 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRong Xiao
Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Feb 19, 2024
This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose \textbf{S}mart \textbf{P}arallel \textbf{A}uto-\textbf{C}orrect d\textbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
BiTA: Bi-Directional Tuning for Lossless Acceleration in Large Language Models
Jan 25, 2024Large language models (LLMs) commonly employ autoregressive generation during inference, leading to high memory bandwidth demand and consequently extended latency. To mitigate this inefficiency, we present Bi-directional Tuning for lossless Acceleration (BiTA), an innovative method expediting LLMs via streamlined semi-autoregressive generation and draft verification. Inspired by the concept of prompt tuning, we enhance LLMs with a parameter-efficient design called bi-directional tuning for the capability in semi-autoregressive generation. Employing efficient tree-based decoding, the models perform draft candidate generation and verification in parallel, ensuring outputs identical to their autoregressive counterparts under greedy sampling. BiTA serves as a lightweight plug-in module, seamlessly boosting the inference efficiency of existing LLMs without requiring additional assistance models or incurring significant extra memory costs. Applying the proposed BiTA, LLaMA-2-70B-Chat achieves a 2.7$\times$ speedup on the MT-Bench benchmark. Extensive experiments confirm our method surpasses state-of-the-art acceleration techniques.
Using Global Land Cover Product as Prompt for Cropland Mapping via Visual Foundation Model
Oct 16, 2023Data-driven deep learning methods have shown great potential in cropland mapping. However, due to multiple factors such as attributes of cropland (topography, climate, crop type) and imaging conditions (viewing angle, illumination, scale), croplands under different scenes demonstrate a great domain gap. This makes it difficult for models trained in the specific scenes to directly generalize to other scenes. A common way to handle this problem is through the "Pretrain+Fine-tuning" paradigm. Unfortunately, considering the variety of features of cropland that are affected by multiple factors, it is hardly to handle the complex domain gap between pre-trained data and target data using only sparse fine-tuned samples as general constraints. Moreover, as the number of model parameters grows, fine-tuning is no longer an easy and low-cost task. With the emergence of prompt