 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZe Wang
Model-Agnostic Human Preference Inversion in Diffusion Models
Apr 01, 2024
Efficient text-to-image generation remains a challenging task due to the high computational costs associated with the multi-step sampling in diffusion models. Although distillation of pre-trained diffusion models has been successful in reducing sampling steps, low-step image generation often falls short in terms of quality. In this study, we propose a novel sampling design to achieve high-quality one-step image generation aligning with human preferences, particularly focusing on exploring the impact of the prior noise distribution. Our approach, Prompt Adaptive Human Preference Inversion (PAHI), optimizes the noise distributions for each prompt based on human preferences without the need for fine-tuning diffusion models. Our experiments showcase that the tailored noise distributions significantly improve image quality with only a marginal increase in computational cost. Our findings underscore the importance of noise optimization and pave the way for efficient and high-quality text-to-image synthesis.
CCDSReFormer: Traffic Flow Prediction with a Criss-Crossed Dual-Stream Enhanced Rectified Transformer Model
Mar 29, 2024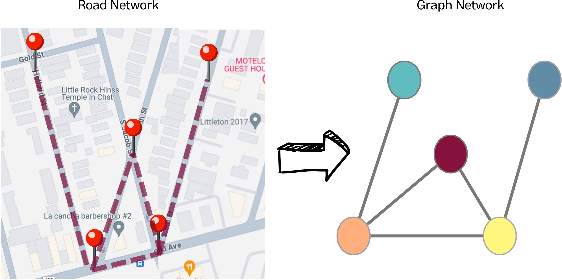
Accurate, and effective traffic forecasting is vital for smart traffic systems, crucial in urban traffic planning and management. Current Spatio-Temporal Transformer models, despite their prediction capabilities, struggle with balancing computational efficiency and accuracy, favoring global over local information, and handling spatial and temporal data separately, limiting insight into complex interactions. We introduce the Criss-Crossed Dual-Stream Enhanced Rectified Transformer model (CCDSReFormer), which includes three innovative modules: Enhanced Rectified Spatial Self-attention (ReSSA), Enhanced Rectified Delay Aware Self-attention (ReDASA), and Enhanced Rectified Temporal Self-attention (ReTSA). These modules aim to lower computational needs via sparse attention, focus on local information for better traffic dynamics understanding, and merge spatial and temporal insights through a unique learning method. Extensive tests on six real-world datasets highlight CCDSReFormer's superior performance. An ablation study also confirms the significant impact of each component on the model's predictive accuracy, showcasing our model's ability to forecast traffic flow effectively.
Deep Automated Mechanism Design for Integrating Ad Auction and Allocation in Feed
Jan 03, 2024E-commerce platforms usually present an ordered list, mixed with several organic items and an advertisement, in response to each user's page view request. This list, the outcome of ad auction and allocation processes, directly impacts the platform's ad revenue and gross merchandise volume (GMV). Specifically, the ad auction determines which ad is displayed and the corresponding payment, while the ad allocation decides the display positions of the advertisement and organic items. The prevalent methods of segregating the ad auction and allocation into two distinct stages face two problems: 1) Ad auction does not consider externalities, such as the influence of actual display position and context on ad Click-Through Rate (CTR); 2) The ad allocation, which utilizes the auction-winning ad's payment to determine the display position dynamically, fails to maintain incentive compatibility (IC) for the advertisement. For instance, in the auction stage employing the traditional Generalized Second Price (GSP) , even if the winning ad increases its bid, its payment remains unchanged. This implies that the advertisement cannot secure a better position and thus loses the opportunity to achieve higher utility in the subsequent ad allocation stage. Previous research often focused on one of the two stages, neglecting the two-stage problem, which may result in suboptimal outcomes...
