent representations that capture the underlying structure of the data, thereby improving data representation. However, existing multi-view concept factorization methods fail to consider the limited labeled information inherent in real-world multi-view data. This often leads to significant performance loss. To overcome these limitations, we propose a novel semi-supervised multi-view concept factorization model, named SMVCF. In the SMVCF model, we first extend the conventional single-view CF to a multi-view version, enabling more effective exploration of complementary information across multiple views. We then integrate multi-view CF, label propagation, and manifold learning into a unified framework to leverage and incorporate valuable information present in the data. Additionally, an adaptive weight vector is introduced to balance the importance of different views in the clustering process. We further develop targeted optimization methods specifically tailored for the SMVCF model. Finally, we conduct extensive experiments on four diverse datasets with varying label ratios to evaluate the performance of SMVCF. The experimental results demonstrate the effectiveness and superiority of our proposed approach in multi-view clustering tasks.
Minimalist and High-Quality Panoramic Imaging with PSF-aware Transformers
Jun 22, 2023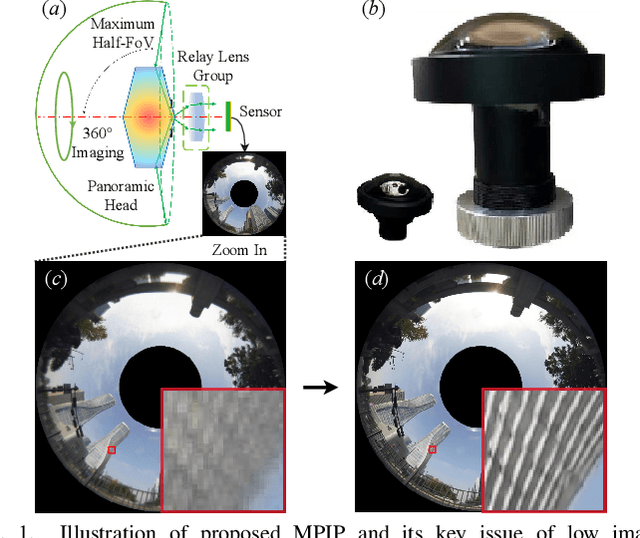



High-quality panoramic images with a Field of View (FoV) of 360-degree are essential for contemporary panoramic computer vision tasks. However, conventional imaging systems come with sophisticated lens designs and heavy optical components. This disqualifies their usage in many mobile and wearable applications where thin and portable, minimalist imaging systems are desired. In this paper, we propose a Panoramic Computational Imaging Engine (PCIE) to address minimalist and high-quality panoramic imaging. With less than three spherical lenses, a Minimalist Panoramic Imaging Prototype (MPIP) is constructed based on the design of the Panoramic Annular Lens (PAL), but with low-quality imaging results due to aberrations and small image plane size. We propose two pipelines, i.e. Aberration Correction (AC) and Super-Resolution and Aberration Correction (SR&AC), to solve the image quality problems of MPIP, with imaging sensors of small and large pixel size, respectively. To provide a universal network for the two pipelines, we leverage the information from the Point Spread Function (PSF) of the optical system and design a PSF-aware Aberration-image Recovery Transformer (PART), in which the self-attention calculation and feature extraction are guided via PSF-aware mechanisms. We train PART on synthetic image pairs from simulation and put forward the PALHQ dataset to fill the gap of real-world high-quality PAL images for low-level vision. A comprehensive variety of experiments on synthetic and real-world benchmarks demonstrates the impressive imaging results of PCIE and the effectiveness of plug-and-play PSF-aware mechanisms. We further deliver heuristic experimental findings for minimalist and high-quality panoramic imaging. Our dataset and code will be available at https://github.com/zju-jiangqi/PCIE-PART.
Event-Based Frame Interpolation with Ad-hoc Deblurring
Jan 12, 2023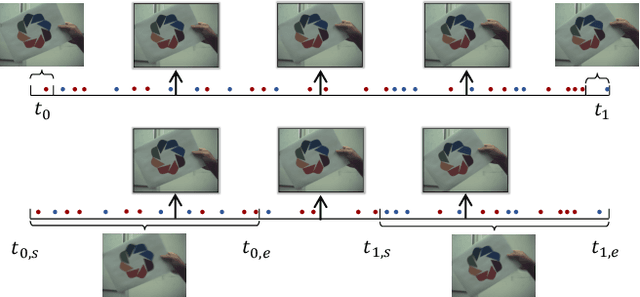
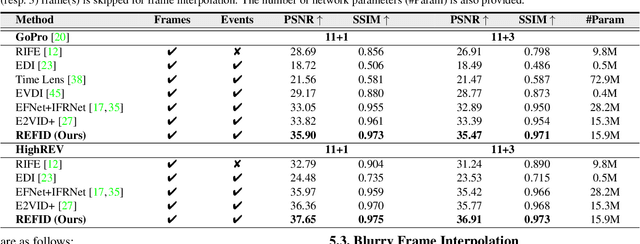
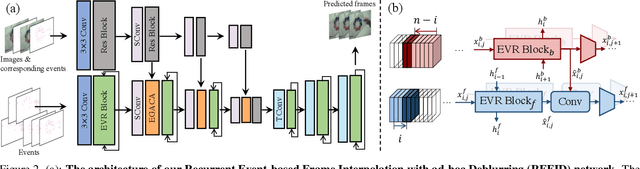