learning via visual foundation models, the "Pretrain+Prompting" paradigm redesigns the optimization target by introducing individual prompts for each single sample. This simplifies the domain adaption from generic to specific scenes during model reasoning processes. Therefore, we introduce the "Pretrain+Prompting" paradigm to interpreting cropland scenes and design the auto-prompting (APT) method based on freely available global land cover product. It can achieve a fine-grained adaptation process from generic scenes to specialized cropland scenes without introducing additional label costs. To our best knowledge, this work pioneers the exploration of the domain adaption problems for cropland mapping under prompt learning perspectives. Our experiments using two sub-meter cropland datasets from southern and northern China demonstrated that the proposed method via visual foundation models outperforms traditional supervised learning and fine-tuning approaches in the field of remote sensing.
Improving Text Matching in E-Commerce Search with A Rationalizable, Intervenable and Fast Entity-Based Relevance Model
Jul 01, 2023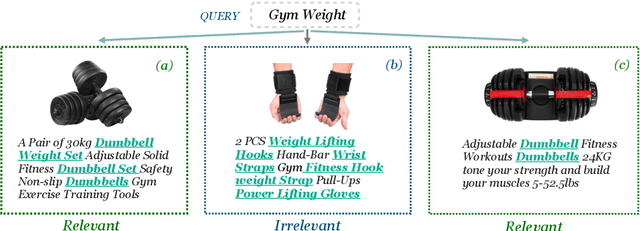

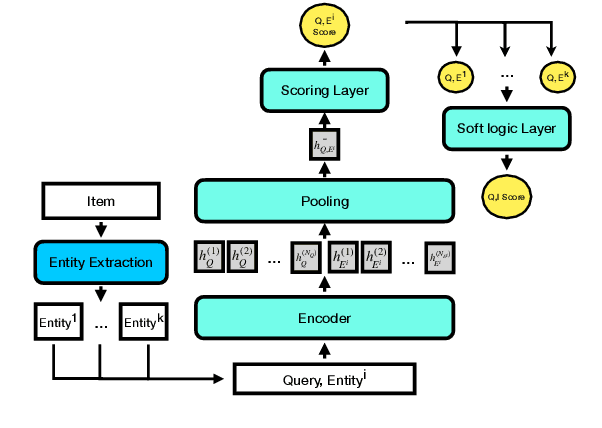
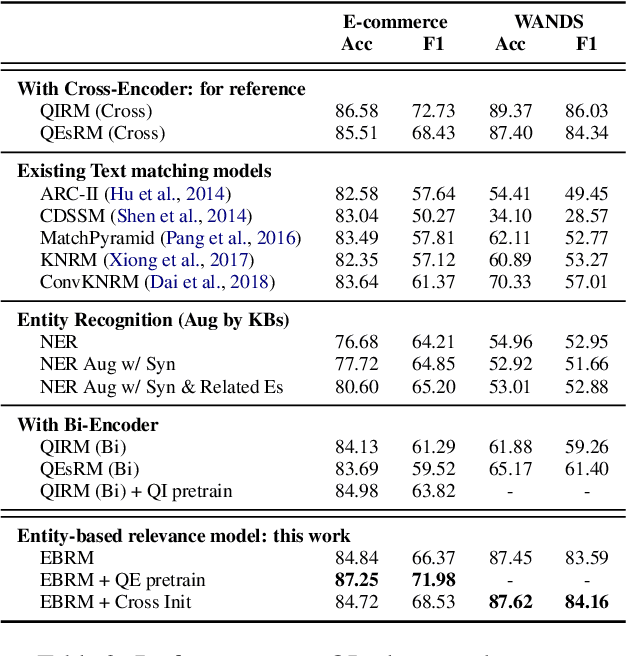
Discovering the intended items of user queries from a massive repository of items is one of the main goals of an e-commerce search system. Relevance prediction is essential to the search system since it helps improve performance. When online serving a relevance model, the model is required to perform fast and accurate inference. Currently, the widely used models such as Bi-encoder and Cross-encoder have their limitations in accuracy or inference speed respectively. In this work, we propose a novel model called the Entity-Based Relevance Model (EBRM). We identify the entities contained in an item and decompose the QI (query-item) relevance problem into multiple QE (query-entity) relevance problems; we then aggregate their results to form the QI prediction using a soft logic formulation. The decomposition allows us to use a Cross-encoder QE relevance module for high accuracy as well as cache QE predictions for fast online inference. Utilizing soft logic makes the prediction procedure interpretable and intervenable. We also show that pretraining the QE module with auto-generated QE data from user logs can further improve the overall performance. The proposed method is evaluated on labeled data from e-commerce websites. Empirical results show that it achieves promising improvements with computation efficiency.