Rethinking Human Pose Estimation for Autonomous Driving with 3D Event Representations
Nov 09, 2023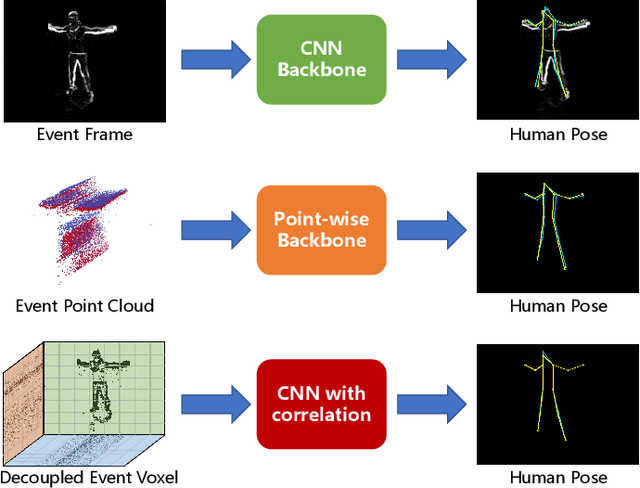
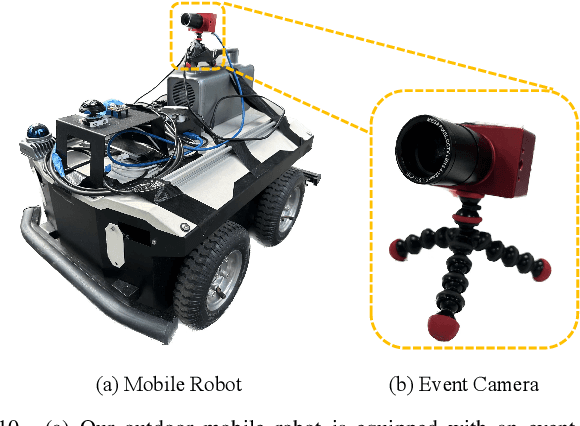
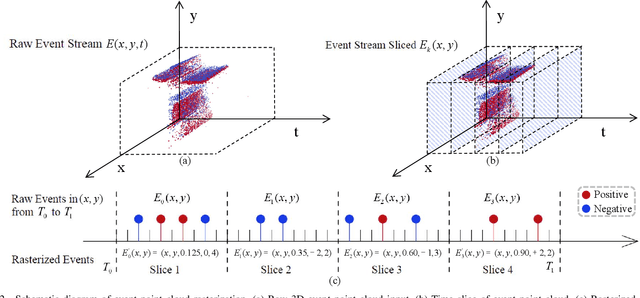
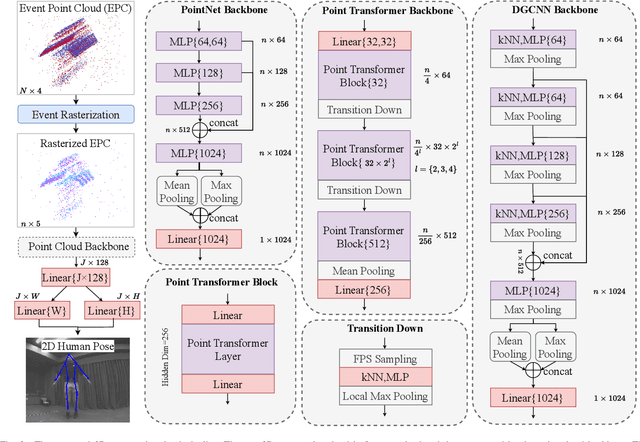
Human pose estimation is a critical component in autonomous driving and parking, enhancing safety by predicting human actions. Traditional frame-based cameras and videos are commonly applied, yet, they become less reliable in scenarios under high dynamic range or heavy motion blur. In contrast, event cameras offer a robust solution for navigating these challenging contexts. Predominant methodologies incorporate event cameras into learning frameworks by accumulating events into event frames. However, such methods tend to marginalize the intrinsic asynchronous and high temporal resolution characteristics of events. This disregard leads to a loss in essential temporal dimension data, crucial for safety-critical tasks associated with dynamic human activities. To address this issue and to unlock the 3D potential of event information, we introduce two 3D event representations: the Rasterized Event Point Cloud (RasEPC) and the Decoupled Event Voxel (DEV). The RasEPC collates events within concise temporal slices at identical positions, preserving 3D attributes with statistical cues and markedly mitigating memory and computational demands. Meanwhile, the DEV representation discretizes events into voxels and projects them across three orthogonal planes, utilizing decoupled event attention to retrieve 3D cues from the 2D planes. Furthermore, we develop and release EV-3DPW, a synthetic event-based dataset crafted to facilitate training and quantitative analysis in outdoor scenes. On the public real-world DHP19 dataset, our event point cloud technique excels in real-time mobile predictions, while the decoupled event voxel method achieves the highest accuracy. Experiments reveal our proposed 3D representation methods' superior generalization capacities against traditional RGB images and event frame techniques. Our code and dataset are available at https://github.com/MasterHow/EventPointPose.