The performance of video frame interpolation is inherently correlated with the ability to handle motion in the input scene. Even though previous works recognize the utility of asynchronous event information for this task, they ignore the fact that motion may or may not result in blur in the input video to be interpolated, depending on the length of the exposure time of the frames and the speed of the motion, and assume either that the input video is sharp, restricting themselves to frame interpolation, or that it is blurry, including an explicit, separate deblurring stage before interpolation in their pipeline. We instead propose a general method for event-based frame interpolation that performs deblurring ad-hoc and thus works both on sharp and blurry input videos. Our model consists in a bidirectional recurrent network that naturally incorporates the temporal dimension of interpolation and fuses information from the input frames and the events adaptively based on their temporal proximity. In addition, we introduce a novel real-world high-resolution dataset with events and color videos named HighREV, which provides a challenging evaluation setting for the examined task. Extensive experiments on the standard GoPro benchmark and on our dataset show that our network consistently outperforms previous state-of-the-art methods on frame interpolation, single image deblurring and the joint task of interpolation and deblurring. Our code and dataset will be made publicly available.
SemanticBEVFusion: Rethink LiDAR-Camera Fusion in Unified Bird's-Eye View Representation for 3D Object Detection
Dec 09, 2022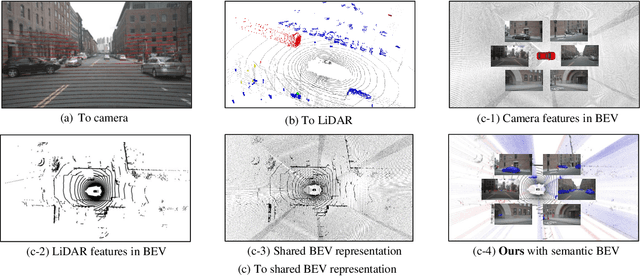

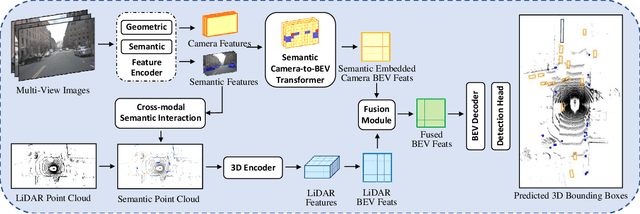
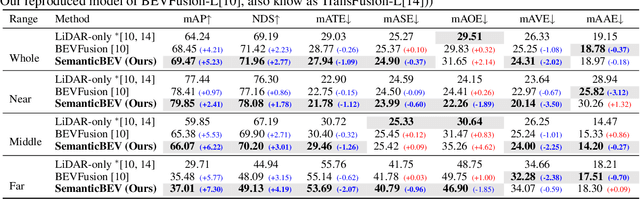
LiDAR and camera are two essential sensors for 3D object detection in autonomous driving. LiDAR provides accurate and reliable 3D geometry information while the camera provides rich texture with color. Despite the increasing popularity of fusing these two complementary sensors, the challenge remains in how to effectively fuse 3D LiDAR point cloud with 2D camera images. Recent methods focus on point-level fusion which paints the LiDAR point cloud with camera features in the perspective view or bird's-eye view (BEV)-level fusion which unifies multi-modality features in the BEV representation. In this paper, we rethink these previous fusion strategies and analyze their information loss and influences on geometric and semantic features. We present SemanticBEVFusion to deeply fuse camera features with LiDAR features in a unified BEV representation while maintaining per-modality strengths for 3D object detection. Our method achieves state-of-the-art performance on the large-scale nuScenes dataset, especially for challenging distant objects. The code will be made publicly available.
Computational Optics Meet Domain Adaptation: Transferring Semantic Segmentation Beyond Aberrations
Nov 21, 2022


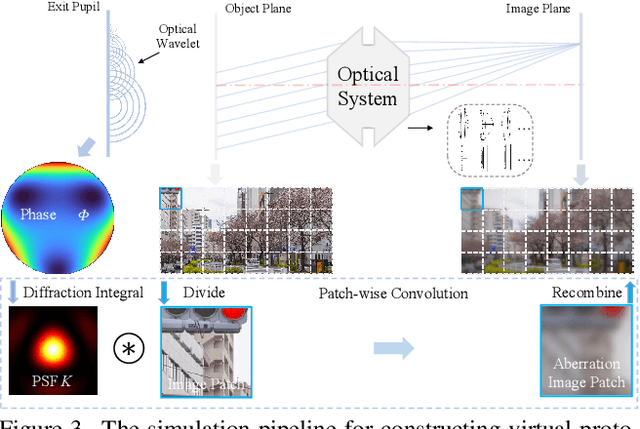
Semantic scene understanding with Minimalist Optical Systems (MOS) in mobile and wearable applications remains a challenge due to the corrupted imaging quality induced by optical aberrations. However, previous works only focus on improving the subjective imaging quality through computational optics, i.e. Computational Imaging (CI) technique, ignoring the feasibility in semantic segmentation. In this paper, we pioneer to investigate Semantic Segmentation under Optical Aberrations (SSOA) of MOS. To benchmark SSOA, we construct Virtual Prototype Lens (VPL) groups through optical simulation, generating Cityscapes-ab and KITTI-360-ab datasets under different behaviors and levels of aberrations. We look into SSOA via an unsupervised domain adaptation perspective to address the scarcity of labeled aberration data in real-world scenarios. Further, we propose Computational Imaging Assisted Domain Adaptation (CIADA) to leverage prior knowledge of CI for robust performance in SSOA. Based on our benchmark, we conduct experiments on the robustness of state-of-the-art segmenters against aberrations. In addition, extensive evaluations of possible solutions to SSOA reveal that CIADA achieves superior performance under all aberration distributions, paving the way for the applications of MOS in semantic scene understanding. Code and dataset will be made publicly available at https://github.com/zju-jiangqi/CIADA.