NAR-Former V2: Rethinking Transformer for Universal Neural Network Representation Learning
Jun 19, 2023
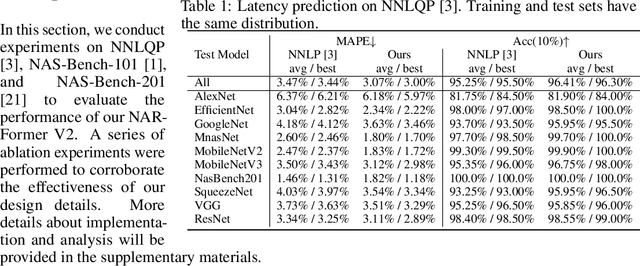
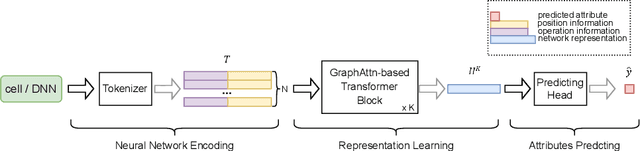
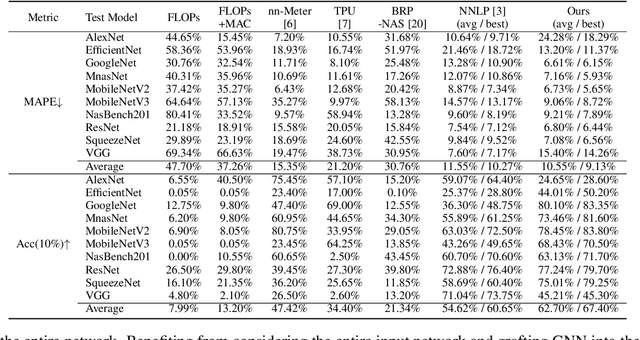
As more deep learning models are being applied in real-world applications, there is a growing need for modeling and learning the representations of neural networks themselves. An efficient representation can be used to predict target attributes of networks without the need for actual training and deployment procedures, facilitating efficient network deployment and design. Recently, inspired by the success of Transformer, some Transformer-based representation learning frameworks have been proposed and achieved promising performance in handling cell-structured models. However, graph neural network (GNN) based approaches still dominate the field of learning representation for the entire network. In this paper, we revisit Transformer and compare it with GNN to analyse their different architecture characteristics. We then propose a modified Transformer-based universal neural network representation learning model NAR-Former V2. It can learn efficient representations from both cell-structured networks and entire networks. Specifically, we first take the network as a graph and design a straightforward tokenizer to encode the network into a sequence. Then, we incorporate the inductive representation learning capability of GNN into Transformer, enabling Transformer to generalize better when encountering unseen architecture. Additionally, we introduce a series of simple yet effective modifications to enhance the ability of the Transformer in learning representation from graph structures. Our proposed method surpasses the GNN-based method NNLP by a significant margin in latency estimation on the NNLQP dataset. Furthermore, regarding accuracy prediction on the NASBench101 and NASBench201 datasets, our method achieves highly comparable performance to other state-of-the-art methods.
Continual Transfer Learning for Cross-Domain Click-Through Rate Prediction at Taobao
Aug 11, 2022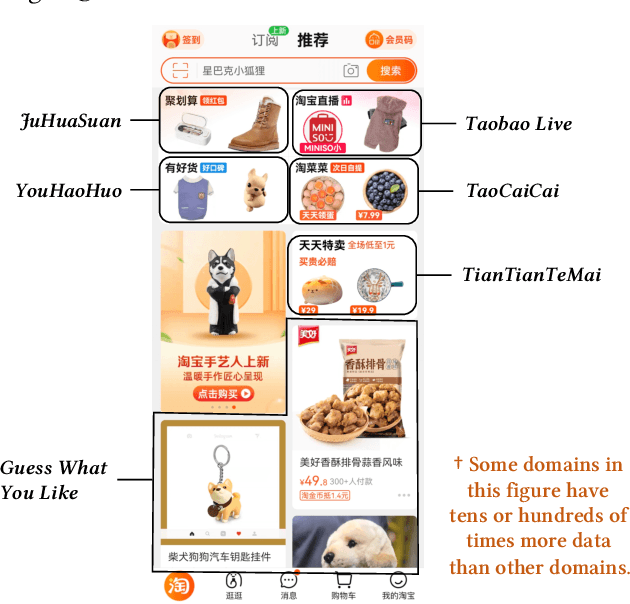

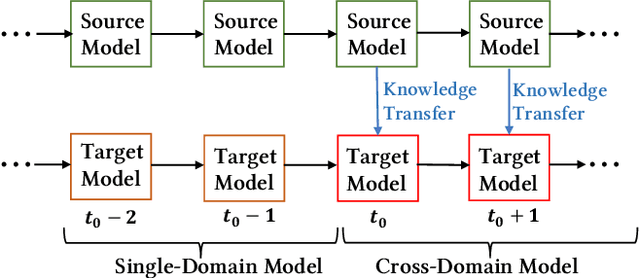
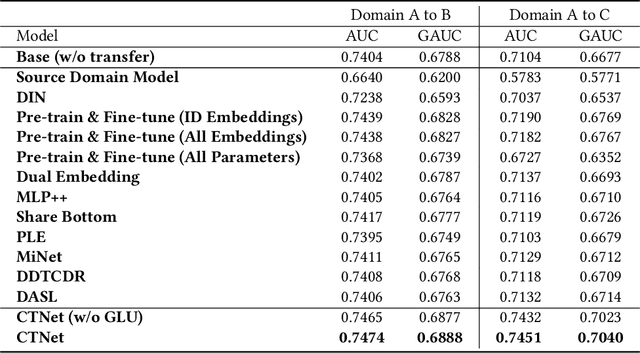