FocusFlow: Boosting Key-Points Optical Flow Estimation for Autonomous Driving
Aug 14, 2023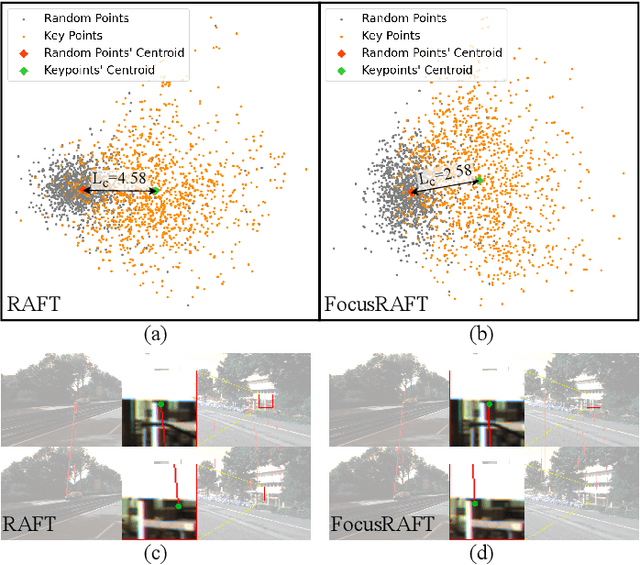
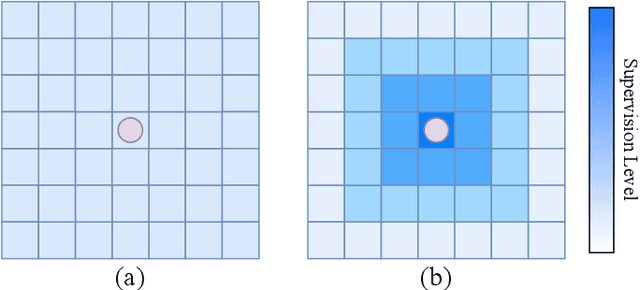
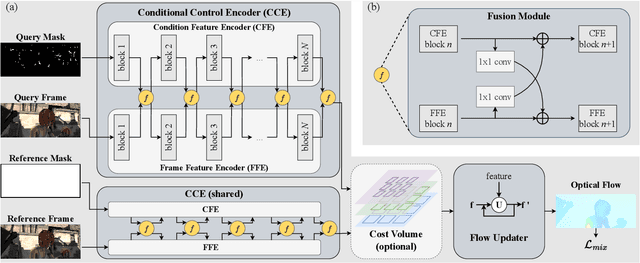
Key-point-based scene understanding is fundamental for autonomous driving applications. At the same time, optical flow plays an important role in many vision tasks. However, due to the implicit bias of equal attention on all points, classic data-driven optical flow estimation methods yield less satisfactory performance on key points, limiting their implementations in key-point-critical safety-relevant scenarios. To address these issues, we introduce a points-based modeling method that requires the model to learn key-point-related priors explicitly. Based on the modeling method, we present FocusFlow, a framework consisting of 1) a mix loss function combined with a classic photometric loss function and our proposed Conditional Point Control Loss (CPCL) function for diverse point-wise supervision; 2) a conditioned controlling model which substitutes the conventional feature encoder by our proposed Condition Control Encoder (CCE). CCE incorporates a Frame Feature Encoder (FFE) that extracts features from frames, a Condition Feature Encoder (CFE) that learns to control the feature extraction behavior of FFE from input masks containing information of key points, and fusion modules that transfer the controlling information between FFE and CFE. Our FocusFlow framework shows outstanding performance with up to +44.5% precision improvement on various key points such as ORB, SIFT, and even learning-based SiLK, along with exceptional scalability for most existing data-driven optical flow methods like PWC-Net, RAFT, and FlowFormer. Notably, FocusFlow yields competitive or superior performances rivaling the original models on the whole frame. The source code will be available at https://github.com/ZhonghuaYi/FocusFlow_official.