As one of the largest e-commerce platforms in the world, Taobao's recommendation systems (RSs) serve the demands of shopping for hundreds of millions of customers. Click-Through Rate (CTR) prediction is a core component of the RS. One of the biggest characteristics in CTR prediction at Taobao is that there exist multiple recommendation domains where the scales of different domains vary significantly. Therefore, it is crucial to perform cross-domain CTR prediction to transfer knowledge from large domains to small domains to alleviate the data sparsity issue. However, existing cross-domain CTR prediction methods are proposed for static knowledge transfer, ignoring that all domains in real-world RSs are continually time-evolving. In light of this, we present a necessary but novel task named Continual Transfer Learning (CTL), which transfers knowledge from a time-evolving source domain to a time-evolving target domain. In this work, we propose a simple and effective CTL model called CTNet to solve the problem of continual cross-domain CTR prediction at Taobao, and CTNet can be trained efficiently. Particularly, CTNet considers an important characteristic in the industry that models has been continually well-trained for a very long time. So CTNet aims to fully utilize all the well-trained model parameters in both source domain and target domain to avoid losing historically acquired knowledge, and only needs incremental target domain data for training to guarantee efficiency. Extensive offline experiments and online A/B testing at Taobao demonstrate the efficiency and effectiveness of CTNet. CTNet is now deployed online in the recommender systems of Taobao, serving the main traffic of hundreds of millions of active users.
Attention Mechanism with Energy-Friendly Operations
Apr 28, 2022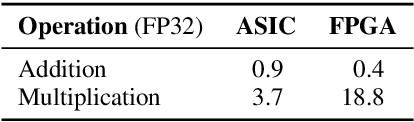
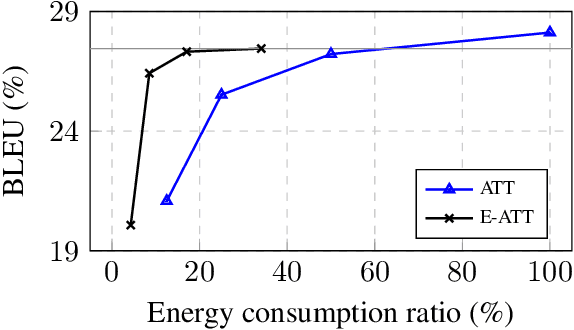

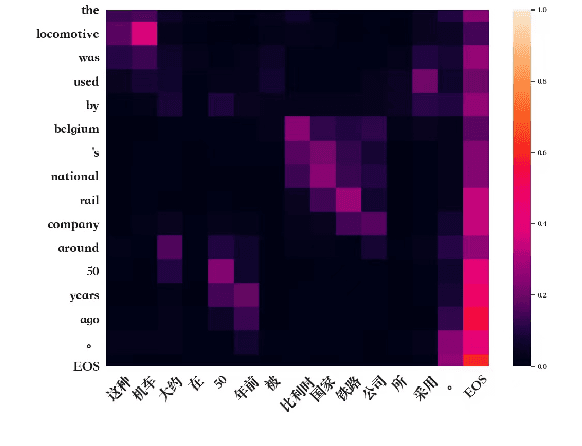
Attention mechanism has become the dominant module in natural language processing models. It is computationally intensive and depends on massive power-hungry multiplications. In this paper, we rethink variants of attention mechanism from the energy consumption aspects. After reaching the conclusion that the energy costs of several energy-friendly operations are far less than their multiplication counterparts, we build a novel attention model by replacing multiplications with either selective operations or additions. Empirical results on three machine translation tasks demonstrate that the proposed model, against the vanilla one, achieves competitable accuracy while saving 99\% and 66\% energy during alignment calculation and the whole attention procedure. Code is available at: https://github.com/NLP2CT/E-Att.
1st Place Solution for ICDAR 2021 Competition on Mathematical Formula Detection
Jul 12, 2021
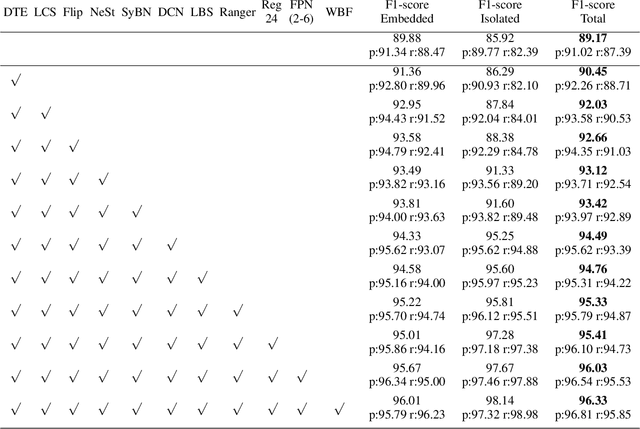
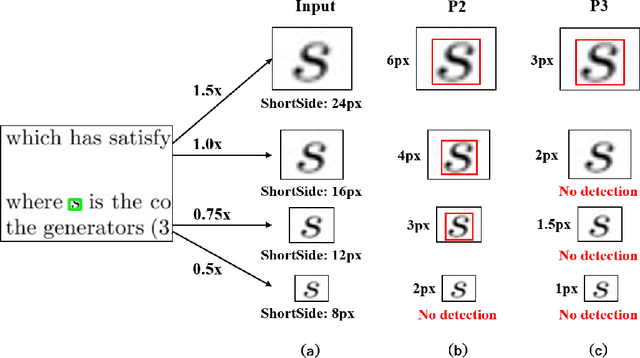
In this technical report, we present our 1st place solution for the ICDAR 2021 competition on mathematical formula detection (MFD). The MFD task has three key challenges including a large scale span, large variation of the ratio between height and width, and rich character set and mathematical expressions. Considering these challenges, we used Generalized Focal Loss (GFL), an anchor-free method, instead of the anchor-based method, and prove the Adaptive Training Sampling Strategy (ATSS) and proper Feature Pyramid Network (FPN) can well solve the important issue of scale variation. Meanwhile, we also found some tricks, e.g., Deformable Convolution Network (DCN), SyncBN, and Weighted Box Fusion (WBF), were effective in MFD task. Our proposed method ranked 1st in the final 15 teams.
SGPT: Semantic Graphs based Pre-training for Aspect-based Sentiment Analysis
May 26, 2021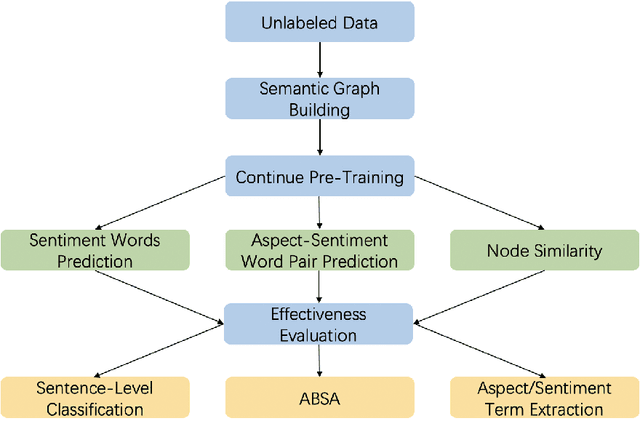
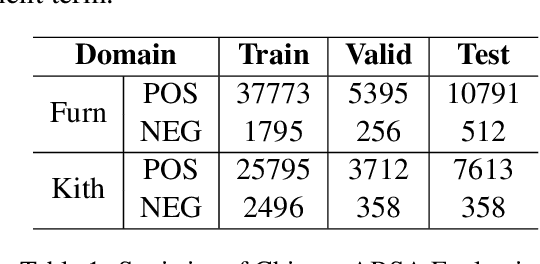
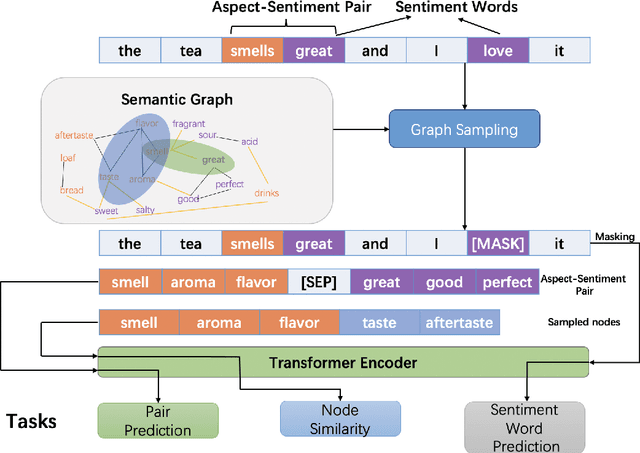
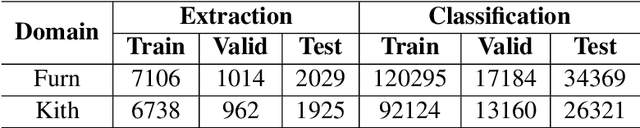
Previous studies show effective of pre-trained language models for sentiment analysis. However, most of these studies ignore the importance of sentimental information for pre-trained models.Therefore, we fully investigate the sentimental information for pre-trained models and enhance pre-trained language models with semantic graphs for sentiment analysis.In particular, we introduce Semantic Graphs based Pre-training(SGPT) using semantic graphs to obtain synonym knowledge for aspect-sentiment pairs and similar aspect/sentiment terms.We then optimize the pre-trained language model with the semantic graphs.Empirical studies on several downstream tasks show that proposed model outperforms strong pre-trained baselines. The results also show the effectiveness of proposed semantic graphs for pre-trained model.