Tightly-Coupled LiDAR-Visual SLAM Based on Geometric Features for Mobile Agents
Jul 15, 2023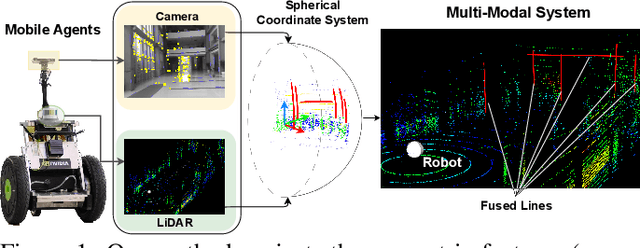
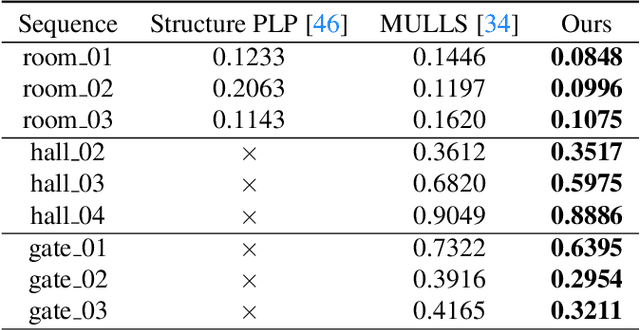
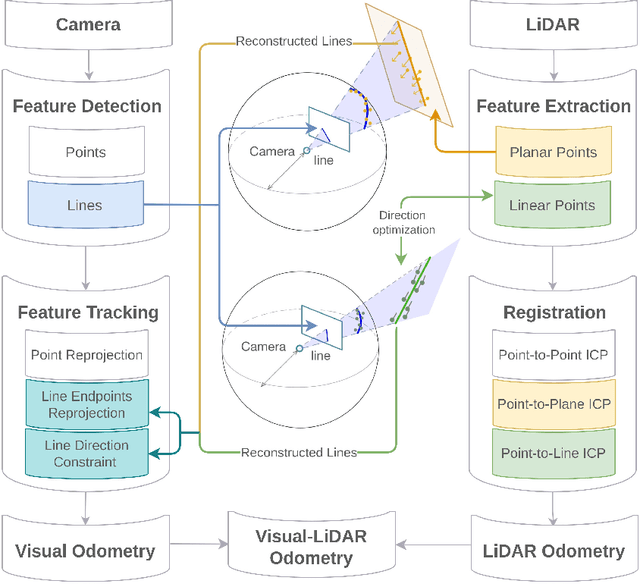

The mobile robot relies on SLAM (Simultaneous Localization and Mapping) to provide autonomous navigation and task execution in complex and unknown environments. However, it is hard to develop a dedicated algorithm for mobile robots due to dynamic and challenging situations, such as poor lighting conditions and motion blur. To tackle this issue, we propose a tightly-coupled LiDAR-visual SLAM based on geometric features, which includes two sub-systems (LiDAR and monocular visual SLAM) and a fusion framework. The fusion framework associates the depth and semantics of the multi-modal geometric features to complement the visual line landmarks and to add direction optimization in Bundle Adjustment (BA). This further constrains visual odometry. On the other hand, the entire line segment detected by the visual subsystem overcomes the limitation of the LiDAR subsystem, which can only perform the local calculation for geometric features. It adjusts the direction of linear feature points and filters out outliers, leading to a higher accurate odometry system. Finally, we employ a module to detect the subsystem's operation, providing the LiDAR subsystem's output as a complementary trajectory to our system while visual subsystem tracking fails. The evaluation results on the public dataset M2DGR, gathered from ground robots across various indoor and outdoor scenarios, show that our system achieves more accurate and robust pose estimation compared to current state-of-the-art multi-modal methods.