Path-based Deep Network for Candidate Item Matching in Recommenders
May 18, 2021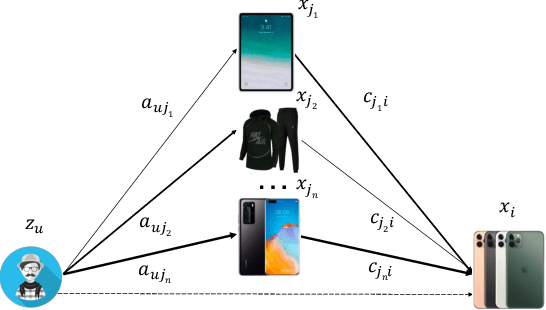
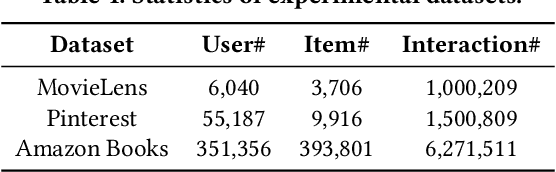

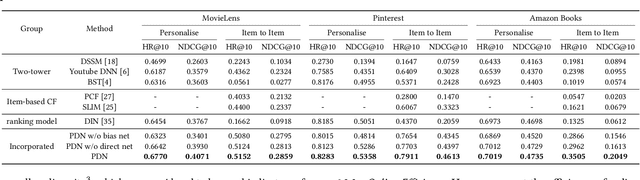
The large-scale recommender system mainly consists of two stages: matching and ranking. The matching stage (also known as the retrieval step) identifies a small fraction of relevant items from billion-scale item corpus in low latency and computational cost. Item-to-item collaborative filter (item-based CF) and embedding-based retrieval (EBR) have been long used in the industrial matching stage owing to its efficiency. However, item-based CF is hard to meet personalization, while EBR has difficulty in satisfying diversity. In this paper, we propose a novel matching architecture, Path-based Deep Network (named PDN), which can incorporate both personalization and diversity to enhance matching performance. Specifically, PDN is comprised of two modules: Trigger Net and Similarity Net. PDN utilizes Trigger Net to capture the user's interest in each of his/her interacted item, and Similarity Net to evaluate the similarity between each interacted item and the target item based on these items' profile and CF information. The final relevance between the user and the target item is calculated by explicitly considering user's diverse interests, \ie aggregating the relevance weights of the related two-hop paths (one hop of a path corresponds to user-item interaction and the other to item-item relevance). Furthermore, we describe the architecture design of a matching system with the proposed PDN in a leading real-world E-Commerce service (Mobile Taobao App). Based on offline evaluations and online A/B test, we show that PDN outperforms the existing solutions for the same task. The online results also demonstrate that PDN can retrieve more personalized and more diverse relevant items to significantly improve user engagement. Currently, PDN system has been successfully deployed at Mobile Taobao App and handling major online traffic.