Close-up View synthesis by Interpolating Optical Flow
Jul 12, 2023
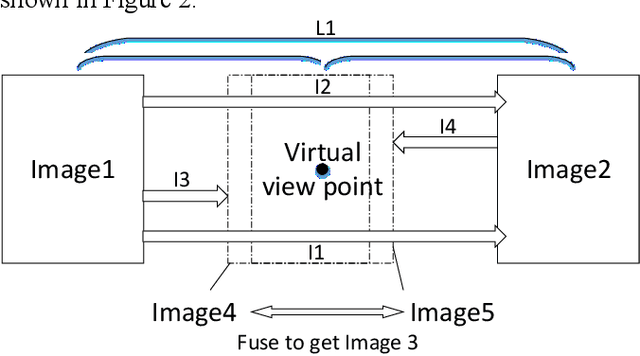
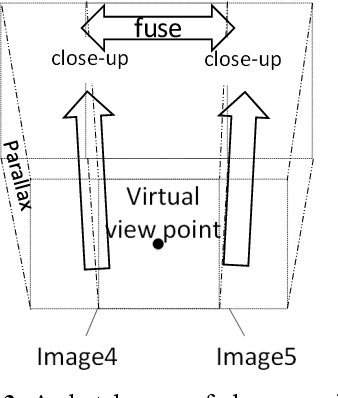

The virtual viewpoint is perceived as a new technique in virtual navigation, as yet not supported due to the lack of depth information and obscure camera parameters. In this paper, a method for achieving close-up virtual view is proposed and it only uses optical flow to build parallax effects to realize pseudo 3D projection without using depth sensor. We develop a bidirectional optical flow method to obtain any virtual viewpoint by proportional interpolation of optical flow. Moreover, with the ingenious application of the optical-flow-value, we achieve clear and visual-fidelity magnified results through lens stretching in any corner, which overcomes the visual distortion and image blur through viewpoint magnification and transition in Google Street View system.
Towards Anytime Optical Flow Estimation with Event Cameras
Jul 11, 2023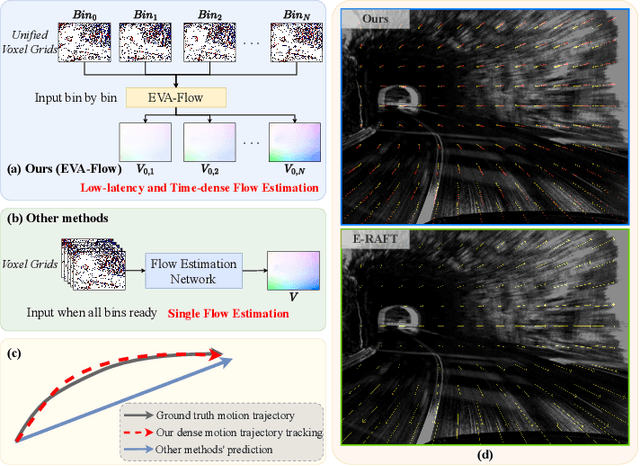
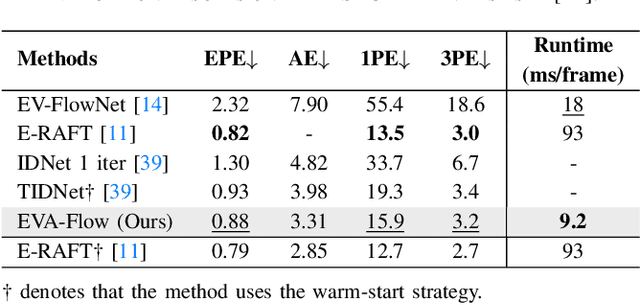
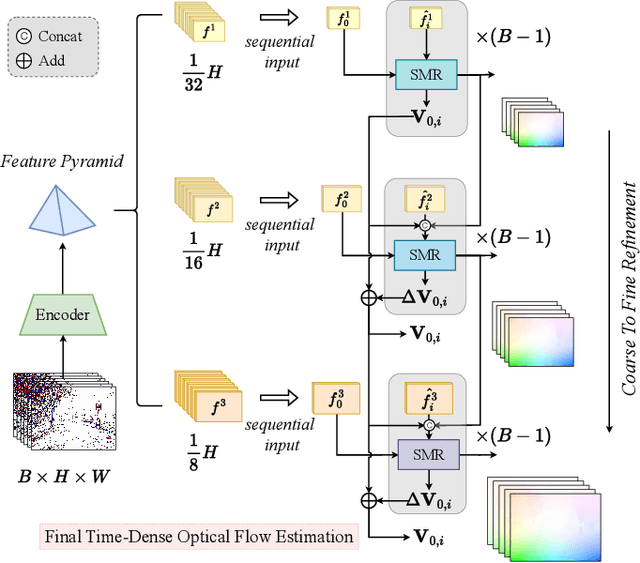
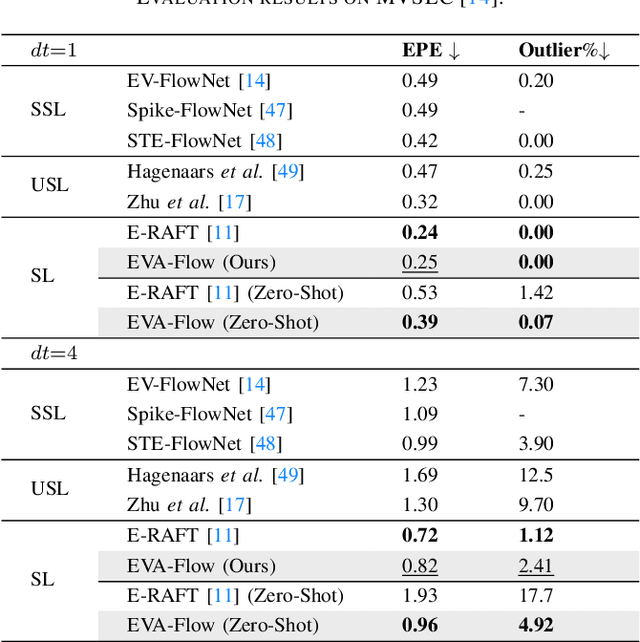
Event cameras are capable of responding to log-brightness changes in microseconds. Its characteristic of producing responses only to the changing region is particularly suitable for optical flow estimation. In contrast to the super low-latency response speed of event cameras, existing datasets collected via event cameras, however, only provide limited frame rate optical flow ground truth, (e.g., at 10Hz), greatly restricting the potential of event-driven optical flow. To address this challenge, we put forward a high-frame-rate, low-latency event representation Unified Voxel Grid, sequentially fed into the network bin by bin. We then propose EVA-Flow, an EVent-based Anytime Flow estimation network to produce high-frame-rate event optical flow with only low-frame-rate optical flow ground truth for supervision. The key component of our EVA-Flow is the stacked Spatiotemporal Motion Refinement (SMR) module, which predicts temporally-dense optical flow and enhances the accuracy via spatial-temporal motion refinement. The time-dense feature warping utilized in the SMR module provides implicit supervision for the intermediate optical flow. Additionally, we introduce the Rectified Flow Warp Loss (RFWL) for the unsupervised evaluation of intermediate optical flow in the absence of ground truth. This is, to the best of our knowledge, the first work focusing on anytime optical flow estimation via event cameras. A comprehensive variety of experiments on MVSEC, DESC, and our EVA-FlowSet demonstrates that EVA-Flow achieves competitive performance, super-low-latency (5ms), fastest inference (9.2ms), time-dense motion estimation (200Hz), and strong generalization. Our code will be available at https://github.com/Yaozhuwa/EVA-Flow.
LF-PGVIO: A Visual-Inertial-Odometry Framework for Large Field-of-View Cameras using Points and Geodesic Segments
Jun 11, 2023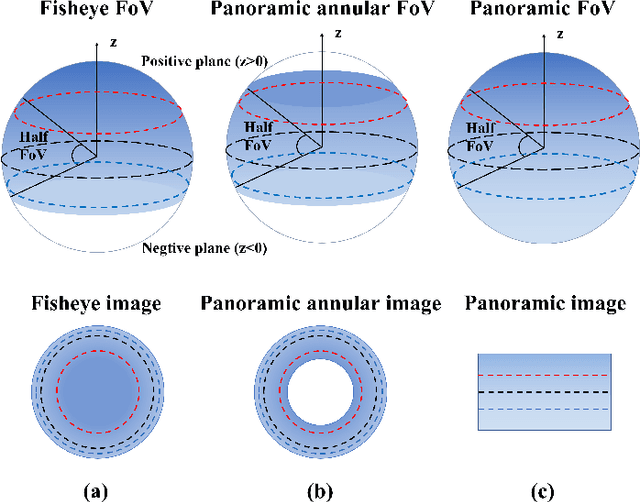
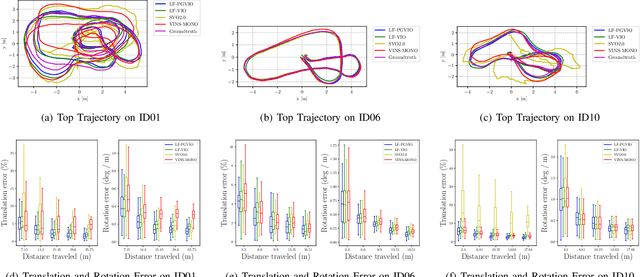
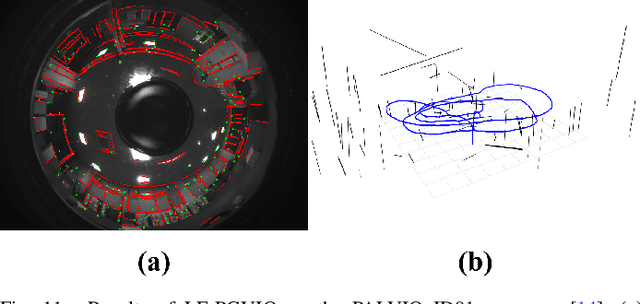
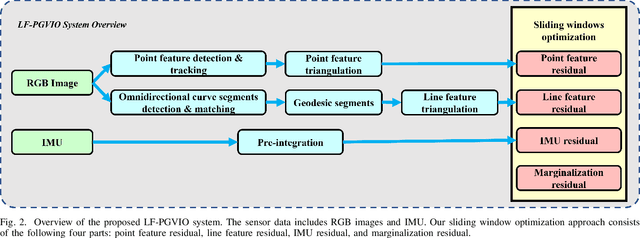
In this paper, we propose LF-PGVIO, a Visual-Inertial-Odometry (VIO) framework for large Field-of-View (FoV) cameras with a negative plane using points and geodesic segments. Notoriously, when the FoV of a panoramic camera reaches the negative half-plane, the image cannot be unfolded into a single pinhole image. Moreover, if a traditional straight-line detection method is directly applied to the original panoramic image, it cannot be normally used due to the large distortions in the panoramas and remains under-explored in the literature. To address these challenges, we put forward LF-PGVIO, which can provide line constraints for cameras with large FoV, even for cameras with negative-plane FoV, and directly extract omnidirectional curve segments from the raw omnidirectional image. We propose an Omnidirectional Curve Segment Detection (OCSD) method combined with a camera model which is applicable to images with large distortions, such as panoramic annular images, fisheye images, and various panoramic images. Each point on the image is projected onto the sphere, and the detected omnidirectional curve segments in the image named geodesic segments must satisfy the criterion of being a geodesic segment on the unit sphere. The detected geodesic segment is sliced into multiple straight-line segments according to the radian of the geodesic, and descriptors are extracted separately and recombined to obtain new descriptors. Based on descriptor matching, we obtain the constraint relationship of the 3D line segments between multiple frames. In our VIO system, we use sliding window optimization using point feature residuals, line feature residuals, and IMU residuals. Our evaluation of the proposed system on public datasets demonstrates that LF-PGVIO outperforms state-of-the-art methods in terms of accuracy and robustness. Code will be open-sourced at https://github.com/flysoaryun/LF-PGVIO.
MDDL: A Framework for Reinforcement Learning-based Position Allocation in Multi-Channel Feed
Apr 17, 2023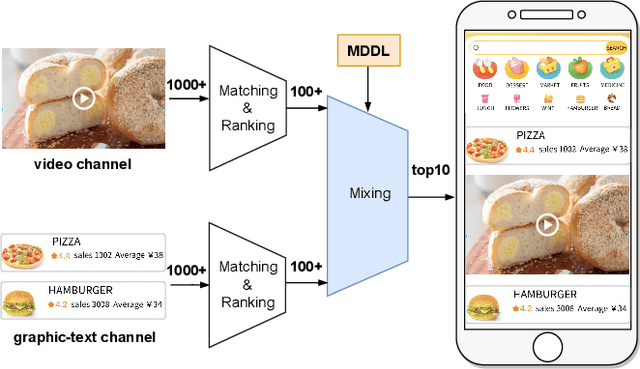

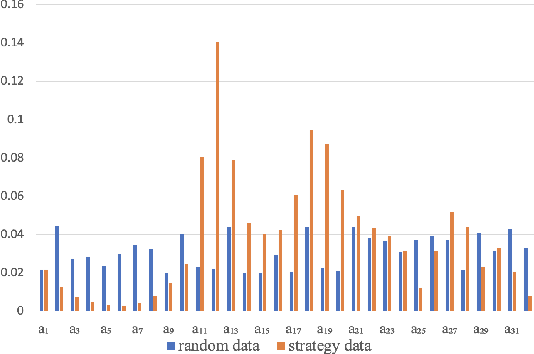
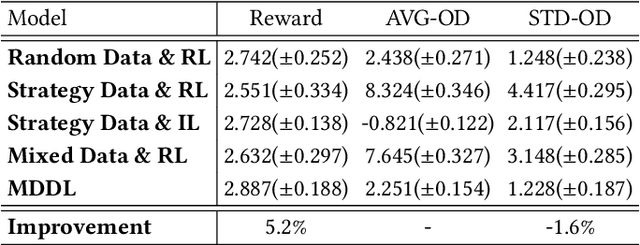
Nowadays, the mainstream approach in position allocation system is to utilize a reinforcement learning model to allocate appropriate locations for items in various channels and then mix them into the feed. There are two types of data employed to train reinforcement learning (RL) model for position allocation, named strategy data and random data. Strategy data is collected from the current online model, it suffers from an imbalanced distribution of state-action pairs, resulting in severe overestimation problems during training. On the other hand, random data offers a more uniform distribution of state-action pairs, but is challenging to obtain in industrial scenarios as it could negatively impact platform revenue and user experience due to random exploration. As the two types of data have different distributions, designing an effective strategy to leverage both types of data to enhance the efficacy of the RL model training has become a highly challenging problem. In this study, we propose a framework named Multi-Distribution Data Learning (MDDL) to address the challenge of effectively utilizing both strategy and random data for training RL models on mixed multi-distribution data. Specifically, MDDL incorporates a novel imitation learning signal to mitigate overestimation problems in strategy data and maximizes the RL signal for random data to facilitate effective learning. In our experiments, we evaluated the proposed MDDL framework in a real-world position allocation system and demonstrated its superior performance compared to the previous baseline. MDDL has been fully deployed on the Meituan food delivery platform and currently serves over 300 million users.